PC三方应用性能优化指导
1. 性能问题分析方法
1.1 什么是trace
HarmonyOS提供了为应用框架以及系统底座核心模块的性能打点能力,每一处打点即是一个Trace,其上附带了记录执行时间、运行时格式化数据、进程或线程信息等。Trace的详细含义及底层原理见常用Trace使用指导。
1.2 怎么去抓trace
开发者可以使用SmartPerf对Trace进行解析,在其绘制的泳道图中,对应用运行过程中的性能热点进行分析,得出优化方案。
如果受到网络状况的限制,也可以在如下链接下载Zip包进行安装,相当于单机版SmartPerf外部用户推荐使用SmartPerf Zip。
打开Smartperf之后,左侧工具栏说明:
- Open trace file:导入离线 trace 文件入口。
- Open long trace file:导入大文件入口。
- Record new trace:抓取新的 trace 文件入口。
- Record template:抓取指定模块的 trace 文件入口。
抓取trace参数说明:
序号
参数名称
含义
1
Record setting
设置trace的抓取模式,buffer size大小,抓取时长
2
Trace command
生成的抓取命令行
3
Probes config
trace的抓取参数配置
4
Native Memory
Native Memory数据的抓取参数配置
5
Hiperf
Hiperf数据的抓取参数配置
6
eBPF Config
eBPF数据的抓取参数配置
7
VM Tracker
smaps数据的抓取参数配置
8
HiSystemEvent
HiSystemEvent数据抓取参数配置
9
SDK Config
SDK数据抓取参数配置
以下是涉及比较多的参数模块
在Record setting中可以设置抓取trace的参数,可以设置buffer size大小,抓取时长等基本信息。

在probes config中可以设置抓取的OS的模块:

在hiperf中火焰图的开关一定要打开,在三方应用性能分析中非常必要:

在trace command中会生成对应的trace抓取的命令:

1.2.3 执行抓取命令
可以有两种方法执行命令,二选一即可。
1.2.3.1 在主机通过cmd命令执行
首先执行hdc shell,然后执行抓取trace的命令。
命令参数说明:
序号
名称
含义
1
-o
文件的输入路径和名称
2
-t
抓取的时长
3
buffer pages
buffer size大小
4
sample_duration
数据采集的时间
5
sample_interval
主动获取插件数据的间隔时间(ms,只针对轮询插件,例如memory插件,cpu插件,dikio插件等,对流式插件和独立插件无效)
6
trace_period_ms
ftrace插件读取内核缓冲区数据的间隔时间(ms)
1.2.3.2 通过脚本执行命令(推荐)
在主机上使用脚本工具,执行抓取传输文件和trace抓取的命令,简洁方便。


将执行得到的trace结果保存到当前文件夹内:

执行成功,生成trace文件。

1.3 trace分析
可以直接将trace文件拖拽至窗口处,即可完成数据加载:

W和S分别控制放大和缩小,A和D分别控制左右移动。
1.3.1 CPU使用情况
1.3.1.1 CPU使用情况单选功能
在CPU Usage中显示的是CPU的运行情况,如图所示有8个CPU正在工作。
点击泳道图中的色块,在下方的弹出层会显示当前CPU上的运行信息:

弹窗信息分别表示:
序号
名称
含义
1
Process
进程名
2
Thread
线程名
3
StartTime(Relative)
开始时间相对时间
4
StartTime(Absolute)
开始时间绝对时间
5
Duration
运行时长
6
prio
优先级
7
End State
结束状态信息
1.3.1.2 CPU使用情况框选功能
框选出一段时间内的色块,框选后在最下方的弹出层中会展示框选数据的统计表格,总共有六个 Tab 页。
CPU by thread 的 Tab 页,主要显示了在框选时间区间内的进程名、进程号、线程名、线程号、总运行时长、平均运行时长和调度次数信息。

CPU by process 的 Tab 页,主要显示了在框选时间区间内的进程名、进程号、总运行时长、平均运行时长和调度次数信息。

CPU Usage 的 Tab 页,主要显示了在框选时间区间内,该频率时间占比前三的信息。

Thread Switches 的 Tab 页,按照状态>进程>线程,统计对应状态下的次数,持续时长,最小时长,平均时长,最大时长信息。

Thread States 的 Tab 页,按进程>线程>状态的维度去统计,需要呈现该状态的线程名、进入该状态次数、该状态下时长、最小时长、平均时长、最大时长。
Sched Priority 的 Tab 页,按优先级显示调度,显示框选范围内所有 Running 以及 Running 之前的 Runnable 线程的最小,最大,平均耗时。
-

