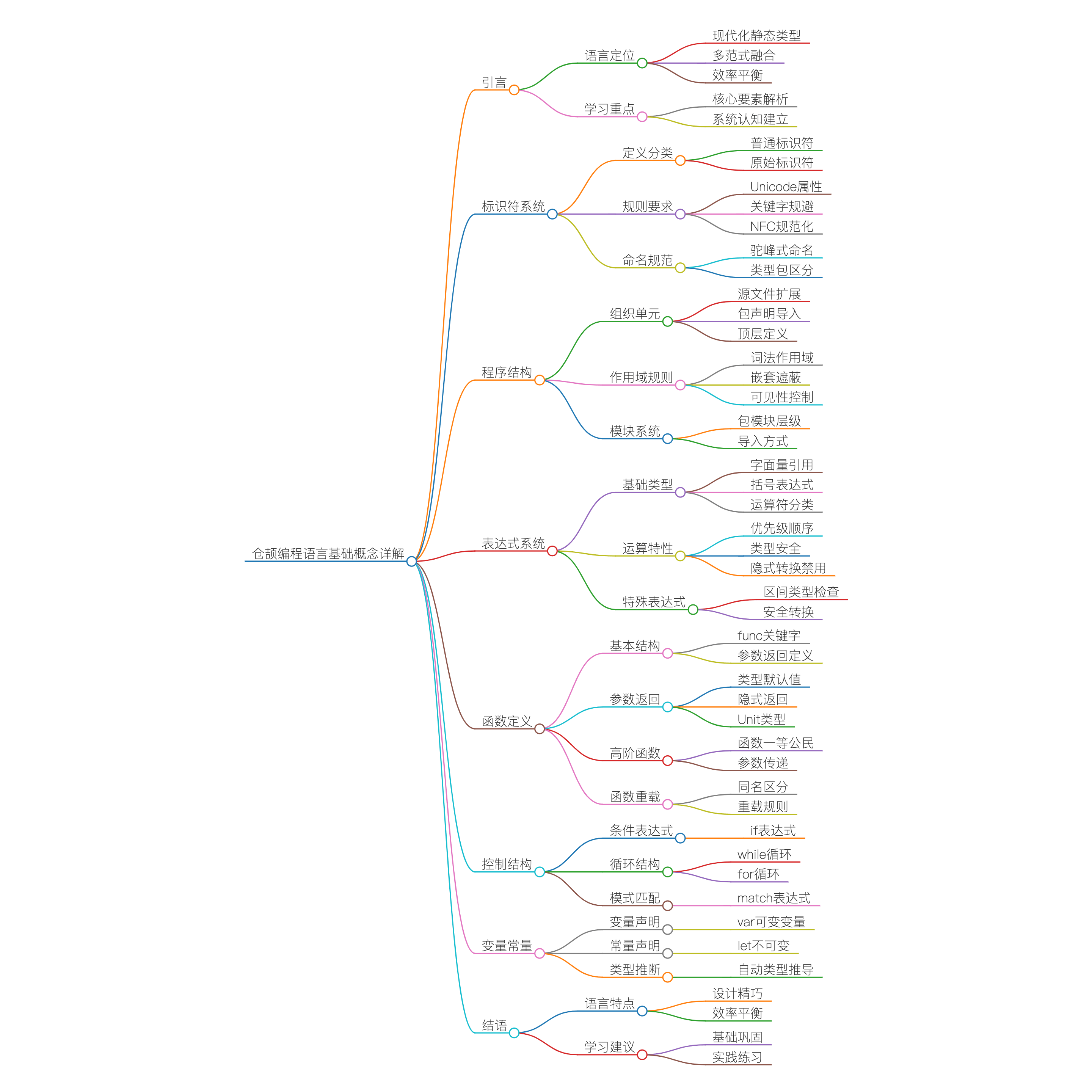
仓颉的基本概念:标识符、程序结构、表达式和函数
引言
仓颉编程语言作为一门现代化的静态类型编程语言,其设计融合了多种编程范式的优点,同时注重开发效率和运行性能的平衡。要掌握仓颉语言,首先需要理解其基本构成要素,包括标识符命名规则、程序组织结构、表达式系统和函数定义等核心概念。本文将深入解析这些基础概念,帮助读者建立对仓颉语言的系统性认识。
标识符系统
标识符的定义与分类
在仓颉语言中,标识符是用来命名变量、函数、类、接口等程序实体的符号。仓颉的标识符系统分为两大类:
普通标识符:
- 必须遵循Unicode标准中的XID_Start和XID_Continue属性规则
- 首字符必须是XID_Start字符(包括中文、英文字母等)或下划线(_)
- 后续字符可以是XID_Continue字符(包括中文、英文字母、数字等)
- 不能与语言关键字冲突
示例:
let 变量1 = 10 // 合法
let _temp = 20 // 合法
let 姓名 = "张三" // 合法
原始标识符:
- 通过在普通标识符或关键字前后添加反引号(`)定义
- 主要用于将关键字作为标识符使用的场景
- 反引号内的内容必须是合法的普通标识符
示例:
let `if` = 30 // 将关键字if作为变量名
func `while`() {} // 将关键字while作为函数名
吐槽:
是变量名不够用还是咋滴,非得用关键字做变量名,真的没有搞明白什么情况下需要这个特性
标识符规范化
仓颉语言对所有标识符进行 Normalization Form C (NFC) 规范化处理。这意味着:
- 两个标识符在NFC规范化后如果相同,则被视为同一个标识符
- 编译器内部统一使用NFC形式处理标识符
- 开发者可以使用不同形式的Unicode字符,但会被规范化为标准形式
例如,café和cafe\u0301在NFC处理后会被视为相同的标识符。
标识符命名规范
虽然仓颉编译器对标识符的格式要求较为灵活,但良好的编程实践建议遵循以下规范:
- 变量名: 使用小驼峰式命名法(camelCase),如userName
- 函数名: 使用小驼峰式命名法,如calculateTotal
