Openharmony4.0摄像头采集+编码器+预览的优化
在实时音视频场景下,终端上面的摄像头除了需要本地预览之外,还需同时经过编码器编码成ES流再通过网络发送出去,而在一些嵌入式设备上面性能是一个瓶颈(终端的售价决定了硬件的配置,硬件的配置决定的性能),音视频应用程序除了要显示本地摄像头图像和编码摄像头数据之外,还要做比如远端图像的解码显示,音频3A的处理,音频的采集和播放等,这就要求我们对每一个可优化的功能模块进行仔细的研究、分析、优化,以达到在音视
在实时音视频场景下,终端上面的摄像头除了需要本地预览之外,还需同时经过编码器编码成ES流再通过网络发送出去,而在一些嵌入式设备上面性能是一个瓶颈(终端的售价决定了硬件的配置,硬件的配置决定的性能),音视频应用程序除了要显示本地摄像头图像和编码摄像头数据之外,还要做比如远端图像的解码显示,音频3A的处理,音频的采集和播放等,这就要求我们对每一个可优化的功能模块进行仔细的研究、分析、优化,以达到在音视频通话过程中的时候不卡顿并且功耗还是尽量的低。
本文正是对音视频应用场景下的一个重要环节即摄像头预览和编码的优化,为了达到最好的优化效果,我们必须把摄像头采集、编码器、预览这三方面当做一个整体去看待,他们之间的联动优劣直接决定了最终的优化结果,ok,在详细的讲优化之前,我们先了解一下Openharmony和Android系统上面Camera相关的一个图:

图中可以看出Camera框架提供了一套CS模型的架构,其中包含服务器和客户端两部分,当Camera工作的时候,我们的应用程序作为Camera Client存在(调用了camera的API),同时系统中还有一个负责从V4L2获取摄像头数据的Camera Server的进程,服务通过进程间通信把摄像头数据传给客户端,客户端再将数据送给UI控件(本地预览)和编码器(发送给远端),很明显图中的数据传输路径有三个方面:
- Camera服务到Camera 客户端,这部分的代码是由Camera框架的实现者完成,里面是否采用了传内存DMA描述符,还是做了内存拷贝将会对性能产生巨大的影响
- Camera客户端到本地预览,这部分的代码我们可以用传ID或者可以做内存拷贝传内存首地址,具体实现依赖Camera Client API 的输出。
- Camera客户端到编码器,这部分的代码我们可以用传ID或者可以做内存拷贝传内存首地址,具体实现依赖Camera Client API 的输出。
