XXL-JOB分布式任务调度框架(二)-策略详解
任务调度是指系统为了自动完成特定任务,在约定的特定时刻去执行任务的过程。有了任务调度即可解放更多的人力,而是由系统自动去执行任务。XXL-JOB是一个开源的,具有丰富的任务管理功能以及高性能,高可用等特点的轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展、开箱即用!!!于2015问世,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产

文章目录
1.引言
本篇文章承接上文《XXL-JOB分布式任务调度框架(一)-基础入门》,上一次和大家简单介绍了下 xxl-job 的由来以及使用方法,本篇文章将会详细介绍一些高级使用方法及特性。
上文中我们在新建一个任务的时候发现有很多的选项,现在我们来详细聊一聊他们的作用。
)
2.任务详解
2.1.执行器
执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能;
另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器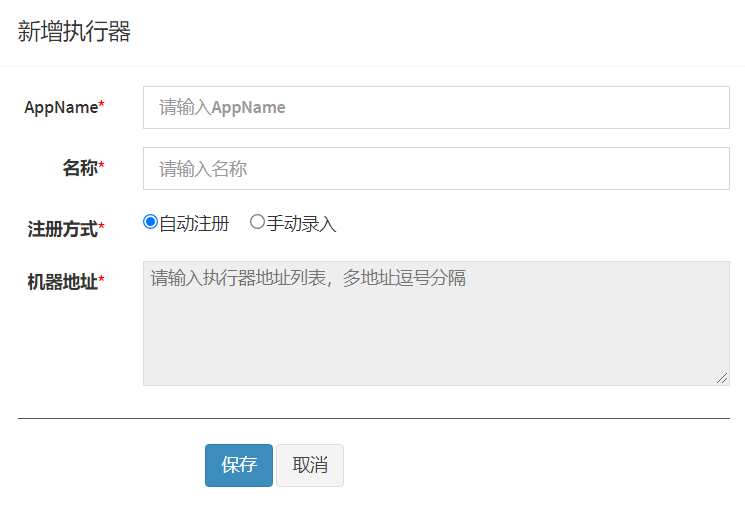
2.2.基础配置
-
执行器:每个任务必须绑定一个执行器, 方便给任务进行分组。任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 “执行器管理” 进行设置
-
任务描述:任务的描述信息,便于任务管理
-
报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔;
-
负责人:任务的负责人;

-
调度类型
- 无:该类型不会主动触发调度;
- CRON:该类型将会通过CRON,触发任务调度;
- 固定速度:该类型将会以固定速度,触发任务调度;按照固定的间隔时间,周期性触发;

-
运行模式:

-
BEAN模式:以JobHandler方式维护在执行器端;需要结合 “JobHandler” 属性匹配执行器中任务;
-
GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 “groovy” 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
-
GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “shell” 脚本;
-
GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “python” 脚本;
-
GLUE模式(PHP):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “php” 脚本;
-
GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “nodejs” 脚本;
-
GLUE模式(PowerShell):以源码方式维护在调度中心;该模式的任务实际上是一段 “PowerShell” 脚本;
-
JobHandler:运行模式为 “BEAN模式” 时生效,对应执行器中新开发的
JobHandler类“@JobHandler”注解自定义的value值; -
执行参数:任务执行所需的参数;
-
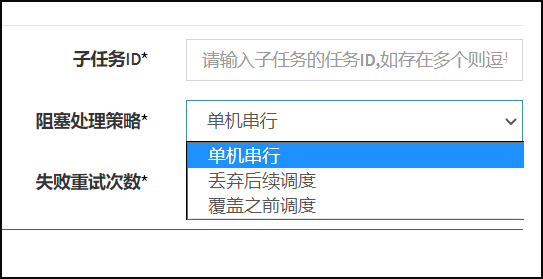
阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
- 单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
路由策略:当执行器集群部署时,提供丰富的路由策略
路由策略是指一个任务可以由多个执行器完成,那具体由哪一个完成呢,这就要看我们指定的路由策略了,这个参数当执行器做集群部署的时候才有意义。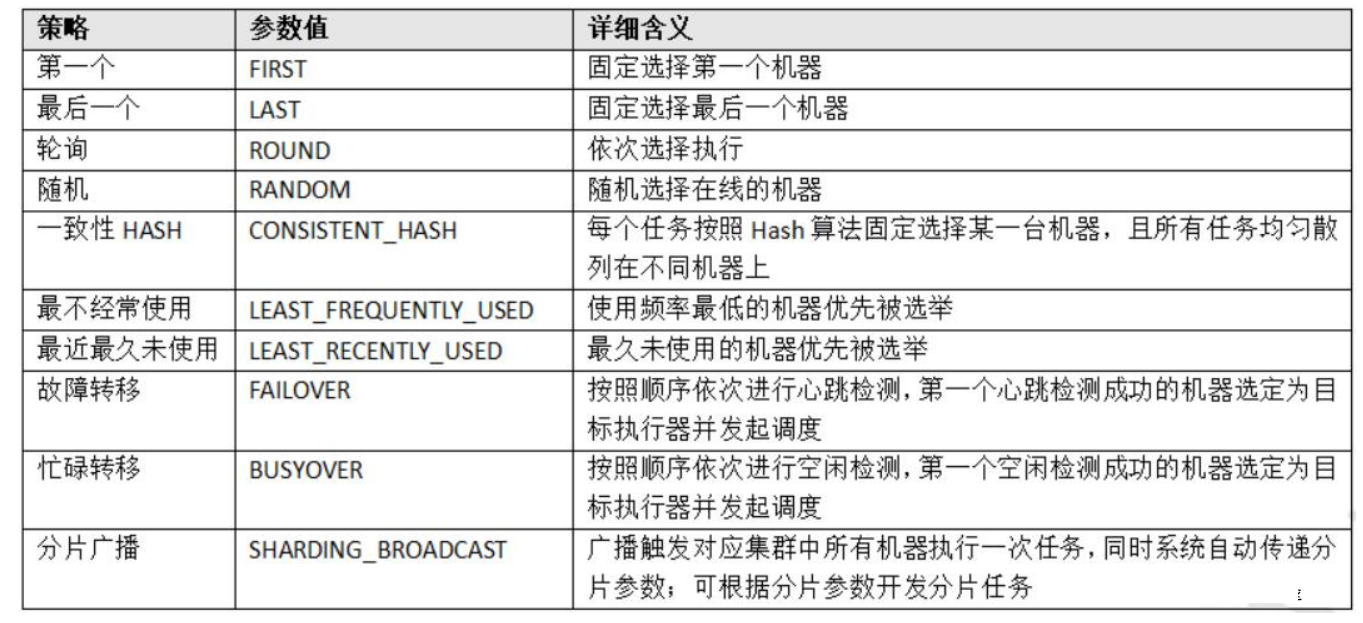
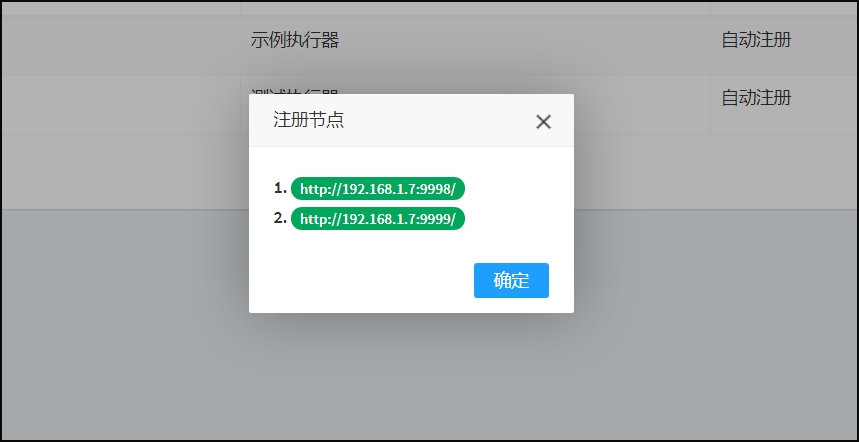
那么这里的第一个,最后一个是按什么顺序来的呢,就是点击查看-注册节点中的1,2,3,4,第一个指的就是1,最后一个指的就是4。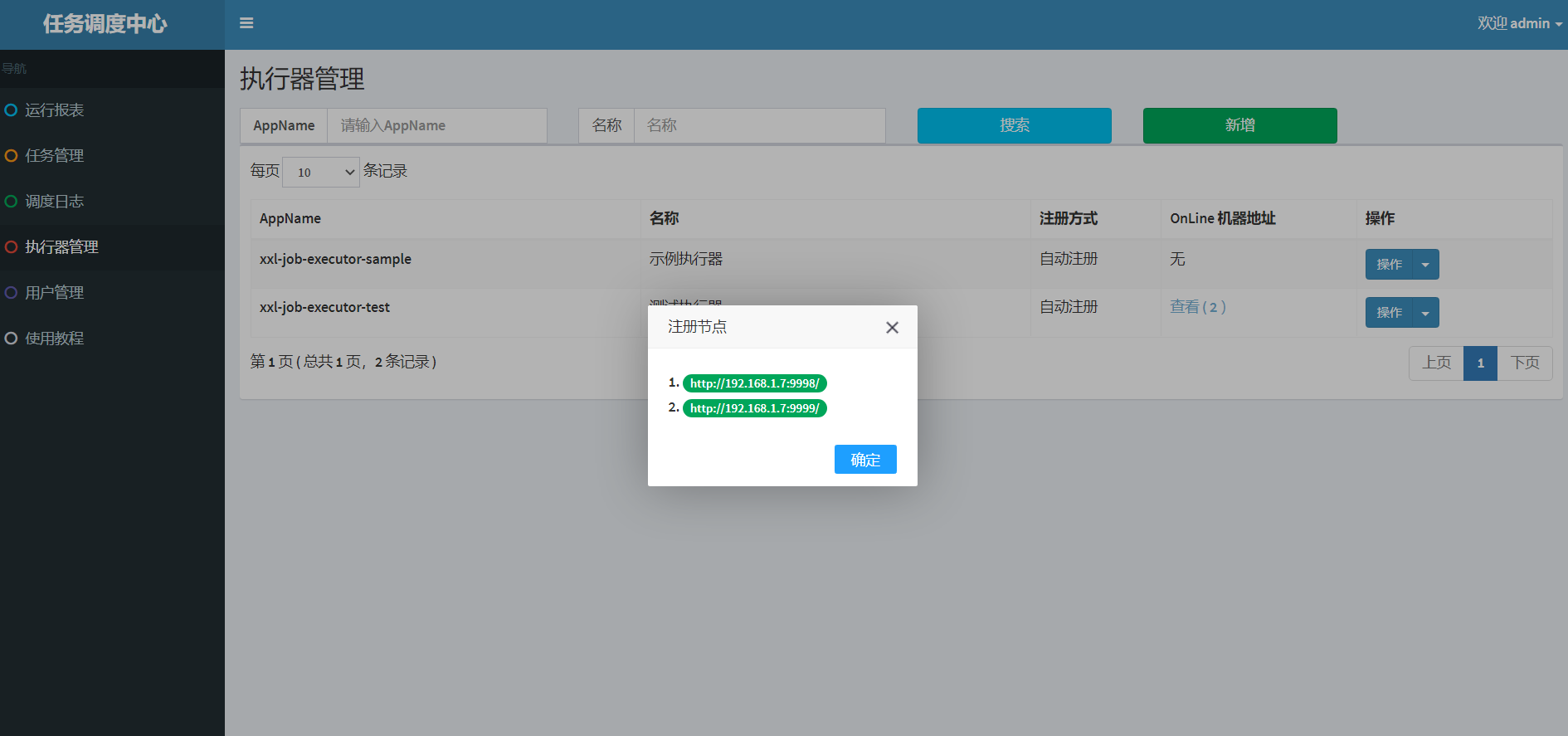

-
子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
-
任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
-
失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
3.路由策略(第一个)-案例
源码:
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.List;
/**
