【鸿蒙心迹】这个盛夏的“独家记忆”
这是三匹“下等马”用鸿蒙开发一路打怪、最终拿下ICDT显示算法冠军的故事

目录
一、第一次上手:零经验也能“有迹可循”
二、第一回撞墙:黑屏的罪魁祸首不是“图”,而是“通道”!
三、自适应缩放的真相:我们或许都想简单了?
四、我有一个梦想:把2秒打到5毫秒:GPU 并行的意义,不只是“更快”
五、晋级与对手:初赛第一的喜讯,与“浙大+上交”的压力
六、三十天冲刺:把“能用”做成“好用、想用、喜欢用”!
七、练秋湖的夜,今晚我们是角儿!
八、尾声
一位刚刚申博、仍在迷雾中找寻方向;一位临近毕业、项目压身;一位考研失意、却不肯认输。我们在 3 月第一次看见ICDT赛题,抱着“试试看”的心态入坑鸿蒙NEXT开发。随后是密集的试错与复盘:从门外看热闹,到摸到门把手,再到真正推开门……这段旅程充满了挑战与收获,也教会了我们全力以赴面对自己要做的每一件事,更教会了我们自信勇敢地站在台上去展示我们的作品。每一遍的debug尝试,每一次自我质疑与自我否定,每一个深夜的坚持,都成为了我与鸿蒙共同成长的珍贵记忆。
一、第一次上手:零经验也能“有迹可循”
第一次打开鸿蒙NEXT开发者平台的窘迫情形至今仍然历历在目:工程怎么起?配置怎么配?.json5、.json、.ets、.d.ts是干嘛用的?庆幸的是,开发者官网像一张清晰的路书:API文档、示例工程、最佳实践,一条条指路。我们遵循“先跑通”的最短路径,系统梳理资料,购入Mate70作为实验机,先把脚手架与地基搭牢,让工程活起来,再谈后续的“摩天大楼”。感谢开发者官网,让每一项想用的技术都有迹可循。

二、第一回撞墙:黑屏的罪魁祸首不是“图”,而是“通道”!
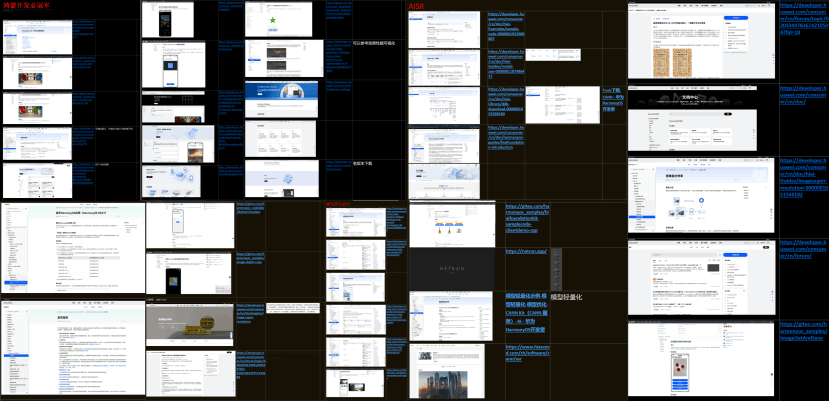
前期开发我们团队的目标很朴素:前端发图到后端,后端原样回传到前端显示。结果屏幕一片黑。我们把日志拉满、逐行断点,才找到原因:虽然输入是RGB三通道,但鸿蒙系统在后端处理和生成图像时统一转成RGBA四通道,其中A通道是Alpha透明度。我们只写了RGB,A没写255,后果便是前端渲染时整张图成了“黑画面”。