到此我想读者应该能得出结论:如果想要性能最优,上面提到的所有数据传递的步骤中一定要传递能够标识某块内存的ID,千万不要做内存的拷贝,对的,但是能否这样做受Camera框架的限制,具体就是Camera API的限制,还有就是编码器API的限制,渲染API的限制(本地预览用)。下面我用图描述一下所谓的API限制决定了实现,进而最终决定性能:
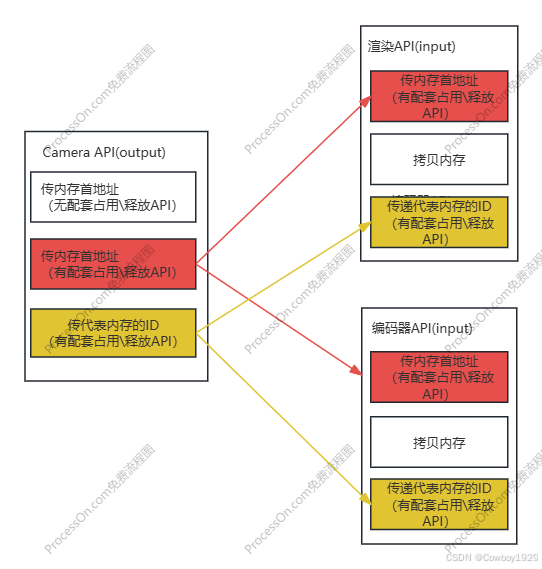
性能最好的两种路径用红色和棕色表明,这里给读者解释一下图中所谓的“配套占用\释放API”,在高效大内存的跨模块传递的时候,由于会出现跨线程或者跨进程的情况,这就导致无论是传递内存首指针还是内存ID到另外一个模块之后,这片内存可能失效了,为了避免这种情况的发生,设计者往往会提供配套占用和释放API(类似于引用计数),这样编程人员只要通过占用和释放API就可以让内存(首指针或者内存ID)在多线程或者多进程间能“自由自在的到处跑,而无需做内存的拷贝”。
那在Openharmony上面我们能用上面提到的两种最优路劲吗?回答问题之前我们先看一下Android上面是走的什么路劲(读者可能会问:为啥要看Android?烦死了!直接看Openharmony啊!!!笔者回答:不着急,Android发展这么多年了,有很多方面肯定值得我们借鉴),同样来看图:
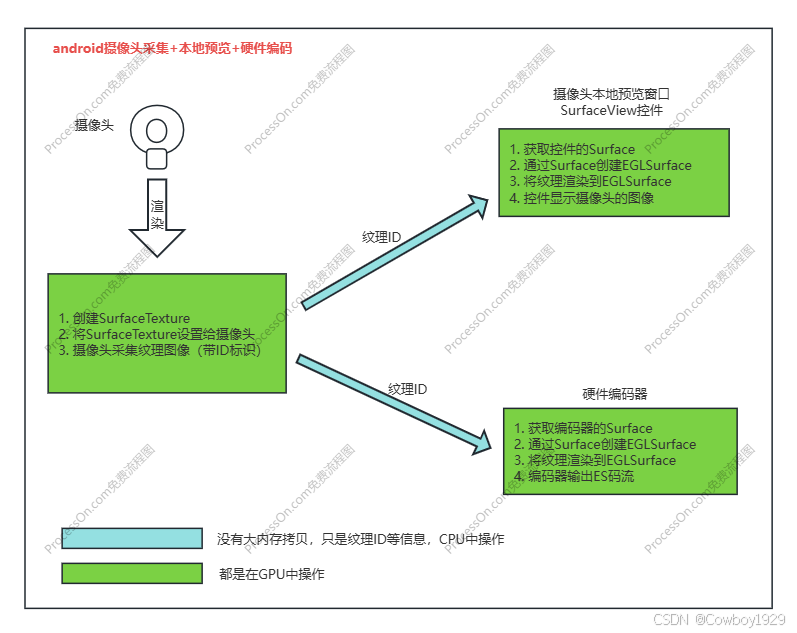
很明显android使用的是棕色的路径,详细的编程大家参考Android开发文档就行了,这里不再累述,这边大家只需要抓住以下两点就行了,绿色部分是在GPU操作,浅蓝色是在CPU中操作,那Openharmony上面可以这么做吗?同样看图1(优化前)
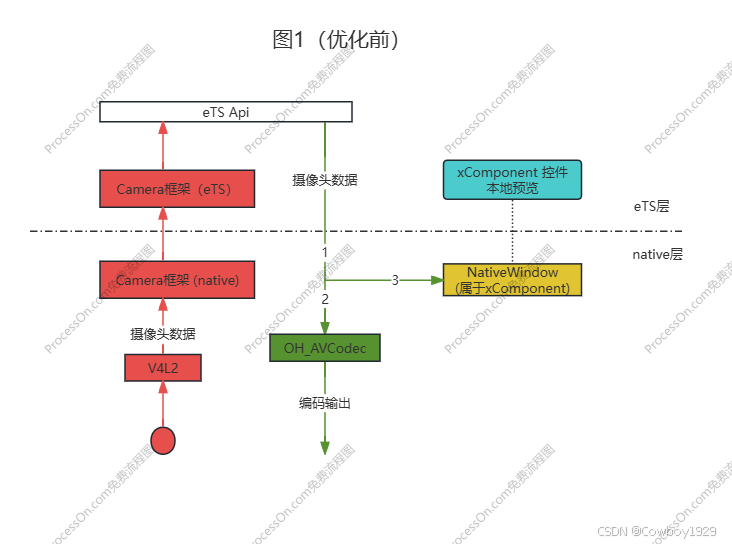
- 红色部分的Camera代码肯定有额外的CPU消耗,这就要看框架的实现,这里面是否是传指针还是做内存的拷贝先不做说明,我们也控制不了,除非你修改Camera框架代码
- 绿色部分包含的几部分性能消耗点(线段1主线程,线段2编码线程,线段3渲染线程):
- eTS往native传递buffer首指针(无占用/释放API)
- 线段1做一次内存的拷贝,拷贝出来的内存给线程2、3使用
- 线段2把内存数据拷贝给OH_AVCodec使用