- 类型名: 使用大驼峰式命名法(PascalCase),如PersonInfo
- 常量名: 使用全大写加下划线,如MAX_SIZE
- 包名: 使用全小写,多单词用点分隔,如data.utils
程序结构
基本组织单元
仓颉程序的基本组织单元是源文件,通常以.cj为扩展名。每个源文件包含以下结构要素:
-
包声明(可选): 定义当前文件所属的包
package com.example.utils -
导入声明: 引入其他包中的定义
import std.collection.HashMap -
顶层声明: 包含变量、函数、类型等定义
作用域规则
仓颉语言采用词法作用域(静态作用域)体系,作用域由大括号{}界定:
- 顶层作用域: 文件中最外层的作用域,可定义全局变量和函数
- 局部作用域: 函数体、代码块等内部形成的作用域
- 嵌套作用域: 内层作用域可以访问外层作用域的变量
作用域关键规则:
- 内层作用域可以遮蔽外层同名变量
- 变量的可见性由其声明位置决定
- 作用域级别从外到内递增,内层级别高于外层
示例:
let x = 10 // 顶层作用域
func foo() {
let x = 20 // 遮蔽外层的x
{
let x = 30 // 遮蔽上一层的x
println(x) // 输出30
}
println(x) // 输出20
}
模块系统
仓颉的模块系统基于包(package)组织:
- 包: 编译的最小单元,可包含多个源文件
- 模块: 由根包及其子包组成的树形结构,是发布的最小单元
- 导入规则:
- 单导入:import pkg1.pkg2.Item
- 多导入:import pkg1.pkg2.{Item1, Item2}
- 全导入:import pkg1.pkg2.*
表达式系统
表达式基础
在仓颉中,表达式是能产生值的代码片段。与语句不同,表达式总是返回一个值。仓颉的表达式系统包括:
- 基本表达式:
*字面量:42, 3.14, "hello", true
*变量引用:x, count- 括号表达式:(1 + 2)
- 运算符表达式:
- 算术运算:+, -, *, /, %, **
- 比较运算:==, !=, <, >, <=, >=
- 逻辑运算:&&, ||, !