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteFirst extends ExecutorRouter {
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList){
return new ReturnT<String>(addressList.get(0));
}
}
看代码就很容易理解,获取当前传入的执行器的注册地址集合的第一个。
执行器部署集群
配置路由规则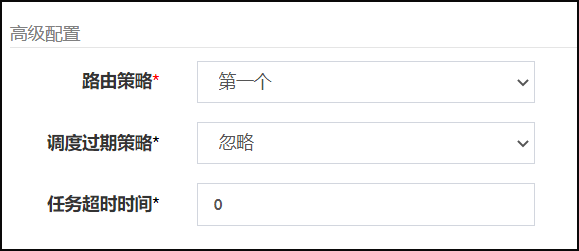
任务执行效果:第一个执行器执行任务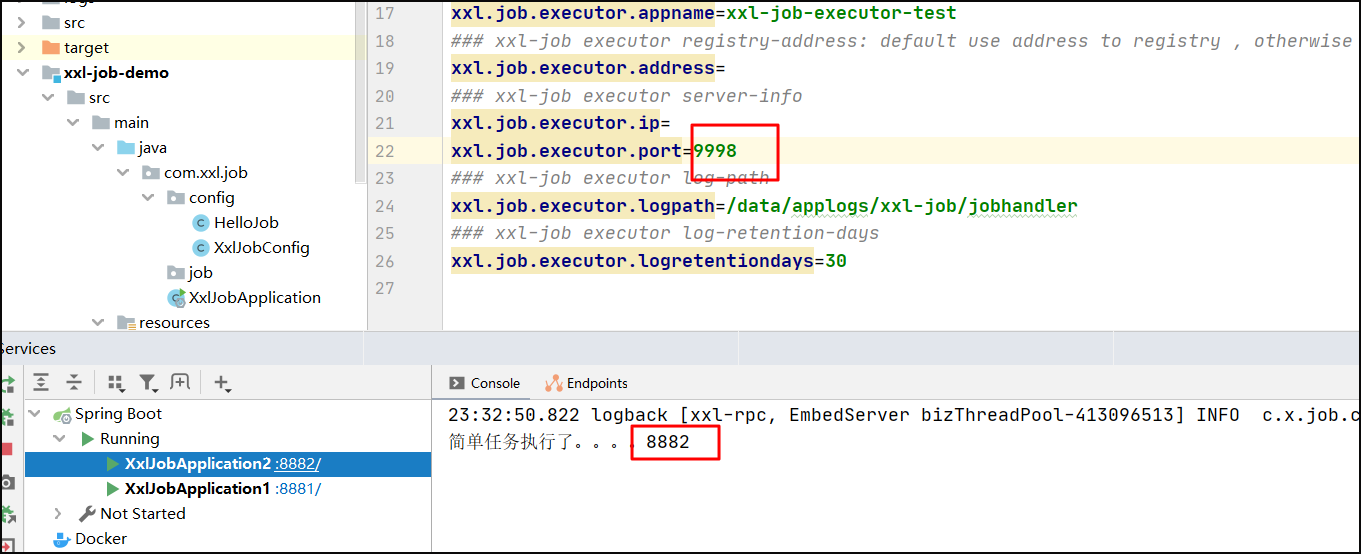
4.路由策略(最后一个)-案例
源码:
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.List;
/**
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteLast extends ExecutorRouter {
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
return new ReturnT<String>(addressList.get(addressList.size()-1));
}
}
这个也很容易理解,选取当前传入得执行器的注册地址集合的最后一个,下标从0开始 最后一个为addressList.size()-1
执行器部署集群
配置路由规则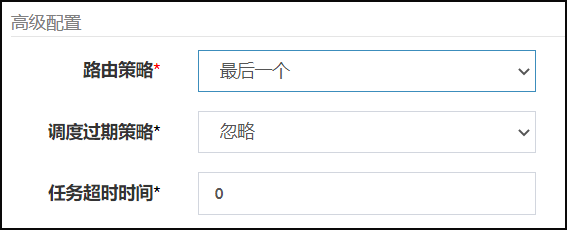
任务执行效果:最后一个执行器执行任务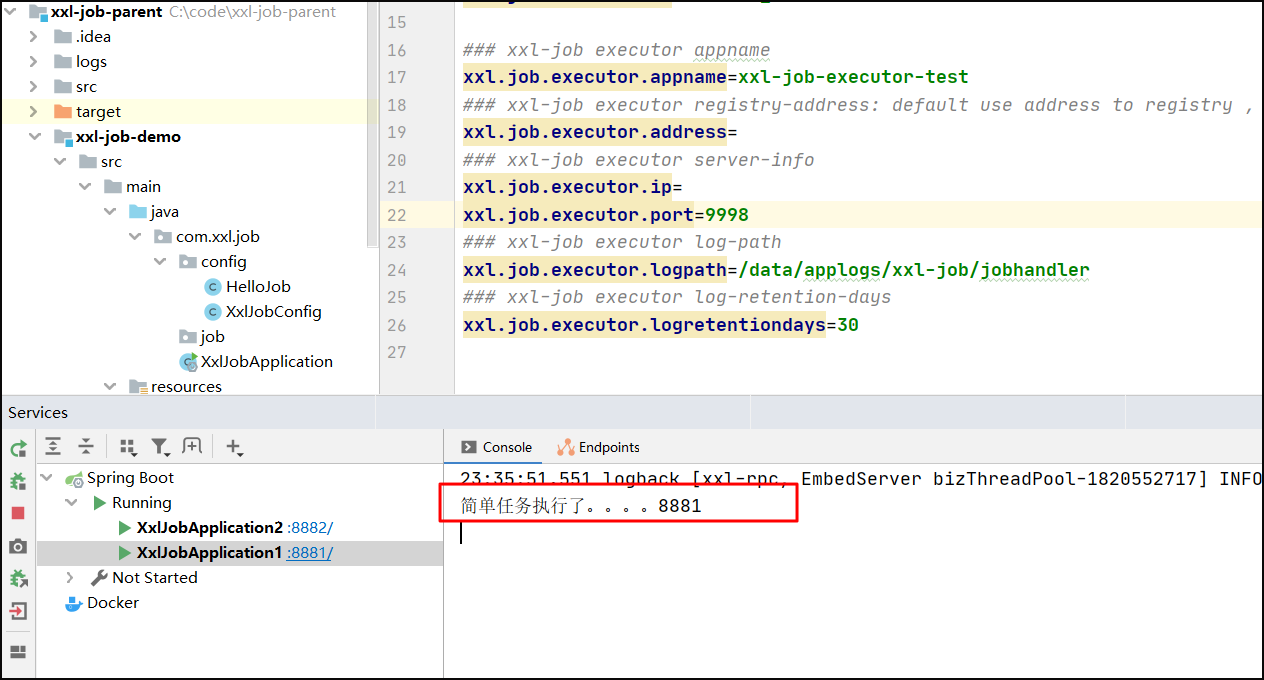
5.轮询策略-案例
执行器部署集群
配置路由规则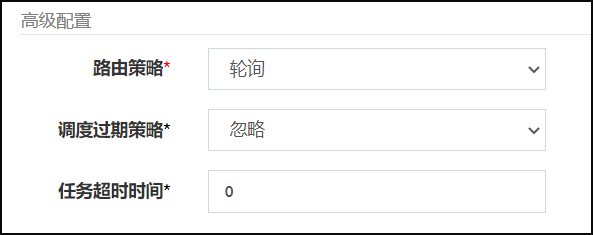
任务执行效果:轮询执行任务(一共执行4次,各执行2次)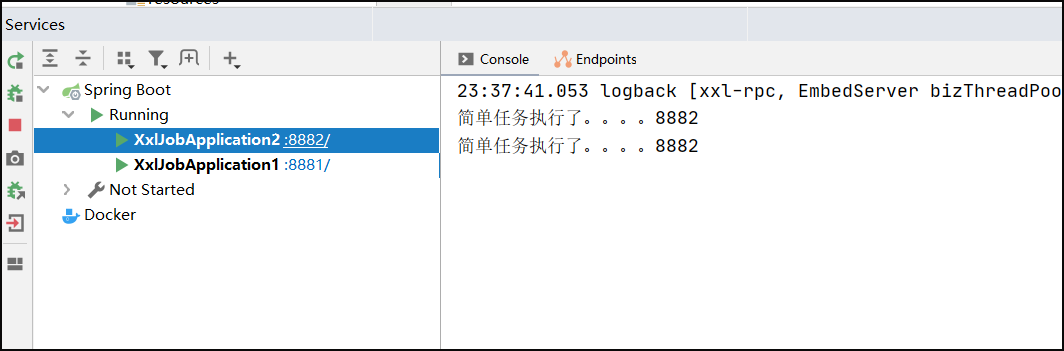
6.随机选取
源码:
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.List;
import java.util.Random;
/**
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteRandom extends ExecutorRouter {
private static Random localRandom = new Random();
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
String address = addressList.get(localRandom.nextInt(addressList.size()));
return new ReturnT<String>(address);
}
}
整个算法核心部分就是通过一个Random对象的nextInt方法在求出[0,addressList.size())区间内的任意一个地址
7.轮询选取
源码:
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.IntStream;
/**
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteRound extends ExecutorRouter {
private static ConcurrentMap<Integer, AtomicInteger> routeCountEachJob = new ConcurrentHashMap<>();
private static long CACHE_VALID_TIME = 0;
private static int count(int jobId) {
// cache clear
if (System.currentTimeMillis() > CACHE_VALID_TIME) {
routeCountEachJob.clear();
CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;
}
AtomicInteger count = routeCountEachJob.get(jobId);
if (count == null || count.get() > 1000000) {
// 初始化时主动Random一次,缓解首次压力
count = new AtomicInteger(new Random().nextInt(100));
} else {
// count++
count.addAndGet(1);
}
routeCountEachJob.put(jobId, count);
return count.get();
}
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