- 棕色部分是OpenGLES渲染模块,需要把线段3的数据通过OpenGLES API渲染到NativeWindow上面,最终浅蓝色的xComponent控件会显示Camera抓取的图像。
大家可以结合图、文字思考一下,我们该怎么优化?
- 红色部分能去掉吗?
- 几处大内存拷贝能去掉吗?
我们再看一张图2(优化后):
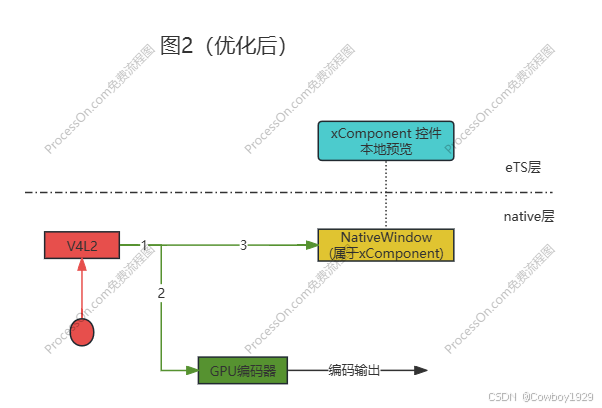
- 红色部分Camera图像的抓取我们直接基于V4L2 API开发,而且V4L2支持DMA,我们只要使用DMA 文件描述符(fd),和占用/释放API就能让DMA内存在我们的系统中“到处游荡,无需内存拷贝”
- 绿色部分的编码器,可以直接接收DMA 文件描述符进行编码,也可以直接使用CPU中申请的内存进行编码,这里我们使用前者,因此线段1,2没有内存拷贝
- 棕色部分是OpenGLES渲染模块,需要把线段3的数据通过OpenGLES API渲染到NativeWindow上面,最终浅蓝色的xComponent控件会显示Camera的抓取的图像
通过优化话前和优化后的对比,我们优化掉了:
- Openharmony的Camera框架
- 2次大内存拷贝
- 虽然这点和性能无关,但需要给大家指出,OH_AVCodec和GPU编码器相比去掉了很多配置功能,我知道OH_AVCodec也是基于GPU编码器实现的,但是当前的OH_AVCodec API适合的应用场景覆盖面小,像RTC场景下的很多可配置项它都没有暴露出来,所以笔者直接是基于GPU视频编码器进行编码(OH_AVCodec并没有使用)
最终在多款Openharmony4.0设备上实测发现优化的效果相当明显,如果大家有什么更好的方法和建议欢迎交流(文章中如果描述有误也请大家指正),另外笔者通过测试发现,无论是优化前和优化后的橙色那部分,需要把摄像头数据通过OpenGLES API 渲染到nativewindow上面的时候,本进程或者负责渲染的render_service进程的CPU消耗都很高,这也是笔者下一个优化的课题!

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐
 48
48 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)