而我们所采用的解决办法也很简单:1.上传纹理时统一用GL_RGBA/GL_UNSIGNED_BYTE;2.片元着色器里把FragColor = vec4(val.rgb, 1.0); 强制把 alpha 写满,因此这条路径绕开了透明度坑。
这一系列操作完成之后,黑屏消失了,第一次显现出图片了,但新猫图又“变色”——橙猫成了蓝猫,在短暂的激动和兴奋过后,我们知道我们离最终答案很近了,这是经典R/B通道对调事故,在很多链路(Windows/NativeBuffer)里,实际给到的是BGRA或BGRX,统一输入为RGBA,并在必要处启用BGRA扩展,通道才彻底对上。
三、自适应缩放的真相:我们或许都想简单了?
赛题需要横竖屏自适应。我们一开始以为“横就横向撑满,竖就竖向撑满”即可,很快就被一些极端长宽比的图片打脸。在两个通宵的debug后发现了两条铁律:
它是需要时刻判断当前当前终端状态和当前的图像尺寸数据,自适应的核心是需要时刻比较“图像纵横比”和“设备纵横比”,通过分支逻辑不管横竖,都遵守“等比缩放”:只放大/缩小其中一个维度,另一个维度按比例求出,保证不变形、不裁切。
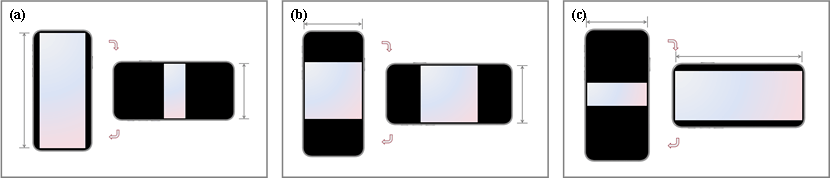
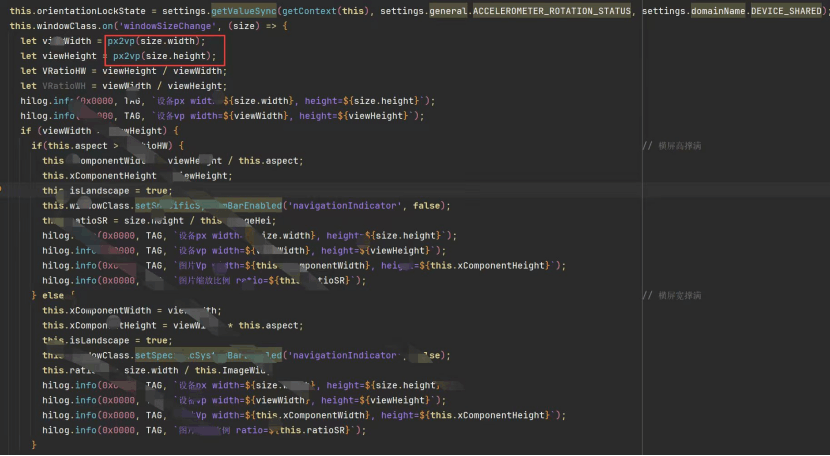
当然,这个问题的解决还顺带解决了之前困扰我已久的一个问题:为什么前端开发的时候我写一个像素会改变多个像素,关键就是这个px2vp函数,简单来说就是:
px2vp把物理像素(px,和硬件分辨率一一对应)换算成设备无关的虚拟像素(vp,保证不同DPI上“视觉尺寸”一致)。几何判断、控件尺寸统一在vp世界,纹理、FBO、Shader计算留在px世界。正是这份“角色分工”,让横竖屏/沉浸式/等比缩放在不同终端上都稳定可预期。
四、我有一个梦想:把2秒打到5毫秒:GPU 并行的意义,不只是“更快”
在我们用CPU跑通了初版超分算法后,虽然效果像样,但1k大图处理时延达将近2s,大幅度超过了赛题要求的“30Hz”门限,这让我们很是沮丧。我们将目光又回到了我们最初看的通过OpenGL或者Vulkan进行加速GPU加速渲染的方法,该方法是否适用我们的算法?如何适合如何移植?以及如果尝试之前的东西相当于全盘推翻?这些问题成了我们前进道路上最深的阴霾。
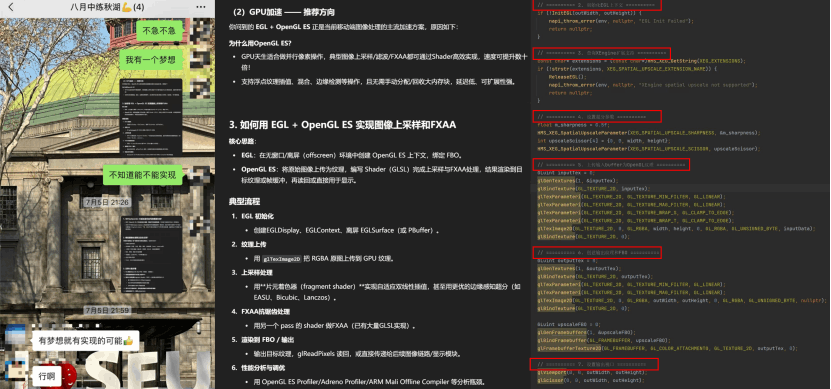
我们本着“不破不立”的想法开始了尝试,后来的结果证明我们的想法是正确的:基于 OpenGL ES + Shader 的并行通路,把插值与增强“搬进GPU”。前端通过 NAPI 触发统一的GpuUpscale接口,完成:图像上传→Shader插值/增强→FBO离屏渲染→结果落盘;最终这个加速方案在1k 2x超分场景中耗时5ms,1k 4x超分耗时小于14ms,远低于赛题30Hz门限,相比我们初赛的CPU版本,1k超分速度提升约320倍,充分满足端侧高分辨率高帧率的实时处理需求。
五、晋级与对手:初赛第一的喜讯,与“浙大+上交”的压力
材料卡点提交后,我们没有“坐等消息”,而是用一个月继续打磨。七月传来两条新闻:我们以初赛第一晋级练秋湖决赛;但决赛对手是浙江大学与上海交通大学,其中一队还是卫冕冠军。我们清楚地知道:唯有在鸿蒙NEXT体验与性能上拉开代差,才有资格谈“冠军”。
六、三十天冲刺:把“能用”做成“好用、想用、喜欢用”
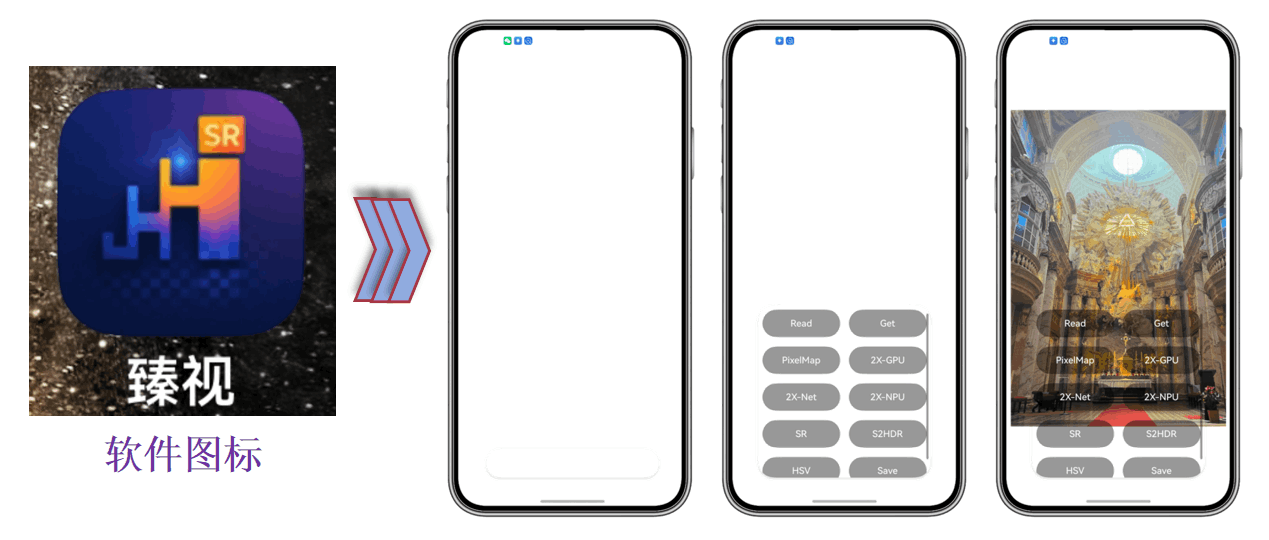
前端,我们推翻了繁杂的显示,做成沉浸式界面:核心画面全权让位,抽拉式/悬浮式控件只在“需要时出现”。
算法,我们一周内连续迭代近20个版本:最终通过优化显示算法并结合人眼视觉感知特性,创新性的提出了基于结构感知和感知增强融合的超分辨率算法,并基于昇腾 AI CANN 做高效部署与推理。
性能上,OpenGL ES 并行渲染把端侧时延打到“肉眼体感不到”的量级,使得未来1k 120Hz图像超分成为了可能。作品终于具备了“评委难以拒绝的理由”。
七、练秋湖的夜,今晚我们是角儿!

