【项目实训#04】GitHub ArkTS项目代码爬取学习
通过本次项目实践,我不仅掌握了网络爬虫的开发技术,还学习了如何设计和实现一个完整的软件系统。在项目过程中,我遇到了各种技术难题,通过查阅资料和不断尝试,最终都得到了解决。这次经历让我深刻认识到,软件开发不仅需要扎实的编程基础,还需要良好的问题解决能力和工程实践经验。
【项目实训#04】GitHub ArkTS项目代码爬取学习
文章目录
一、背景简介
在本次HarmonyOS平台的开发过程中,我们需要收集和分析大量的开源代码。然而,由于GitHub的搜索结果数量庞大,手动收集和筛选代码库非常耗时耗力。为了解决这个问题,我们需要开发一款自动化的GitHub代码爬虫工具,用于自动化收集、筛选和统计GitHub上的ArkTS相关代码库。
本次实践的主要目标是:
- 自动化爬取GitHub上与ArkTS相关的代码仓库
- 对爬取的代码进行筛选,保留有价值的源代码文件
- 统计代码行数,为后续分析提供基础数据
二、技术方案与实现
2.1 整体架构
采用Python作为主要开发语言,使用Selenium进行网页爬取,BeautifulSoup进行HTML解析,Git进行代码仓库克隆。整体架构包括三个主要模块:
- GitHub爬虫模块:负责从GitHub搜索页面爬取ArkTS相关仓库信息
- 文件筛选模块:负责筛选有价值的源代码文件
- 代码统计模块:负责统计代码行数
2.2 GitHub爬虫模块实现
GitHub爬虫模块主要通过github_crawler_v01.py实现,核心功能包括:
- 初始化WebDriver:配置Chrome浏览器的无头模式,随机选择User-Agent防止被反爬
def init_driver():
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式
options.add_argument('--no-sandbox')
# 随机选择一个User-Agent
options.add_argument(f'user-agent={random.choice(USER_AGENTS)}')
service_path = Service("../../../chrome/chromedriver-win64/chromedriver.exe")
driver = webdriver.Chrome(service=service_path, options=options)
return driver
- 提取仓库信息:解析GitHub搜索结果页面,提取仓库名称和克隆URL
def extract_repo_info(driver, page_num):
"""解析页面提取仓库信息"""
element_file = f'../html_pages/element_content_{page_num}.txt'
# 检查是否已经存在element_content_{page_num}.txt文件
if os.path.exists(element_file):
print(f"已存在element_content_{page_num}.txt,直接读取")
with open(element_file, 'r', encoding='utf-8') as f:
outer_html = f.read()
else:
# 如果文件不存在,使用driver爬取并保存内容
current_url = f"{BASE_URL}&p={page_num}"
print(f"爬取网页{current_url}搜索列表元素,并保存到{element_file}")
driver.get(current_url)
WebDriverWait(driver, 15)
root_element = driver.find_element(By.CSS_SELECTOR, 'div.gZKkEq')
with open(element_file, 'w', encoding='utf-8') as f:
outer_html = root_element.get_attribute('outerHTML')
f.write(outer_html)
# 解析outerHTML内容
soup = BeautifulSoup(outer_html, 'html.parser')
# 提取当前层级有效链接
repo_elements = soup.select("h3.cvnppv div.search-title span.search-match")
