HarmonyOS第一课——HarmonyOS Intelligence与AI能力开放会给我们带来什么样的价值
前言
HarmonyOS第一课中的首席专家讲鸿蒙课程中HarmonyOS Intelligence与AI能力开放课程中对Harmony Intelligence的整体技术架构以及HarmonyOS的AI子系统进行了深入的讲解,这是一个非常有价值的课程,毕竟后续我们会在AI领域上创建无数的APP应用,我们来一起学习一下其中的HarmonyOS AI的部分,下面我们的仔细的观看一下本节课程。

HarmonyOS AI
HarmonyOS AI的开放能力列表如下如:
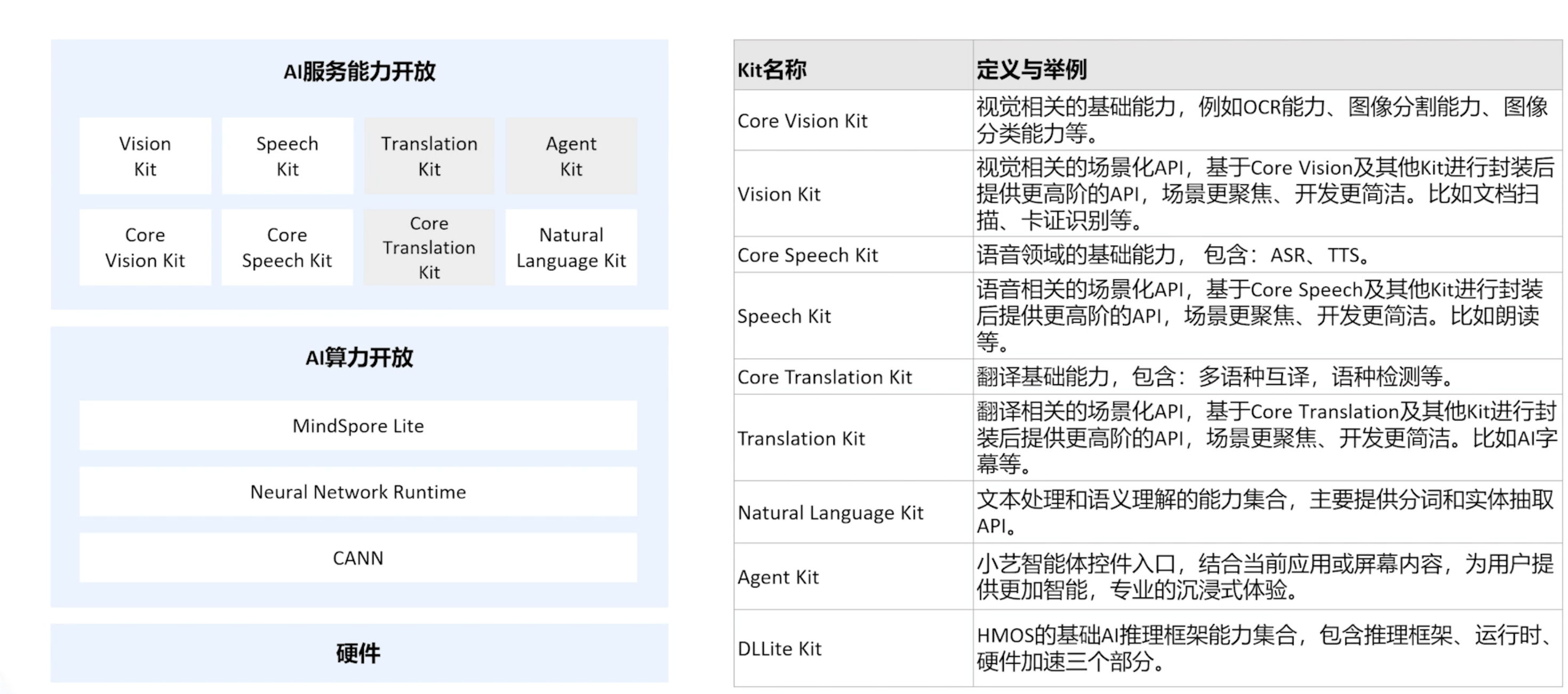
可以说每个模块都能为我们所用,在应用开发中可以给到我们很大的帮助。
以视觉为例,我们通过Core Vision Kit和Viseion Kit两层对我们开发者开放,Core Vision Kit提供了原子化的能力,像OCR、图像分割分类等能力。
Vision Kit提供了场景化能力,包括人脸的活体检测、对比及动作验证等一系列的能力组合,使用的时候是带有UI交互能力的。
算力层提供了MindSpore Lite合NRT两层开发接口,分别对应模型推理框架合神经网络运行,后续开会逐步开放更多的能力,比如翻译,且Harmony Intelligence是一个系统集成领域智能体协同架构,这里边的应用智能体是以生态伙伴为去构建的,这样的话这些智能体面向一些特定领域能提供领域内更专业或更强的能力。
其中的Agent Kit说是未来会给我们开发者们开放。
HarmonyOS AI服务能力开放分层:原子化能力与场景化能力
刚才提到Vision Kit提供了识图的能力,其组合了Core Vision Kit几乎所有的API,包括OCR、主体分隔、多目标识别、人脸检测,也包括自然语言处理等等能力,且还叠加了长按、菜单响应、底部栏的汽包推荐拖拽等等这些UI交互的能力。