String address = addressList.get(count(triggerParam.getJobId())%addressList.size());
return new ReturnT<String>(address);
}
}
这里注意到创建了一个静态的ConcurrentMap对象,这个routeCountEachJob就是用来存放路由任务的,而且还设置了缓存时间,有效期为24小时,当超过24小时的时候,自动的清空当前的缓存。
其中ConcurrentMap的key为jobId,value为当前jobId所对应的计数器,每访问一次就自增一,最大增到100000,然后又从[0,100)的随机数开始重新自增。
这个算法的思想就是取余数,每次先计算出当前jobId所对应的计数器的值,然后 计数器的值 % addressList.size() 求得这一次轮询的地址。
8.一致性hash
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.io.UnsupportedEncodingException;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* 分组下机器地址相同,不同JOB均匀散列在不同机器上,保证分组下机器分配JOB平均;且每个JOB固定调度其中一台机器;
* a、virtual node:解决不均衡问题
* b、hash method replace hashCode:String的hashCode可能重复,需要进一步扩大hashCode的取值范围
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteConsistentHash extends ExecutorRouter {
private static int VIRTUAL_NODE_NUM = 100;
/**
* get hash code on 2^32 ring (md5散列的方式计算hash值)
* @param key
* @return
*/
private static long hash(String key) {
// md5 byte
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5 not supported", e);
}
md5.reset();
byte[] keyBytes = null;
try {
keyBytes = key.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("Unknown string :" + key, e);
}
md5.update(keyBytes);
byte[] digest = md5.digest();
// hash code, Truncate to 32-bits
long hashCode = ((long) (digest[3] & 0xFF) << 24)
| ((long) (digest[2] & 0xFF) << 16)
| ((long) (digest[1] & 0xFF) << 8)
| (digest[0] & 0xFF);
//通过md5算出的hashcode % 2^32 余数,将hash值散列在一致性hash环上 这个环分了2^32个位置
long truncateHashCode = hashCode & 0xffffffffL;
return truncateHashCode;
}
public String hashJob(int jobId, List<String> addressList) {
// ------A1------A2-------A3------
// -----------J1------------------
TreeMap<Long, String> addressRing = new TreeMap<Long, String>();
for (String address: addressList) {
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
//为每一个注册的节点分配100个虚拟节点,并算出这些节点的一致性hash值,存放到TreeMap中
long addressHash = hash("SHARD-" + address + "-NODE-" + i);
addressRing.put(addressHash, address);
}
}
//第二步求出job的hash值 通过jobId计算
long jobHash = hash(String.valueOf(jobId));
//通过treeMap性质,所有的key都按照从小到大的排序,即按照hash值从小到大排序,通过tailMap 求出>=hash(jobId)的剩余一部分map,
SortedMap<Long, String> lastRing = addressRing.tailMap(jobHash);