repos = [] # 用于存储提取的仓库信息
for repo_element in repo_elements:
repo_path = repo_element.text
clone_url = f"https://github.com/{repo_path}.git"
repos.append((repo_path, clone_url))
return repos
- 克隆仓库:使用Git命令克隆仓库到本地
def clone_repository(repo_name, clone_url):
"""执行Git克隆操作"""
target_dir = os.path.join(CLONE_DIR, repo_name.replace('/', '__'))
# 检查目标文件夹是否已经存在
if os.path.exists(target_dir):
print(f"⏩ 文件夹已存在: {repo_name},跳过克隆")
return False
try:
cmd = f"git clone {clone_url} {target_dir}"
subprocess.run(cmd, shell=True, check=True)
print(f"✅ 成功克隆: {repo_name}")
return True
except subprocess.CalledProcessError:
print(f"❌ 克隆失败: {repo_name}")
return False
2.3 文件筛选模块实现
文件筛选模块通过file_filter_v01.py实现,主要功能是筛选有价值的源代码文件,删除非源代码文件:
# 删除非源代码文件
for root, dirs, files in os.walk(repo_path):
for file in files:
file_path = os.path.join(root, file)
if not file.endswith(
('.c', '.cpp', '.h', '.hpp', # C/C++ 系列
'.py', '.java', '.js', # 脚本语言
'.html', '.css', '.xml', '.json', # 前端/配置
'.md', # 文档
'.ets', '.ts', '.d.ts', # ArkTS/TypeScript
'.json5', '.yml', '.yaml', # 配置文件
'.gradle', '.kts', # 构建脚本
'.strings', '.hsp', # 资源文件
'.test.ets', '.spec.ets') # 测试文件
):
os.remove(file_path)
print(f"🗑️ 删除非源代码文件: {file_path}")
2.4 代码统计模块实现
代码统计模块通过file_line_count.py实现,主要功能是统计指定目录下的代码总行数:
if extensions is None:
extensions = ['.c', '.cpp', '.h', '.hpp', # C/C++ 系列
'.py', '.java', '.js', # 脚本语言
'.html', '.css', '.xml', '.json', # 前端/配置
'.md', # 文档
'.ets', '.ts', '.d.ts', # ArkTS/TypeScript
'.json5', '.yml', '.yaml', # 配置文件
'.gradle', '.kts', # 构建脚本
'.strings', '.hsp', # 资源文件
'.test.ets', '.spec.ets' # 测试文件
]
if exclude_dirs is None:
exclude_dirs = ['.git', 'node_modules', 'venv', '__pycache__']
total_lines = 0
file_count = 0
for root, dirs, files in os.walk(root_dir):
# 排除指定目录
dirs[:] = [d for d in dirs if d not in exclude_dirs]
for file in files:
file_path = os.path.join(root, file)
# 过滤扩展名
if os.path.splitext(file)[1].lower() in extensions:
try:
with open(file_path, 'r', encoding='utf-8') as f:
lines = sum(1 for line in f)
total_lines += lines
file_count += 1
if verbose:
print(f"📄 {file_path} → {lines}行")
except UnicodeDecodeError:
if verbose:
print(f"⚠️ 跳过非文本文件:{file_path}")
except Exception as e:
if verbose:
print(f"❌ 无法读取 {file_path}: {str(e)}")
三、技术难点与解决方案
3.1 反爬虫机制应对
GitHub网站有一定的反爬虫机制,为了避免被封IP,我采取了以下措施:
- 随机User-Agent:每次请求随机选择不同的User-Agent
- 无头浏览器:使用Chrome的无头模式进行爬取,减少资源消耗
- 本地缓存:将爬取的HTML内容保存到本地,避免重复爬取
3.2 大量仓库克隆管理
为了有效管理大量仓库的克隆过程,我实现了断点续传功能:
def clone_repo_from_json(json_file):
"""
从JSON文件读取仓库信息并进行克隆,支持断点续传
:param json_file: 包含仓库信息的JSON文件路径
"""
# 检查是否已存在已克隆仓库记录文件
cloned_file = os.path.join(CLONE_DIR, '_cloned_repos.txt')
cloned_repos = set()
if os.path.exists(cloned_file):
with open(cloned_file, 'r', encoding='utf-8') as f:
cloned_repos = set(line.strip() for line in f)
try:
with open(json_file, 'r', encoding='utf-8') as f:
repos_data = json.load(f)
for repo_info in repos_data:
repo_name = repo_info['repo_name']
clone_url = repo_info['clone_url']
# 如果已经克隆过,则跳过
if repo_name in cloned_repos:
print(f"⏩ 已克隆过: {repo_name},跳过")
continue
# 尝试克隆,如果成功则记录到cloned_file
if clone_repository(repo_name, clone_url):
with open(cloned_file, 'a', encoding='utf-8') as f:
f.write(f"{repo_name}\n")
except Exception as e:
print(f"⛔ 从JSON克隆仓库失败: {str(e)}")
四、项目成果与收获
4.1 项目成果
- 成功爬取了GitHub上35页与ArkTS相关的仓库信息,共计数百个仓库
- 实现了自动化的代码筛选和统计功能
- 为后续的代码分析和学习提供了丰富的数据源
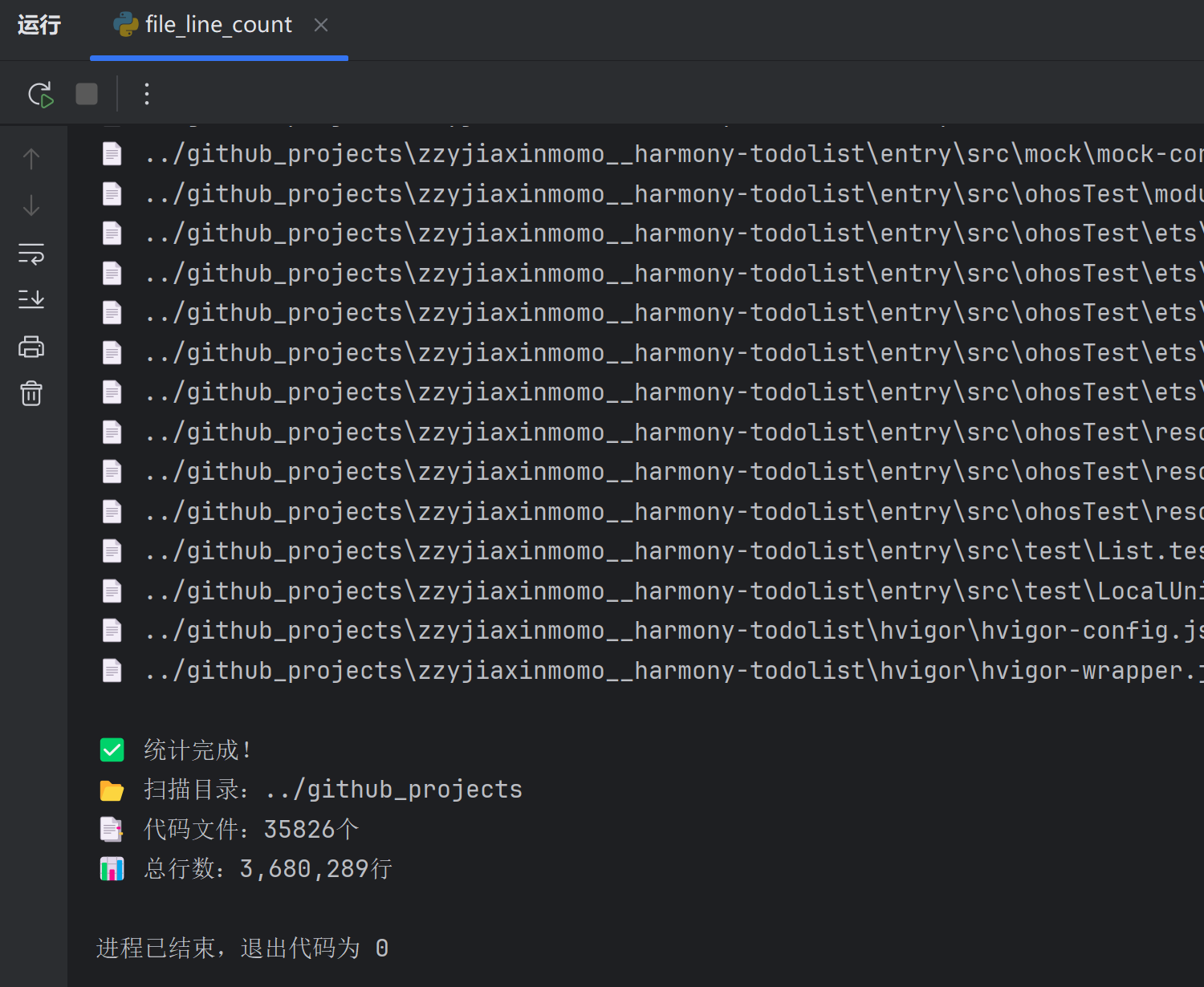
- 其中从GitHub上爬取的项目代码文件就有35,826个,共计3,680,289行
4.2 个人收获
-
技术能力提升:
- 深入学习了Selenium和BeautifulSoup的使用
- 掌握了Python处理文件和目录的高级技巧
- 提高了异常处理和日志记录的能力
-
工程实践经验:
- 学会了如何设计和实现一个完整的爬虫系统
- 掌握了大规模数据处理的方法和技巧
- 提高了代码组织和模块化设计的能力
-
问题解决能力:
- 学会了如何应对网站的反爬虫机制
- 掌握了断点续传等容错机制的实现方法
- 提高了调试和问题定位的能力
五、总结
通过本次项目实践,我不仅掌握了网络爬虫的开发技术,还学习了如何设计和实现一个完整的软件系统。在项目过程中,我遇到了各种技术难题,通过查阅资料和不断尝试,最终都得到了解决。这次经历让我深刻认识到,软件开发不仅需要扎实的编程基础,还需要良好的问题解决能力和工程实践经验。

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐



 19
19 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)