1.3.2 CPU使用频率

1.3.3 进程,线程,方法数据
下图是进程数据,左边部分展示进程名称和 id,右边显示线程切换关系,线程的调用方法,进程间内存信息等。
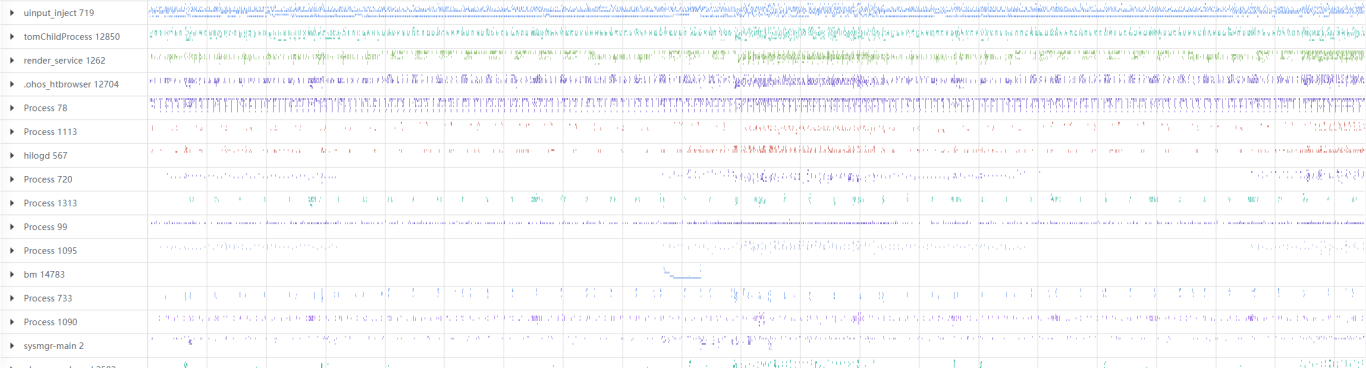
1.3.3.1 进行,线程和方法数据的单选功能
SmartPerf支持搜索功能,在搜索框搜索关键信息,会在CPU使用情况中高亮相关内容,并且显示对应的进程和线程信息,支持跳转。

跳转可以查看所在CPU的使用情况:

1.3.3.2 进程,现成和方法数据的框选功能
进程,线程和方法数据也支持框选功能,下图是线程运行状态框选统计信息,包括进程名、进程号、线程名、线程号、线程状态、状态持续时间、平均持续时间、该线程状态发生的次数。

1.3.4 火焰图
smartperf还支持查找火焰图,火焰图用于查看CPU的调用栈及调用时间,横向表示时间,纵向表示调用栈,可对其进行性能分析,找出瓶颈点。

2.窗口相关体验类问题-最佳实践
应用布局的UX设计至关重要,在窗口拖拽缩放的过程中,应用的UX设计会影响了布局的速度,直接影响用户的使用体验,应用要选择合适的UX。
2.1 应用布局UX建议
2.1.1 宫格布局拉伸:固定尺寸--动态间距--一帧切
优势:动态间距保证画面填充度。
缺点:动态间距导致布局前后差异较大,一帧切稍显闪跳。
放大场景:

缩小场景:

参考示例:
@Entry @Component struct GridColumnsTemplate { data: number[] = [0, 1, 2, 3, 4, 5] data1: number[] = [0, 1, 2, 3, 4, 5] data2: number[] = [0, 1, 2, 3, 4, 5] build() { Column({ space: 10 }) { Text('auto-stretch 先根据设定的列宽计算列数,余下的空间会均分到每个列间距中').width('90%') Grid() { ForEach(this.data2, (item: number) => { GridItem() { Text('N' + item).height(80) } .backgroundColor(Color.Orange) }) } .width('90%') .border({ width: 1, color: Color.Black }) .columnsTemplate('repeat(auto-stretch, 70)') .columnsGap(10) .rowsGap(10) .height(150) } .width('100%') .height('100%') } }2.1.2 宫格布局拉伸:固定尺寸-固定间距-淡入淡出
优势:画面稳定性高,淡入淡出视觉体验佳,减少跳变感(竞品)
缺点:拉伸时画面留白,缩小时画面裁切
放大场景:

缩小场景:

参考示例:
@Entry
@Component
struct GridColumnsTemplate {
data: number[] = [0, 1, 2, 3, 4, 5]
data1: number[] = [0, 1, 2, 3, 4, 5]
data2: number[] = [0, 1, 2, 3, 4, 5]
build() {
Column({ space: 10 }) {
Text('auto-fill 根据设定的列宽自动计算列数').width('90%')
Grid() {
ForEach(this.data, (item: number) => {
GridItem() {
Text('N' + item).height(80)
}
.backgroundColor(Color.Orange)
})
}
.width('90%')
.border({ width: 1, color: Color.Black })
.columnsTemplate('repeat(auto-fill, 70)')
.columnsGap(10)
.rowsGap(10)
.height(150)
}
}2.1.3 宫格布局拉伸:动态尺寸-固定间距-淡入淡出
优势:动态间距保证画面填充度
缺点:前后变化过于激烈,布局原因导致画面重叠,稳定性差
放大场景:

缩小场景:
图14-1

参考示例:
@Entry
@Component
struct GridColumnsTemplate {
data: number[] = [0, 1, 2, 3, 4, 5]
data1: number[] = [0, 1, 2, 3, 4, 5]
data2: number[] = [0, 1, 2, 3, 4, 5]
build() {
Column({ space: 10 }) {
Text('auto-fit 先根据设定的列宽计算列数,余下的空间会均分到每一列中').width('90%')
Grid() {
ForEach(this.data1, (item: number) => {
GridItem() {
Text('N' + item).height(80)
}
.backgroundColor(Color.Orange)
})
}
.width('90%')
.border({ width: 1, color: Color.Black })
.columnsTemplate('repeat(auto-fit, 70)')
.columnsGap(10)
.rowsGap(10)
.height(150)
}
}
2.1.4 建议:
1、推荐使用 固定尺寸-固定间距-淡入淡出。
2、不推荐使用 动态尺寸-固定间距 布局,淡入淡出不能完成优化闪跳。
2.2 应用启动白屏优化
2.2.1 问题案例
部分应用启动白屏时间长:

2.2.2 解决方案
可以通过调用removeStartingWindow接口控制启动页消失时机,实现平滑过渡。
2.2.2.1 在metadata标签配置使能移除启动页功能
metadata标签可配置使能移除启动页功能,name为enable.remove.starting.window,value可配置为true/false,未配置则默认为false。
参考示例:
{
"module": {
"name": "entry",
"type": "entry",
"description": "$string:module_desc",
"mainElement": "EntryAbility",
"deviceTypes": [
"phone",
"tablet",
"2in1"
],
"deliveryWithInstall": true,
"installationFree": false,
"pages": "$profile:main_pages",
"abilities": [
{
"name": "EntryAbility",
"srcEntry": "./ets/entryability/EntryAbility.ets",
"description": "$string:EntryAbility_desc",
"icon": "$media:layered_image",
"label": "$string:EntryAbility_label",
"startWindowIcon": "$media:startIcon",
"startWindowBackground": "$color:start_window_background",
"exported": true,
"metadata": [
{
"name": "enable.remove.starting.window",
"value": "true"
}
],
"skills": [
{
"entities": [
"entity.system.home"
],
"actions": [
"action.system.home"
]
}
]
},
],
"extensionAbilities": [
{
"name": "EntryBackupAbility",
"srcEntry": "./ets/entrybackupability/EntryBackupAbility.ets",
"type": "backup",
"exported": false,
"metadata": [
{
"name": "ohos.extension.backup",
"resource": "$profile:backup_config"
}
],
}
]
}
}注意事项:
1、在标签配置为"true"的情况下,系统提供了启动页超时保护机制,若5s内未调用此接口,系统将自动移除启动页。
2、若标签配置为"false"或未配置标签,则此接口不生效,启动页将会在应用首帧渲染完成后自动移除。
2.2.2.2 调用removeStartingWindow接口移除启动页
removeStartingWindow(): Promise<void>参考示例:
// EntryAbility.ets
import { UIAbility } from '@kit.AbilityKit';
import { BusinessError } from '@kit.BasicServicesKit';
export default class EntryAbility extends UIAbility {
// ...
onWindowStageCreate(windowStage: window.WindowStage) {
console.info('onWindowStageCreate');
windowStage.loadContent('pages/Index', (err) => {
if (err.code) {
hilog.error(DOMAIN, 'testTag', 'Failed to load the content. Cause: %{public}s', JSON.stringify(err));
return;
}
hilog.info(DOMAIN, 'testTag', 'Succeeded in loading the content.');
});
windowStage.removeStartingWindow().then(() => {
console.info('Succeeded in removing starting window.');
}).catch((err: BusinessError) => {
console.error(`Failed to remove starting window. Cause code: ${err.code}, message: ${err.message}`);
});
}
};注意事项:
1、依赖API 14。
2、此接口只对应用主窗口生效,且需要在module.json5配置文件abilities标签中的metadata标签下配置"enable.remove.starting.window"为"true"才会生效。
2.3 窗口缩放内容抖动问题优化
2.3.1 问题现象
拖动窗口进行放缩时,应用内容出现抖动。

窗口缩放默认为居中对齐,窗口缩放的时候会先拉伸画布,再重新布局到新位置,就会发生抖动,解决措施就是改成左上角对齐(TopLeft)。
最终采取的规避方案:QT窗口的Resize时XComponent的RenderFit采用TopLeft模式裁切。
QT-ETS接口
Xcomponent背景色设置为透明,renderFit设置为TOP_LEFT。
XComponent().width().height().backgroundColor(Color.Transparent).renderFit(RenderFit_LEFT)QT-C接口
应用侧无需单独适配,只需QT中Xcomponet创建指定renderfit topleft与设置背景色透明。
xComponentNode->setAttributeOrFail(::NODE_RENDER_FIT, ::ARKUI_RENDER_FIT_TOP_LEFT);
xComponentNode->setAttributeOrFail(::NODE_BACKGROUND_COLOR, transparentArgb8888);2.3.4 优化后效果