只要集成了这个控件来展示图片,不论是哪个应用,用户的交互体验都是一致的,都可以自由的选择图片中的文字来复制或分享,甚至是翻译,OCR识别出来的信息抽取后还可以做实质上的推荐。
API调用逻辑
这里给我们提供了很多的接口对接方式,因为要考虑AI的处理数据方式与能力,所以在下方可以看到有多重类型的接口接入方法,让我们可以更加顺畅的完成接口数据处理。
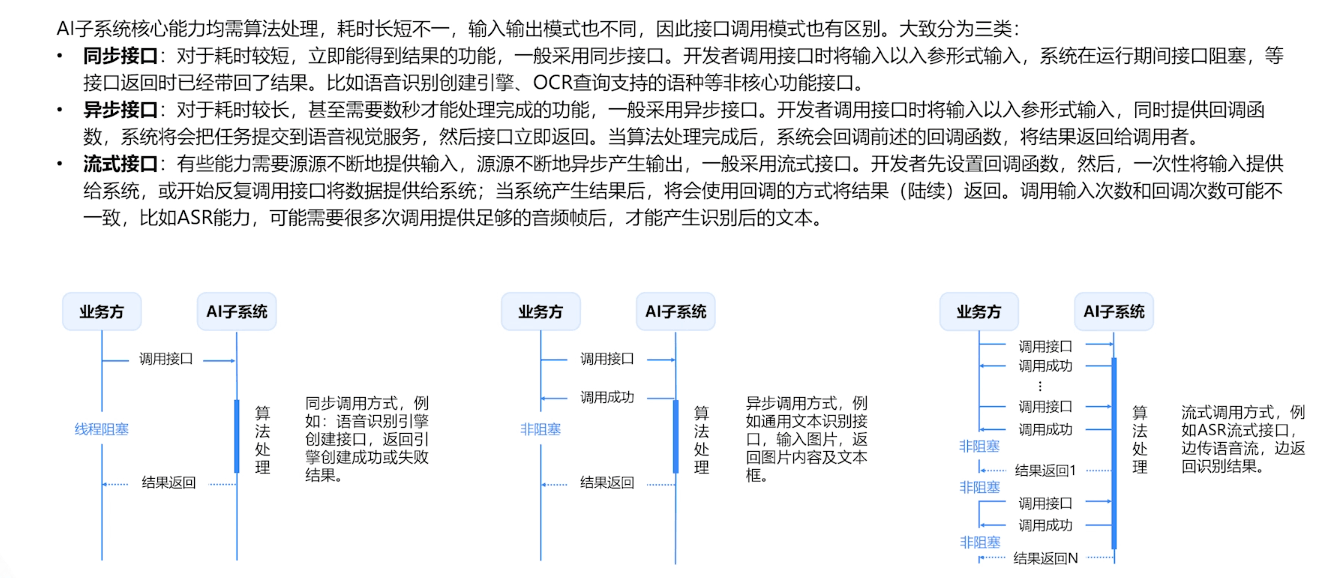
HarmonyOS AlKit使用示例
Core Speech Kit功能:Core speechKit(基础语音服务)集成了语音类基础A!能力,包括文本转语音(TextToSpeech)及语音识别(SpeechRecognizer)能力,便于用户与设备进行互动,实现将实时输入的语音与文本之间相互转换。