if (!lastRing.isEmpty()) {
//若找到则取第一个key,为带路由的地址
return lastRing.get(lastRing.firstKey());
}
//若本身hash(jobId)为treeMap的最后一个key,则找当前treeMap的第一个key
return addressRing.firstEntry().getValue();
}
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
String address = hashJob(triggerParam.getJobId(), addressList);
return new ReturnT<String>(address);
}
}
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
为什么要引入这个算法那,这个算法就是为了解决目前分布式所存在的问题,举个例子:
现在我们有三台Redis服务器,假设编号为0,1,2,每台服务器都缓存了当前最热门的商品详情信息,我们的映射规则是按照 hash(商品的id)%(redis服务器数量)的结果来映射到某一台编号的redis服务器中,
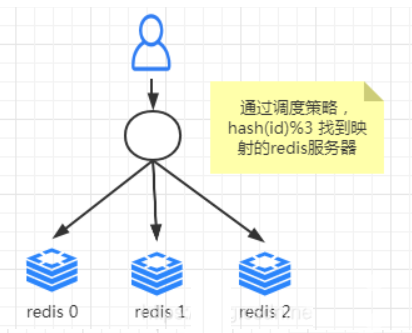
但是突然由于有一天公司商品越来越多,客户流量也越来越大,三台服务器扛不住怎么办啊,那我们就加一台服务器,那么服务器数量就发生了变动,那肯定我们的取余数这个算法重新计算映射的编号就发生了变动,很容易造成大面积缓存失效,造成缓存雪崩,
把所有请求都请求到后端数据库,造成压力过大。为了解决这个问题,就引入了一致性hash算法,即服务节点的变更不会造成大量的哈希重定位。一致性哈希算法由此而生~。
这个一致性hash引入之后,若服务器节点数量过少,有几率出现数据倾斜的情况,既大量的数据映射到某一区间,其它区间没有数据映射,造成了资源分配不均匀,为了解决这个问题,xxl-job源码引入了虚拟节点,既将每台服务器的节点都生成所对应的100个虚拟节点,这应少量的服务器节点通过引入虚拟节点,就会加大节点的数量,这样大量的节点分配到hash环上是比较均匀的,从而很容易的解决数据分配不均匀问题。
9.最不经常使用 (LFU)
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
/**
* 单个JOB对应的每个执行器,使用频率最低的优先被选举
* a(*)、LFU(Least Frequently Used):最不经常使用,频率/次数
* b、LRU(Least Recently Used):最近最久未使用,时间
*
* 算法思想:
* 构建一个作业和地址map jobid -> addressList
* 第一次随机的将任务所对应的执行器的注册地址编一个序列号
* 然后将执行器的注册地址按照从小到大进行排序
* 筛选过程找第一个序列号最小的作为下一次的路由地址
* 随后将当前选中的地址编号值+1
* 这样最终我们都会挑选编号最小的注册器地址作为下一个路由地址,既最不常使用的
*
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteLFU extends ExecutorRouter {
private static ConcurrentMap<Integer, HashMap<String, Integer>> jobLfuMap = new ConcurrentHashMap<Integer, HashMap<String, Integer>>();
private static long CACHE_VALID_TIME = 0;
public String route(int jobId, List<String> addressList) {
// cache clear
if (System.currentTimeMillis() > CACHE_VALID_TIME) {
jobLfuMap.clear();
//有效缓存时间为一天
CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;
}
// lfu item init
HashMap<String, Integer> lfuItemMap = jobLfuMap.get(jobId); // Key排序可以用TreeMap+构造入参Compare;Value排序暂时只能通过ArrayList;
if (lfuItemMap == null) {
lfuItemMap = new HashMap<String, Integer>();
jobLfuMap.putIfAbsent(jobId, lfuItemMap); // 避免重复覆盖
}
// put new
for (String address: addressList) {
if (!lfuItemMap.containsKey(address) || lfuItemMap.get(address) >1000000 ) {