3. 提升调度优先级
3.1 应用场景
如果某个任务优先级较低,在资源调度上处于劣势,但是用户希望能够立即执行,并且分配更多的执行时间,那可以通过接入QoS来改善。
3.2 QoS概念
QoS(quality-of-service),即服务质量,在OpenHarmony中QoS特性主要指任务的优先调度属性。开发者可以利用QoS对要执行的工作进行分类,以指示其与用户交互的关联程度;系统则可以根据任务设置的QoS安排各任务的运行时间和运行次序。
3.3 QoS等级
typedef enum QoS_Level {
/**
* 适用于数据同步等用户不可见的后台任务。
*/
QOS_BACKGROUND,
/**
* 适用于下载等不需要立即看到响应效果的任务。
*/
QOS_UTILITY,
/**
* 默认的QoS等级。
*/
QOS_DEFAULT,
/**
* 适用于打开文档等用户触发并且可以看到进展的任务。
*/
QOS_USER_INITIATED,
/**
* 适用于页面加载等越快越好的任务。
*/
QOS_DEADLINE_REQUEST,
/**
* 适用于动效绘制等用户交互任务。
*/
QOS_USER_INTERACTIVE,
} QoS_Level;3.4 接口介绍
OH_QoS_SetThreadQoS 用于设置某个任务的QoS等级。
int OH_QoS_SetThreadQoS(QoS_Level level);QoS_Level level 用于描述要为任务设置的QoS等级。
#include <stdio.h>
#include "qos/qos.h"
int func()
{
// 重置当前任务的QoS等级
int ret = OH_QoS_ResetThreadQoS();
if (!ret) { // ret等于0说明重置成功
printf("reset QoS Success.");
} else { // ret不等于0说明重置失败
printf("reset QoS failed.");
}
return 0;
}OH_QoS_ResetThreadQoS 取消某个任务设置的QoS等级。
int OH_QoS_GetThreadQoS(QoS_Level *level);
#include <stdio.h>
#include "qos/qos.h"
int func()
{
// 重置当前任务的QoS等级
int ret = OH_QoS_ResetThreadQoS();
if (!ret) { // ret等于0说明重置成功
printf("reset QoS Success.");
} else { // ret不等于0说明重置失败
printf("reset QoS failed.");
}
return 0;
}OH_QoS_GetThreadQoS 获取某个任务之前最近一次设置的QoS等级;如果之前未设置任何QoS等级,则返回-1。
int OH_QoS_GetThreadQoS(QoS_Level *level);
#include <stdio.h>
#include "qos/qos.h"
int func()
{
// 获取当前任务的QoS等级
QoS_Level level = QoS_Level::QOS_DEFAULT;
int ret = OH_QoS_GetThreadQoS(&level);
if (!ret) { // ret等于0说明获取成功
printf("get QoS level %d Success.", level);
} else { // ret不等于0说明获取失败
printf("get QoS level failed.");
}
return 0;
}参考文档:QoS 开发指导。
4 经验分享
4.1 并行压缩
问题背景
文档类应用的大部分文件(docx、pptx、xlsx)都是基于zip格式,文件的解压与压缩是文档类应用实现各种文件打开与保存的技术基础。文档类应用在PC应用的鸿蒙化改造过程中,保存场景与竞品的性能差异较大,文件压缩是大多保存场景中的性能瓶颈。如果能够对文件压缩进行性能优化,将对应用的各类文件保存场景有非常可观的性能提升。下面分享针对保存场景做的优化案例,介绍相关的分析和优化思路。
保存场景性能问题分析
首先针对50M PPT保存典型场景,使用hiprofiler抓取应用进程trace文件进行函数热点分析,并结合应用业务代码梳理出PPT保存的详细流程,分析性能瓶颈点,挖掘可优化的方向。
从trace图可粗略判断出,ppt保存业务逻辑有三个主要线程,(1)主线程,界面相关负责显示与渲染;(2)io解析线程,负责业务数据解析成ooxm数据;(3)压缩线程,负责将解析后的数据压缩成zip格式的数据并写入到压缩文件。
通过trace泳道图发现,解析线程与压缩线程占据了90%的耗时,且两者存在相互等待的现象。在前半段时间内,解析线程高负荷运行,压缩线程大部分时间在等待,后半段时间内,压缩线程高负荷运行,解析线程大部分时间在等待。性能瓶颈点就在此处,要想从本质上提升保存性能,必从这两个线程着手,即优化解析性能或者优化压缩性能。因此需要进一步分析梳理解析与压缩的详细业务逻辑与关系。


业务逻辑拆解
1、解析与压缩业务逻辑拆解
在保存场景中解析与压缩属于生产者与消费者关系,当生产者速度较慢,消费者速度较快时就会出现上述前半段等待现象,反之就会出现上述后半段等待现象。当前解析线程与压缩线程都是单线程执行,如果能够并行解析或者并行压缩,将大幅降低上述等待时间,提升整体性能。下面进一步分析解析和压缩并行优化方案的可行性。

2、解析并行优化可行性分析
某应用是基于OOXML标准实现的一套办公软件,为能够高效分析代码梳理解析的详细流程,需要弄清OOXML标准。
OOXML背景知识:

以PPTX保存为例,其解析过程如下图所示,保存过程中的解析线程按顺序解析各类资源文件,如母版资源、布局资源、幻灯页资源、媒体资源等。这些资源间可能存在依赖关系,导致资源间的解析很难并行化。另外,同类资源之间,由于共享变量较多,且调用层次很深,给并行化处理带来很大的困难。最后,对一个具体资源的解析是严格按照:添加资源->生成资源数据->解析完成标志,的顺序进行的,并约定压缩线程严格按照此顺序对一个具体资源文件数据进行压缩。由此可知,解析并行化难度太高,工作量无法估计。

3、压缩并行优化可行性分析
OOXML标准规定以ZIP格式压缩XML文件和资源文件,ZIP格式如下图所示。结合应用压缩代码可知,单个文件内所有数据块的压缩共用一个压缩流,但文件与文件之间使用独立的压缩流,即:单个文件的数据块之间存在压缩依赖,文件与文件之间不存在压缩依赖。且压缩后的不同文件数据写入ZIP文件的的顺序没有先后关系,只要中央目录数据中记录对应文件的正确偏移就行。因此在理论上文件之间是可以实现并行压缩的。
ZIP文件格式:

应用原始压缩方案:

方案设计
文件级并行压缩不仅要考虑并发效率,还要考虑内存消耗,如果单个文件过大,可能会导致内存过渡消耗而产生性能问题,因此在设计并行压缩方案时要考虑空间与时间的权衡关系。
并行压缩方案: 使用缓存队列存放解析后的文件数据,队列长度为n,队列的每个元素存放一个完整的文件数据,启动m个独立压缩线程,并从缓存队列中抢占文件数据,执行压缩任务,如果缓存容量达到上限,则当前解析的文件数据使用原始串行压缩流程,并行压缩任务会被挂起,直到当前串行压缩文件结束,并行压缩任务被重新唤醒。如此,根据文件大小及缓存使用情况在串行与并行压缩流程间自动切换。