Core SpeechKit 语音识别API使用说明
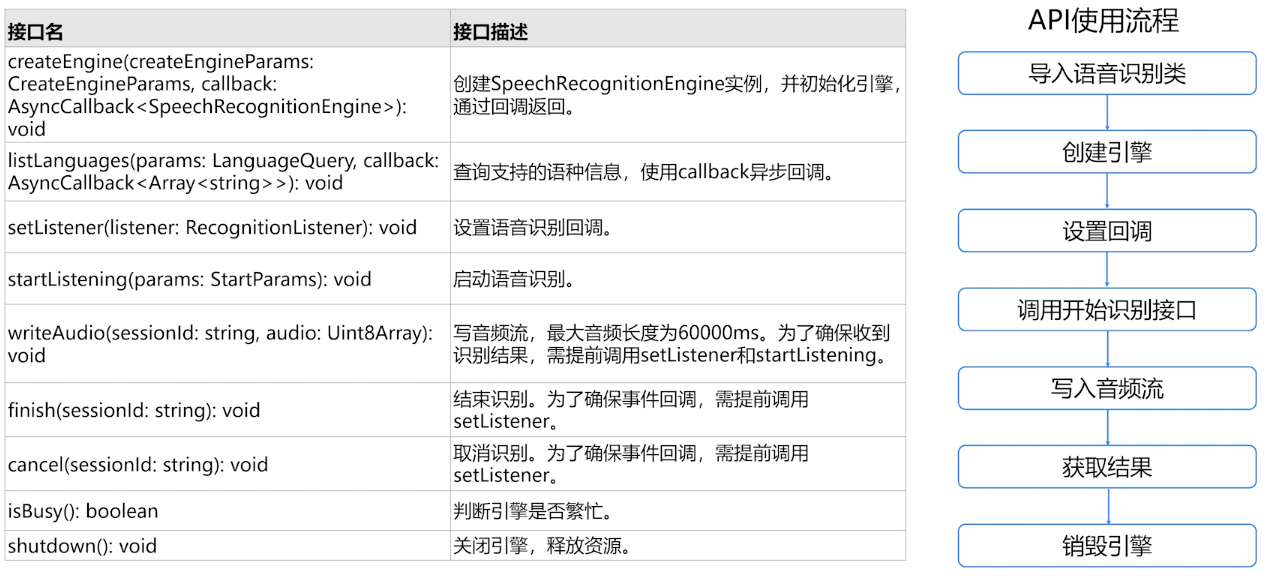
具体开发流程示例
在使用语音识别时,将实现语音识别相关的类添加至工程,使用的库内容:
import {speechRecognizer } from '@kit.CorespeechKit';
import {BusinessError ) from '@kit.BasicServiceskit'创建语音识别引擎,并初始化。
let asrEngine:speechRecognizer.speechRecognitionEngine;
let sessionId:string='123456';
//创建引擎,通过callback形式返回
/!设置创建引擎参数
let extraParam:Record<string,Object>={'locate':'CN''recognizerMode':'short'};
let initParamsInfo:speechRecognizer.CreateEngineParams= {
language:'zh-CN',
online:1,
extraParams:extraParamt
}
//调用createEngine力法
speechRecognizer.createEngine(initParamsInfo.(err: BusinessError,SpeechRecognitionEngine: speechRecognizer,speechRecognitionEngine)=>
if(!err){
console.info('Succeeded in creating engine.');
// 接收创建引警的实例
asrEngine =speechRecognitionEngine;
}else{
console.error( Failed to create engine. Code: ${err.code}, message:${err.message}.);
}
});设置回调,用于接收识别结果、事件及相关错误。
// 创建回调对象
let setListener:speechRecognizer.RecognitionListener=
// 开始识别成功回调
onstart(sessionId:string,eventMessage:string)
console.info( onstart, sessionId:${sessionId} eventMessage: $feventMessage} );
// 事件回调onEvent(sessionId:string,eventcode:number, eventMessage: string){
console. info( onEvent, sessionId: ${sessionId) eventcode: $feventcode} eventMessage: $feventMessage} );
// 识别结果回调,包括中间结果和最终结果onResult(sessionId: string, result: speechRecognizer.SpeechRecognitionResult)
console.info( onResult,sessionId:${sessionId) sessionId: ${IsoN.stringify(result)} );
// 识别完成回调
onComplete(sessionId:string,eventMessage:string){
console.info(`oncomplete, sessionId:${sessionId} eventMessage: ${eventMessage}`);
/ 错误回调,错误码通过本方法返回
//返回错误码100220002,开始识别失败,重复启动startListening方法时触发1 更多错误码请参考错误码参考
onError(sessionId: string,errorcode: number, errorMessage: string){
console.error( onError, sessionId: $fsessiond errorcode: $ferrorcode} errorMessage: $ferrorMessage );
// 设置回调
asrEngine.setListener(setListener);调用识别接口开始识别:
// 开始识别
private startListeningForWriteAudio(){
// 设置开始识别的相关参数
let recognizerParams:speechRecognizer.startParams=sessionId:this.sessionId,audioInfo:{audioType:'pcm',sampleRate: 16000,soundchannel:1,sampleBit:16
//调用开始识别方法
asrEngine.startListening(recognizerParams);写入音频流
let buf: ArrayBuffer = new ArrayBuffer(1280);
let offset:number=0;
while(1280 ==fileIo.readsync(file.fd, buf,{
offset: offset
})){
let uint8Array:Uint8Array =new Uint8Array(buf);
asrEngine.writeAudio(this.sessionId,uint8Array);
await this.countDownLatch(1);
offset = offset + 1280;
}关闭语音识别引擎,释放资源。
// 结束识别
asrEngine.finish(sessionId)
// 取消识别
asrEngine.cancel(sessionId);
// 释放语音识别引擎资源asrEngine.shutdown();例如按照TTS的逻辑就是按照这个流程来的
总结
专家角度就是不一样,是直接从很高的架构上说明,在具体的落地,很好的视频,学到了很多,并且也知道后面会开放更多的AI开放能力,对我们开发者们真是福利满满啊。
更多精彩内容,请关注公众号:【名称:HarmonyOS开发者技术,ID:HarmonyOS_Dev】;也欢迎加入鸿蒙开发者交流群:https://work.weixin.qq.com/gm/48f89e7a4c10206e053e01ad124004a0

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 0
0 0
0- 0



 已为社区贡献170条内容
已为社区贡献170条内容

所有评论(0)