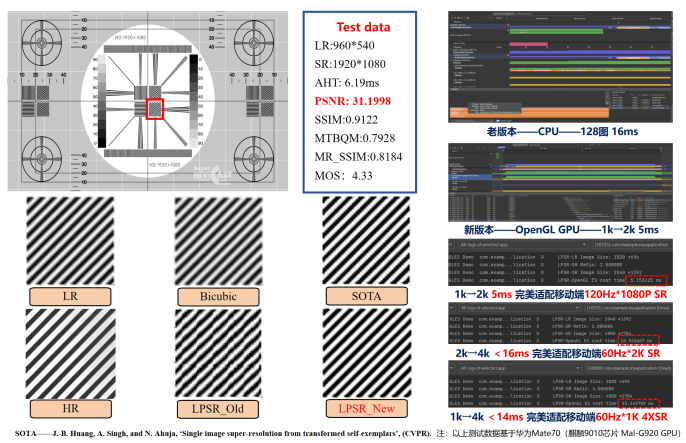
八月中,在华为练秋湖,我们交付的不只是一套能跑的方案,而是一段从问题到方案、从方案到体验、从体验到指标的完整闭环。最后,我们捧起了2025 ICDT显示算法冠军。那刻回头看,日志里每一条报错、每一次崩溃、每一行被我们改掉的代码,都在证书上留下了看不见的签名。下面也附上一张我们移动终端图像超分的效果图:
八、尾声
这个夏天,“浪浪山的小妖怪”很火,我们也算是把自己最好的九十天留在了这个夏天。还记得评委赞许我们的获奖感言讲得这么好,因为这一幕在我心里已经演绎了成百上千遍。
这两日南京清晨与傍晚的凉风,好似在宣告着2025盛夏的落幕;而我们的鸿蒙之旅才刚刚揭幕——应用上架、创新赛、星光计划、极客……更好的机会与更大的舞台正在招手。最后我以一张我们团队的合照和浪浪山中最后一句台词作为结尾“敬每一个勇敢出发的自己。也敬每一次不体面的小失败,它们共同把我们推到了台上!”


讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐

 11
11 3
3- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)