穿刺实验
由于并行压缩优化方案,相对来说改动较大,如果直接在应用上进行适配,可能需要长期占用现场紧缺的机器资源,且上述分析只是理论上可行,实际有多少收益并不清楚。因此,需要在本地设计一个穿刺实验,尽快且尽可能验证出此方案的实际收益。
通过上述流程梳理,可在本地实现一个demo,demo中包含一个生产者从文件夹读取文件数据并将数据发送到缓存队列,模拟应用解析线程发送数据;包含多个消费者,从缓存队列里抢占数据,执行zlib压缩,即模拟应用的并行压缩线程;最后使用此demo在不同线程数下测试100k、2M、10M、50M、1G大小的文件夹(对应大小PPTX样张,使用好压解压后生成的文件夹)所消耗的时间,并计算相对单线程的收益。
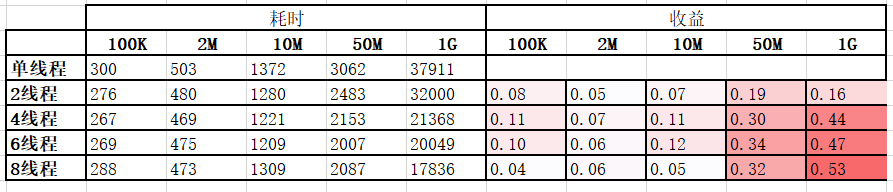
由穿刺实验可知,在50M与1G大小的文件夹下,线程数为6时最优,有30%~40%的收益。小于等于10M的场景收益不是很明显。
应用并行优化效果
并行压缩优化后,PPTX与DOCX在10M以上的样章场景收益较大,这与穿刺实验结果相近,在XLSX样章场景中基本没有收益。这种结果也符合预期,因为xlsx保存的性能瓶颈在解析流程,而PPTX与DOCX的性能瓶颈大部分在压缩阶段。通过trace对比也能验证这一结论。

下图为50M PPTX保存,串行压缩trace与并行压缩trace对比,可知,压缩瓶颈阶段从原来的612.3ms优化到205.7ms,将近3倍的提升,端到端收益接近30%。

总结
本文主要介绍了PC上文档类应用保存场景的优化思路:1. 通过trace分析热点函数与线程间关系,完成性能拆解与分析,寻找性能瓶颈点与可能的优化方向;2. 拆解业务流程,论证优化方向的可行性;3. 尝试通过缓存、并行化、内存池、线程池等手段设计优化方案。并通过穿刺实验快速验证方案的可行性与实际收益。本场景通过并行化,消除压缩性能瓶颈。另外通过缓存、内存池、线程池等技术手段,使并行化压缩达到性能最优,大幅提升了保存场景的整体效率,改善了用户体验。
4.2 QT高频函数优化
4.2.1 概述
QT是跨平台的应用程序开发框架,很多三方应用会使用QT实现跨平台兼容性和用户界面功能。对于一些应用,不同Case会调用同一个QT函数,优化一个QT函数,这些Case都能受益提升;对于其他使用QT框架的应用,也能采取类似甚至相同的优化方法来提升性能。因此优化QT高频函数,可以“一举两得”。
4.2.2 场景案例1
4.2.2.1 实现原理
在高频函数列表里,fetchRGBA8888PMToARGB32PM和storeRGBA8888PMFromARGB32PM占比突出,它们几乎成对出现,而且功能相反。这2个函数用于RGBA8888PM颜色格式和ARGB32PM颜色格式之间转换,R是Red红色,G是Green绿色,B是Blue蓝色,A是Alpha透明度,PM是Pre-Multiplied预乘(已将Alpha透明度乘到RGB里),8和32是bit位数。颜色格式转换流程图如下。

为了找到颜色格式转换的原因,需要再往上层阅读源码。通过走读代码和查阅QT渲染资料,梳理blend_color_generic函数流程图如下。

结合上图,QT渲染的整体流程是:①遍历span(span为绘图区域);②计算得到span在rasterBuffer中的起始位置;③将span的颜色格式从RGBA8888PM转为ARGB32PM格式,从rasterBuffer取到临时buffer;④对临时buffer中的像素颜色做变换;⑤将span的颜色格式从ARGB32PM还原为RGBA8888PM格式,从临时buffer取回到rasterBuffer中。另外③④⑤都是函数指针,具体使用哪个函数由图像格式决定,当图像格式为RGBA8888PM时,③是fetchRGBA8888PMToARGB32PM,⑤是storeRGBA8888PMFromARGB32PM。
③和⑤费劲周章地转换颜色格式,是因为④的算法只支持在ARGB32PM上吗?查看图像格式是ARGB32PM时,是否还需要转换颜色格式,结果③和⑤的函数为空实现,验证了这个猜想。
4.2.2.2 开发步骤