lfuItemMap.put(address, new Random().nextInt(addressList.size())); // 初始化时主动Random一次,缓解首次压力
}
}
// remove old
List<String> delKeys = new ArrayList<>();
for (String existKey: lfuItemMap.keySet()) {
if (!addressList.contains(existKey)) {
delKeys.add(existKey);
}
}
if (delKeys.size() > 0) {
for (String delKey: delKeys) {
lfuItemMap.remove(delKey);
}
}
// load least userd count address
List<Map.Entry<String, Integer>> lfuItemList = new ArrayList<Map.Entry<String, Integer>>(lfuItemMap.entrySet());
Collections.sort(lfuItemList, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
Map.Entry<String, Integer> addressItem = lfuItemList.get(0);
String minAddress = addressItem.getKey();
addressItem.setValue(addressItem.getValue() + 1);
return addressItem.getKey();
}
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
String address = route(triggerParam.getJobId(), addressList);
return new ReturnT<String>(address);
}
}
10.最近最久未使用(LRU)
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
/**
* 单个JOB对应的每个执行器,最久为使用的优先被选举
* a、LFU(Least Frequently Used):最不经常使用,频率/次数
* b(*)、LRU(Least Recently Used):最近最久未使用,时间
*
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteLRU extends ExecutorRouter {
private static ConcurrentMap<Integer, LinkedHashMap<String, String>> jobLRUMap = new ConcurrentHashMap<Integer, LinkedHashMap<String, String>>();
private static long CACHE_VALID_TIME = 0;
public String route(int jobId, List<String> addressList) {
// cache clear
if (System.currentTimeMillis() > CACHE_VALID_TIME) {
jobLRUMap.clear();
CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;
}
// init lru
LinkedHashMap<String, String> lruItem = jobLRUMap.get(jobId);
if (lruItem == null) {
/**
* LinkedHashMap
* a、accessOrder:true=访问顺序排序(get/put时排序);false=插入顺序排期;
* b、removeEldestEntry:新增元素时将会调用,返回true时会删除最老元素;可封装LinkedHashMap并重写该方法,比如定义最大容量,超出是返回true即可实现固定长度的LRU算法;
*/
lruItem = new LinkedHashMap<String, String>(16, 0.75f, true);
jobLRUMap.putIfAbsent(jobId, lruItem);
}
// put new
for (String address: addressList) {
if (!lruItem.containsKey(address)) {
lruItem.put(address, address);
}
}
// remove old
List<String> delKeys = new ArrayList<>();
for (String existKey: lruItem.keySet()) {