- 位运算:&, |, ^, <<, >>
- 复合表达式:
赋值表达式:x = 10复合赋值:x += 5
运算符特性
仓颉的运算符系统具有以下特点:
- 优先级: 运算符按预定优先级顺序计算
1 + 2 * 3 // 先乘后加,结果为7
- 结合性: 同优先级运算符的结合方向
10 - 3 - 2 // 左结合,结果为5
- 类型安全: 运算符操作数需类型兼容
let x = 10 + 3.5 // 错误:Int与Float不能直接相加
- 禁止隐式转换:** 避免意外行为,需显式类型转换
特殊表达式
仓颉提供了一些特殊的表达式形式:
区间表达式:
1..10 // 包含1到10的整数区间
1..<10 // 包含1到9的区间
类型检查表达式:
x is Int // 检查x是否为Int类型
类型转换表达式:
x as? Int // 安全转换为Int,失败返回null
函数定义与使用
函数基本结构
仓颉中的函数定义使用func关键字:
func 函数名(参数列表): 返回类型 {
// 函数体
}
示例:
func add(a: Int, b: Int): Int {
return a + b
}
参数与返回值
参数特性:
- 必须显式指定参数类型
- 支持默认参数值
- 支持可变参数
- 支持命名参数调用
示例:
func greet(name: String, times: Int = 1) {
for i in 1..times {
println("Hello, ${name}!")
}
}
// 调用方式
greet("Alice") // 使用默认times=1
greet("Bob", times=3) // 显式指定times
返回值处理:
- 使用return语句返回值
- 函数体最后一个表达式的值可作为隐式返回值
- 无返回值时使用Unit类型(类似void)
函数类型与高阶函数
仓颉中函数是一等公民,具有函数类型:
(参数类型1, 参数类型2) -> 返回类型
这使得函数可以作为参数传递或作为返回值:
// 高阶函数示例
func applyOperation(a: Int, b: Int, op: (Int, Int) -> Int): Int {
return op(a, b)
}
let sum = applyOperation(5, 3, { x, y => x + y }) // 结果为8
函数重载
仓颉支持函数重载,即同一作用域内同名函数可以有多个实现:
func max(a: Int, b: Int): Int { a > b ? a : b }
func max(a: Double, b: Double): Double { a > b ? a : b }
重载规则:
- 函数名相同
- 参数类型或数量不同
- 返回类型不参与重载决策
控制结构
条件表达式
仓颉提供if作为表达式使用:
let result = if x > 0 {
"positive"
} else {
"non-positive"
}
循环结构
while循环:while condition {
// 循环体
}
for循环:for item in collection {
// 处理每个item
}
模式匹配
match表达式提供强大的模式匹配能力:
match value {
case 0 => println("Zero")
case 1..10 => println("1 to 10")
case "hello" => println("Greeting")
case _ => println("Other")
}
变量与常量
变量声明
仓颉使用var声明可变变量:
var count = 0
count += 1 // 允许修改
常量声明
使用let声明不可变常量:
let pi = 3.14159
// pi = 3.14 // 错误:不能修改常量
类型推断
仓颉编译器可以推断变量类型:
let name = "Alice" // 推断为String
let age = 30 // 推断为Int
结语
仓颉编程语言的基础概念体系设计精巧而实用,从标识符命名到程序组织,从表达式求值到函数定义,每个环节都体现了语言设计者对开发效率和运行效率的平衡考量。掌握这些基础概念是深入学习仓颉语言的前提,也是编写高质量仓颉代码的基础。
通过本文的系统介绍,读者应该已经对仓颉语言的基本构成要素有了全面的了解。在实际开发中,建议结合官方文档和示例代码进一步练习,以巩固对这些基础概念的理解和应用能力。仓颉语言作为一门新兴的编程语言,其简洁的语法和强大的表达能力必将为开发者带来全新的编程体验。

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐

 1
1 0
0- 0



 已为社区贡献214条内容
已为社区贡献214条内容

所有评论(0)