快慢路径
QT作为通用框架,支持近40种QImage图像格式,近40种颜色混合模式,因此op.destFetch,op.funcSolid,op.destStore都使用函数指针实现(见图中标黄处func ptr)。通过三方应用现场Debug以及打日志,发现应用常用场景的图像格式是Format_RGBA8888_Premultiplied和Format_ARGB32,颜色混合模式op.mode常用3种clear, source,sourceOver。根据常用情况,组合出6条快速路径,快速路径可以避免函数指针的间接调用(见图中标黄处inline call);此外将执行路径都确定下来,方便编译器对快速路径做整体优化。
减少数据拷贝
op.destFetch将原数据拷贝到buffer中,op.destStore将buffer拷贝回原数据(见图中橙色data copy)。对op.funcSolid考察后,发现在应用常用情况下,是可以原地做op.funcSolid,避免数据搬移拷贝。
消除冗余算子
在具体分析章节中,已分析得到算法op.funcSolid只支持在ARGB32PM格式上。如果op.funcSolid对颜色通道的操作是隔离的,即颜色之间不会溢出或影响,就可以消除op.destFetch和op.destStore。在Demo实验发现,op.mode是clear和source时,可以避免颜色格式之间的转换,明显提升速度(见图中灰色fetch和store)。
并行化
span(span为绘图区域)间没有依赖关系,数据结构也比较简单,具有并行化的条件(见图中serial execution)。对比最新的QT6代码,在blend_color_generic调用RGBA相关处理方法之前,增加了多线程并发的优化,定义QT_USE_THREAD_PARALLEL_FILLS宏后即启用,按照64个span的分块放入QT自身的线程池进行处理。Demo上使用多线程QThread版的blend_color_generic相比单线程版本有劣化。尝试对blend_color_generic函数接入FFRT(Function Flow Runtime Kit),FFRT基于更轻量的协程(见图中parallel execution)。Demo上FFRT并未显著提升性能,表现不如单线程版本。推测是在span长度较小的情况下,并行化有额外的任务管理、同步和上下文切换的开销,开销超过了并行化带来的好处。
汇编化
对于大多数应用,现代编译器提供的优化已经足够好。APP在应用商店上架有体积要求,采用的编译优化等级可能是-Os(优化代码体积),这时使用-O3(最高级别的优化)在性能上表现更好。一个可行的方向是,对部分高频函数进行汇编化。clear算子和source算子中都使用了qt_memfill32函数。qt_memfill32 函数的作用是将一个32位无符号整数 (quint32) 值填充到一个数组中,即将数组的每个元素都设置为指定的值。纯汇编版在处理长度为256时,有7%的优化收益。
NEON指令优化
NEON 是 ARM 处理器的 SIMD(单指令多数据)扩展,用于加速数据并行计算。NEON 支持 64 位和 128 位向量操作,并且能够在一个指令中处理多个数据元素。**clear算子和source算子中都使用了BYTE_MUL函数。BYTE_MUL函数的作用是字节乘,可以将输入的RGB三通道分别乘以透明度Alpha。原版BYTE_MUL逐个处理数组中元素,未充分利用处理器的并行机制。对于clear算子和source算子,将循环转换为ARM NEON汇编后,在处理长度为1728时,有78%的优化收益。
4.2.2.3 实现效果
blend_color_generic在做以上优化后,函数本身优化67%,在全场景端到端有2%-10%的收益。该函数是QT中的渲染函数,用于混合颜色,对于其他使用QT框架的APP,也能采取类似甚至相同的优化方法来提升性能。
|
场景 |
端到端新PC收益 |
端到端新PC收益 |
|---|---|---|
|
1G PPT首次打开 |
↑5.1% |
↓748ms |
|
50M XLS打开 |
↑3.8% |
↓98ms |
|
1G WORD打开 |
↑2.7% |
↓123ms |
|
50M WORD首次打开 |
↑9.8% |
↓218ms |
|
表格复制粘贴 |
↑20.3% |
↓94ms |
4.2.2.4 示例代码
#ifdef Q_OS_OHOS↵
extern const uint *QT_FASTCALL fetchARGB32ToARGB32PM_neon(uint * buffer, const uchar *src,↵
int index, int count,↵
const QVector<QRgb> *, QDitherInfo *);↵
↵
↵
extern void QT_FASTCALL storeARGB32FromARGB32PM_neon(uchar * dest, const uint *src, int index,↵
int count, const QVector<QRgb> *,↵
QDitherInfo *);↵
↵
↵
extern void QT_FASTCALL comp_func_solid_Source(uint *dest, int length, uint color, uint const_alpha);↵
extern void QT_FASTCALL comp_func_solid_Clear(uint *dest, int length, uint, uint const_alpha);↵
↵
↵
static Q_ALWAYS_INLINE void format_RGBA8888_Premultiplied_fetch_clear_store(QSpanData *data, int y, int x, int length, uint const_alpha) {↵
uint *dest = reinterpret_cast<uint *>(data->rasterBuffer->scanLine(y)) + x;↵
comp_func_solid_Clear(dest, length, 0, const_alpha);↵
}↵
↵
↵
static Q_ALWAYS_INLINE void format_RGBA8888_Premultiplied_fetch_source_store(QSpanData *data, int y, int x, int length, uint color, uint const_alpha) {↵
uint *dest = reinterpret_cast<uint *>(data->rasterBuffer->scanLine(y)) + x;↵
uint color_RGBA = ARGB2RGBA(color);↵
comp_func_solid_Source(dest, length, color_RGBA, const_alpha);↵
}↵
↵
↵
static Q_ALWAYS_INLINE void format_RGBA8888_Premultiplied_fetch_sourceOver_store(QSpanData *data, int y, int x, int length, uint color, uint const_alpha, bool ingore_fetch) {↵
uint *dest = reinterpret_cast<uint *>(data->rasterBuffer->scanLine(y)) + x;↵
if (!ingore_fetch) {↵
fetchRGBA8888PMToARGB32PM(dest, data->rasterBuffer->scanLine(y), x, length, nullptr, nullptr);↵
}↵
↵
↵
#if defined(__ARM_NEON__)↵
comp_func_solid_SourceOver_neon(dest, length, color, const_alpha);↵
#else↵
comp_func_solid_SourceOver(dest, length, color, const_alpha);↵
#endif↵
↵
↵
storeRGBA8888PMFromARGB32PM(data->rasterBuffer->scanLine(y), dest, x, length, nullptr, nullptr);↵
}↵
↵
↵
static Q_ALWAYS_INLINE void format_ARGB32_fetch_clear_store(QSpanData *data, int y, int x, int length, uint const_alpha, bool ingore_fetch) {↵
uint *dest = reinterpret_cast<uint *>(data->rasterBuffer->scanLine(y)) + x;↵
if (const_alpha == 255) {↵
// shortcut: ignore fetch and store, clear use: comp_func_Clear_template<Argb32Operations>(dest, length, const_alpha);↵
qt_memfill32(dest, 0, length);↵
} else {↵
if (!ingore_fetch) {↵
#if defined(__ARM_NEON__) && Q_BYTE_ORDER == Q_LITTLE_ENDIAN↵
fetchARGB32ToARGB32PM_neon(dest, data->rasterBuffer->scanLine(y), x, length, nullptr, nullptr);↵
#else↵
fetchARGB32ToARGB32PM(dest, data->rasterBuffer->scanLine(y), x, length, nullptr, nullptr);↵
#endif↵
}↵
↵
↵
// snippet from: comp_func_Clear_template<Argb32Operations>(dest, length, const_alpha);↵
uint ialpha = 255 - const_alpha;↵
for (int i = 0; i < length; ++i) {↵
dest[i] = BYTE_MUL(dest[i], ialpha);↵
}↵
↵
↵
#if defined(__ARM_NEON__) && Q_BYTE_ORDER == Q_LITTLE_ENDIAN↵
storeARGB32FromARGB32PM_neon(data->rasterBuffer->scanLine(y), dest, x, length, nullptr, nullptr);↵
#else↵