if (!addressList.contains(existKey)) {
delKeys.add(existKey);
}
}
if (delKeys.size() > 0) {
for (String delKey: delKeys) {
lruItem.remove(delKey);
}
}
// load
String eldestKey = lruItem.entrySet().iterator().next().getKey();
String eldestValue = lruItem.get(eldestKey);
return eldestValue;
}
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
String address = route(triggerParam.getJobId(), addressList);
return new ReturnT<String>(address);
}
}
11.故障转移
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.scheduler.XxlJobScheduler;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.admin.core.util.I18nUtil;
import com.xxl.job.core.biz.ExecutorBiz;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.List;
/**
* Created by xuxueli on 17/3/10.
* 故障转移路由策略
* 思想:遍历所有的该组下的所有注册节点地址集合,然后分别进行心跳处理,直到找到一个发送心跳成功的节点作为下一次路由的节点
*/
public class ExecutorRouteFailover extends ExecutorRouter {
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
StringBuffer beatResultSB = new StringBuffer();
for (String address : addressList) {
// beat
ReturnT<String> beatResult = null;
try {
ExecutorBiz executorBiz = XxlJobScheduler.getExecutorBiz(address);
beatResult = executorBiz.beat();
} catch (Exception e) {
logger.error(e.getMessage(), e);
beatResult = new ReturnT<String>(ReturnT.FAIL_CODE, ""+e );
}
beatResultSB.append( (beatResultSB.length()>0)?"<br><br>":"")
.append(I18nUtil.getString("jobconf_beat") + ":")
.append("<br>address:").append(address)
.append("<br>code:").append(beatResult.getCode())
.append("<br>msg:").append(beatResult.getMsg());
// beat success
if (beatResult.getCode() == ReturnT.SUCCESS_CODE) {
beatResult.setMsg(beatResultSB.toString());
beatResult.setContent(address);
return beatResult;
}
}
return new ReturnT<String>(ReturnT.FAIL_CODE, beatResultSB.toString());
}
}
这个算法很好理解,就是过滤所有故障的节点,找到一个健康节点运行任务,算法很简单,就是拿到节点的地址集合,然后一个个发心跳,若收到正常的心跳响应,则选择此节点作为执行任务的节点
12.忙碌转移
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.scheduler.XxlJobScheduler;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.admin.core.util.I18nUtil;
import com.xxl.job.core.biz.ExecutorBiz;
import com.xxl.job.core.biz.model.IdleBeatParam;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.List;
/**
* Created by xuxueli on 17/3/10.