storeARGB32FromARGB32PM(data->rasterBuffer->scanLine(y), dest, x, length, nullptr, nullptr);↵
#endif↵
}↵
}↵
↵
↵
static Q_ALWAYS_INLINE void format_ARGB32_fetch_source_store(QSpanData *data, int y, int x, int length, uint color, uint const_alpha, bool ingore_fetch) {↵
uint *dest = reinterpret_cast<uint *>(data->rasterBuffer->scanLine(y)) + x;↵
if (!ingore_fetch) {↵
#if defined(__ARM_NEON__) && Q_BYTE_ORDER == Q_LITTLE_ENDIAN↵
fetchARGB32ToARGB32PM_neon(dest, data->rasterBuffer->scanLine(y), x, length, nullptr, nullptr);↵
#else↵
fetchARGB32ToARGB32PM(dest, data->rasterBuffer->scanLine(y), x, length, nullptr, nullptr);↵
#endif↵
}↵
↵
↵
comp_func_solid_Source(dest, length, color, const_alpha);↵
↵
↵
#if defined(__ARM_NEON__) && Q_BYTE_ORDER == Q_LITTLE_ENDIAN↵
storeARGB32FromARGB32PM_neon(data->rasterBuffer->scanLine(y), dest, x, length, nullptr, nullptr);↵
#else↵
storeARGB32FromARGB32PM(data->rasterBuffer->scanLine(y), dest, x, length, nullptr, nullptr);↵
#endif↵
}↵
↵
↵
static Q_ALWAYS_INLINE void format_ARGB32_fetch_sourceOver_store(QSpanData *data, int y, int x, int length, uint color, uint const_alpha, bool ingore_fetch) {↵
uint *dest = reinterpret_cast<uint *>(data->rasterBuffer->scanLine(y)) + x;↵
if (!ingore_fetch) {↵
#if defined(__ARM_NEON__) && Q_BYTE_ORDER == Q_LITTLE_ENDIAN↵
fetchARGB32ToARGB32PM_neon(dest, data->rasterBuffer->scanLine(y), x, length, nullptr, nullptr);↵
#else↵
fetchARGB32ToARGB32PM(dest, data->rasterBuffer->scanLine(y), x, length, nullptr, nullptr);↵
#endif↵
}↵
↵
↵
#if defined(__ARM_NEON__)↵
comp_func_solid_SourceOver_neon(dest, length, color, const_alpha);↵
#else↵
comp_func_solid_SourceOver(dest, length, color, const_alpha);↵
#endif↵
↵
↵
#if defined(__ARM_NEON__) && Q_BYTE_ORDER == Q_LITTLE_ENDIAN↵
storeARGB32FromARGB32PM_neon(data->rasterBuffer->scanLine(y), dest, x, length, nullptr, nullptr);↵
#else↵
storeARGB32FromARGB32PM(data->rasterBuffer->scanLine(y), dest, x, length, nullptr, nullptr);↵
#endif↵
}↵
↵
↵
static const uint FORMAT_SHIFT = 6;↵
static const uint RGBA8888_PM_CLEAR = (QImage::Format_RGBA8888_Premultiplied << FORMAT_SHIFT) + QPainter::CompositionMode_Clear;↵
static const uint RGBA8888_PM_SOURCE = (QImage::Format_RGBA8888_Premultiplied << FORMAT_SHIFT) + QPainter::CompositionMode_Source;↵
static const uint RGBA8888_PM_SOURCEOVER = (QImage::Format_RGBA8888_Premultiplied << FORMAT_SHIFT) + QPainter::CompositionMode_SourceOver;↵
static const uint ARGB32_CLEAR = (QImage::Format_ARGB32 << FORMAT_SHIFT) + QPainter::CompositionMode_Clear;↵
static const uint ARGB32_SOURCE = (QImage::Format_ARGB32 << FORMAT_SHIFT) + QPainter::CompositionMode_Source;↵
static const uint ARGB32_SOURCEOVER = (QImage::Format_ARGB32 << FORMAT_SHIFT) + QPainter::CompositionMode_SourceOver;↵
#endif↵
↵
↵
#if !defined(Q_CC_SUN)↵
static↵
#endif↵
void↵
blend_color_generic(int count, const QSpan *spans, void *userData)↵
{↵
QSpanData *data = reinterpret_cast<QSpanData *>(userData);↵
uint buffer[BufferSize];↵
Operator op = getOperator(data, spans, count);↵
const uint color = data->solid.color.toArgb32();↵
#ifdef Q_OS_OHOS↵
uint indicator = (data->rasterBuffer->format << FORMAT_SHIFT) + op.mode;↵
bool ignoreFetch = op.destFetch == destFetchUndefined;↵
#endif↵
↵
↵
while (count--) {↵
int x = spans->x;↵
int length = spans->len;↵
while (length) {↵
int l = qMin(BufferSize, length);↵
#ifdef Q_OS_OHOS↵
switch(indicator) {↵
// cases ordered by occurrence↵
case RGBA8888_PM_CLEAR:↵
format_RGBA8888_Premultiplied_fetch_clear_store(data, spans->y, x, l, spans->coverage);↵
break;↵
case RGBA8888_PM_SOURCE:↵
format_RGBA8888_Premultiplied_fetch_source_store(data, spans->y, x, l, color, spans->coverage);↵
break;↵
case RGBA8888_PM_SOURCEOVER:↵
format_RGBA8888_Premultiplied_fetch_sourceOver_store(data, spans->y, x, l, color, spans->coverage, ignoreFetch);↵
break;↵
case ARGB32_SOURCE:↵
format_ARGB32_fetch_source_store(data, spans->y, x, l, color, spans->coverage, ignoreFetch);↵
break;↵
case ARGB32_CLEAR:↵
format_ARGB32_fetch_clear_store(data, spans->y, x, l, spans->coverage, ignoreFetch);↵
break;↵
case ARGB32_SOURCEOVER:↵
format_ARGB32_fetch_sourceOver_store(data, spans->y, x, l, color, spans->coverage, ignoreFetch);↵
break;↵
default:↵
uint *dest = op.destFetch(buffer, data->rasterBuffer, x, spans->y, l);↵
op.funcSolid(dest, l, color, spans->coverage);↵
if (op.destStore)↵
op.destStore(data->rasterBuffer, x, spans->y, dest, l);↵
break;↵
}↵
#else↵
uint *dest = op.destFetch(buffer, data->rasterBuffer, x, spans->y, l);↵
op.funcSolid(dest, l, color, spans->coverage);↵
if (op.destStore)↵
op.destStore(data->rasterBuffer, x, spans->y, dest, l);↵
#endif↵
length -= l;↵
x += l;↵
}↵
++spans;↵
}↵
}↵4.2.3 场景案例2(案例1的升级)
4.2.3.1 实现原理
更进一步,除了blend_color_generic函数之外,渲染函数也常看到blend_untransformed_generic函数,那这些函数的区别在哪?调用的场景有什么不同?再往blend_color_generic和blend_untransformed_generic函数上看一层,得到结论如下图。

QT支持多种笔刷格式,选择哪种笔刷格式最终会决定blend函数。例如,选择Solid,当底图的颜色空间是Format_RGBA8888_Premultiplied时,blend函数为blend_color_generic; 当底图的颜色空间是Format_ARGB32_Premultiplied,blend函数为blend_color_argb。对比blend_color_generic和blend_color_argb,generic包含颜色空间转换更通用,但argb更简单高效。
4.2.3.2 开发步骤
颜色空间转换:

BEFORE:如绿色底文字所示,blend_untransformed_generic会经过①②③④四个步骤。其中③QT算子func基于Format_ARGB32_Premultiplied,而QRasterBuffer是Format_RGBA8888_Premultiplied,因此②④需要转换颜色空间。
AFTER:橙色底文字标志出了改动之处。当QT鸿蒙适配层(qohosplatformbackingstore)中的格式修改为::NATIVEBUFFER_PIXEL_FMT_BGRA_8888,QRasterBuffer对应转换为Format_ARGB32_Premultiplied。blend_untransformed_generic会演变成blend_untransformed_argb,消除了srcFetch,destFetch,destStore,只剩①func。
实现效果
|
场景 |
收益ms |
提升% |
|---|---|---|
|
EXCEL滑动帧率 |
/ |
10% |
|
EXCEL界面最大化 |
7ms |
7% |
|
WORD打字 |
/ |
7% |
|
WORD滑动帧率 |
24ms 14次binder |
13% |
|
PPT缩略图滑动帧率 |
30ms 20次binder |
24% |
4.2.3.3 示例代码
QImage::Format QOhosPlatformBackingStore::format() const
{
return QImage::Format_ARGB32_Premultiplied;
}
QImage::Format mapNativeBufferFormatToQImageFormatOrFail(std::int32_t format)
{
QImage::Format result;
switch (format) {
case ::NATIVEBUFFER_PIXEL_FMT_BGRA_8888:
result = QImage::Format_ARGB32_Premultiplied;
break;
default:
qFatal("%s: unsupported format %d", Q_FUNC_INFO, format);
}
return result;
}
void setupNativeWindowBufferFormat(::OHNativeWindow *nativeWindow)
{
auto setFormatRes = ::OH_NativeWindow_NativeWindowHandleOpt(
nativeWindow, ::NativeWindowOperation::SET_FORMAT, ::NATIVEBUFFER_PIXEL_FMT_BGRA_8888);
if (Q_UNLIKELY(setFormatRes != ohNativeWindowErrorCodeSuccess)) {
qFatal("QOhosNativeXComponent: error setting window buffer format: %d", setFormatRes);
}
}
void QOhosPlatformBackingStore::flush(QWindow *window, const QRegion ®ion, const QPoint &offset)
{
//...
setupNativeWindowBufferUsage(nativeWindow, ::OH_NativeBuffer_Usage::NATIVEBUFFER_USAGE_CPU_READ);
setupNativeWindowBufferFormat(nativeWindow);
//...
}
讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐
 0
0 0
0- 0



 已为社区贡献276条内容
已为社区贡献276条内容

所有评论(0)