* 忙碌转移
* 原理遍历所有的执行器,对所有执行器发送空闲心跳数据包
* 收集所有的返回信息,若当前机器繁忙则响应getCode==500 否则空闲则getCode==200
* 找到空闲的机器则返回该空闲机器的地址
*/
public class ExecutorRouteBusyover extends ExecutorRouter {
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
StringBuffer idleBeatResultSB = new StringBuffer();
for (String address : addressList) {
// beat
ReturnT<String> idleBeatResult = null;
try {
ExecutorBiz executorBiz = XxlJobScheduler.getExecutorBiz(address);
idleBeatResult = executorBiz.idleBeat(new IdleBeatParam(triggerParam.getJobId()));
} catch (Exception e) {
logger.error(e.getMessage(), e);
idleBeatResult = new ReturnT<String>(ReturnT.FAIL_CODE, ""+e );
}
idleBeatResultSB.append( (idleBeatResultSB.length()>0)?"<br><br>":"")
.append(I18nUtil.getString("jobconf_idleBeat") + ":")
.append("<br>address:").append(address)
.append("<br>code:").append(idleBeatResult.getCode())
.append("<br>msg:").append(idleBeatResult.getMsg());
// beat success
if (idleBeatResult.getCode() == ReturnT.SUCCESS_CODE) {
idleBeatResult.setMsg(idleBeatResultSB.toString());
idleBeatResult.setContent(address);
return idleBeatResult;
}
}
return new ReturnT<String>(ReturnT.FAIL_CODE, idleBeatResultSB.toString());
}
}
忙碌转移也很容易理解,就是发送idleBeat(空闲心跳包),检测当前机器是否空闲,怎么判断当前机器是否空闲那,
就是EmbedServer来处理这个请求,判断当前执行器节点是否执行当前任务或者当前执行器节点的任务队列是否为空,若既不是执行当前任务的节点或者任务队列为空则返回SUCCESS,以下代码就是上述所说。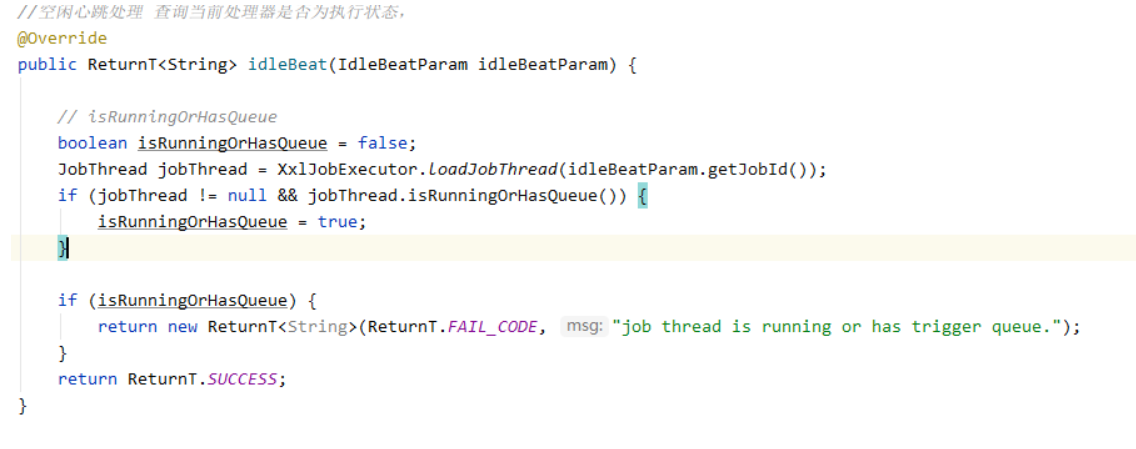
直到筛选出一个空闲节点为止,就选择当前空闲节点为下一个需要执行任务的节点
13.分片广播任务
执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务。
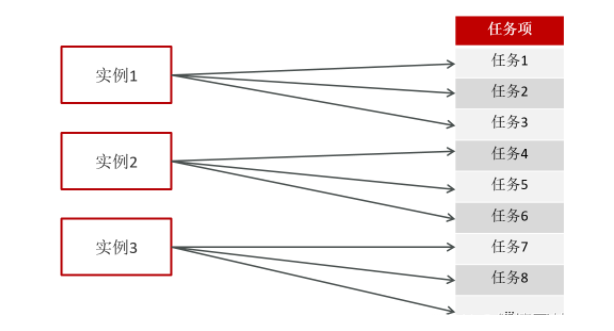
内部实现方式:如果有n个实例,那用任务项ID%n,由此来选择实例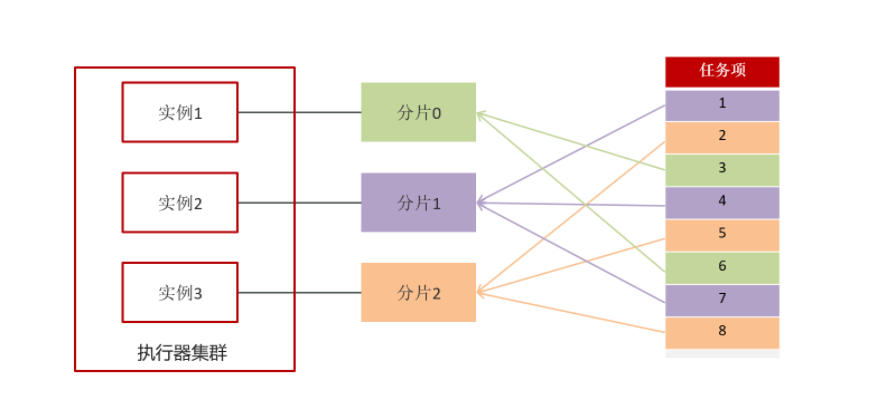
需求:让两个节点同时执行10000个任务,每个节点分别执行5000个任务
创建分片执行器:xxl-job-sharding-sample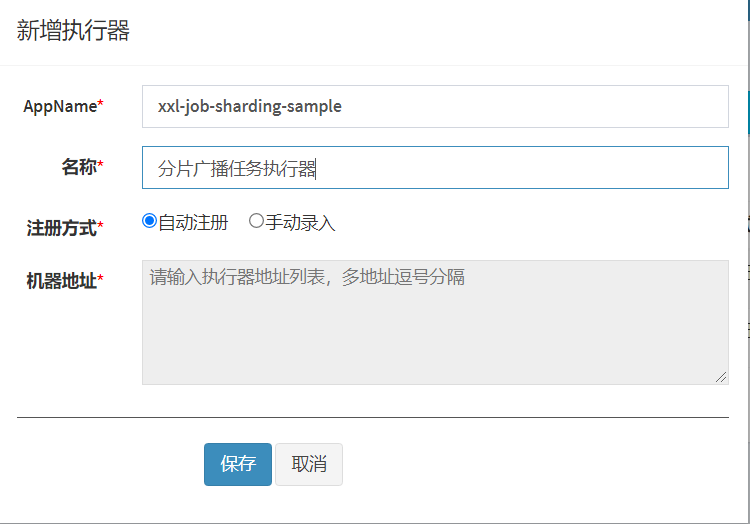
创建任务,路由策略指定为分片广播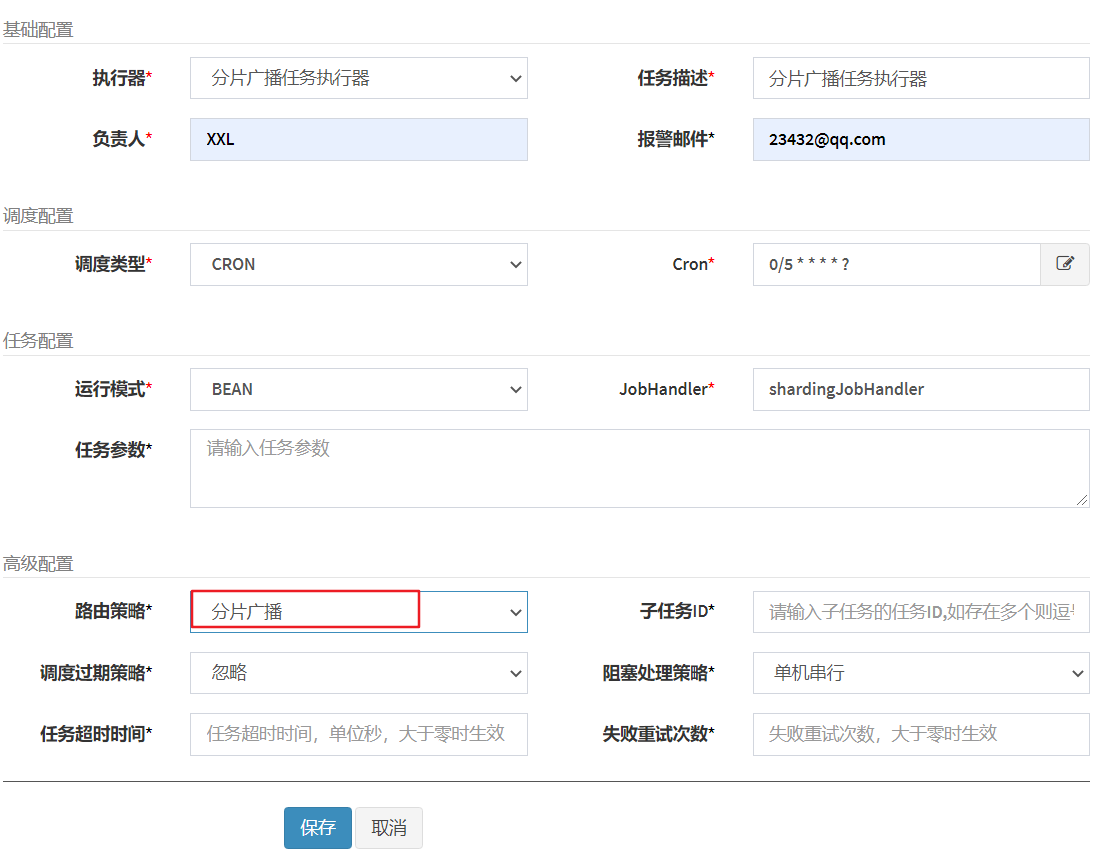
分片广播代码
- 分片参数
- index:当前分片序号(从0开始),执行器集群列表中当前执行器的序号;
- total:总分片数,执行器集群的总机器数量;
案例实现:
配置执行器的名称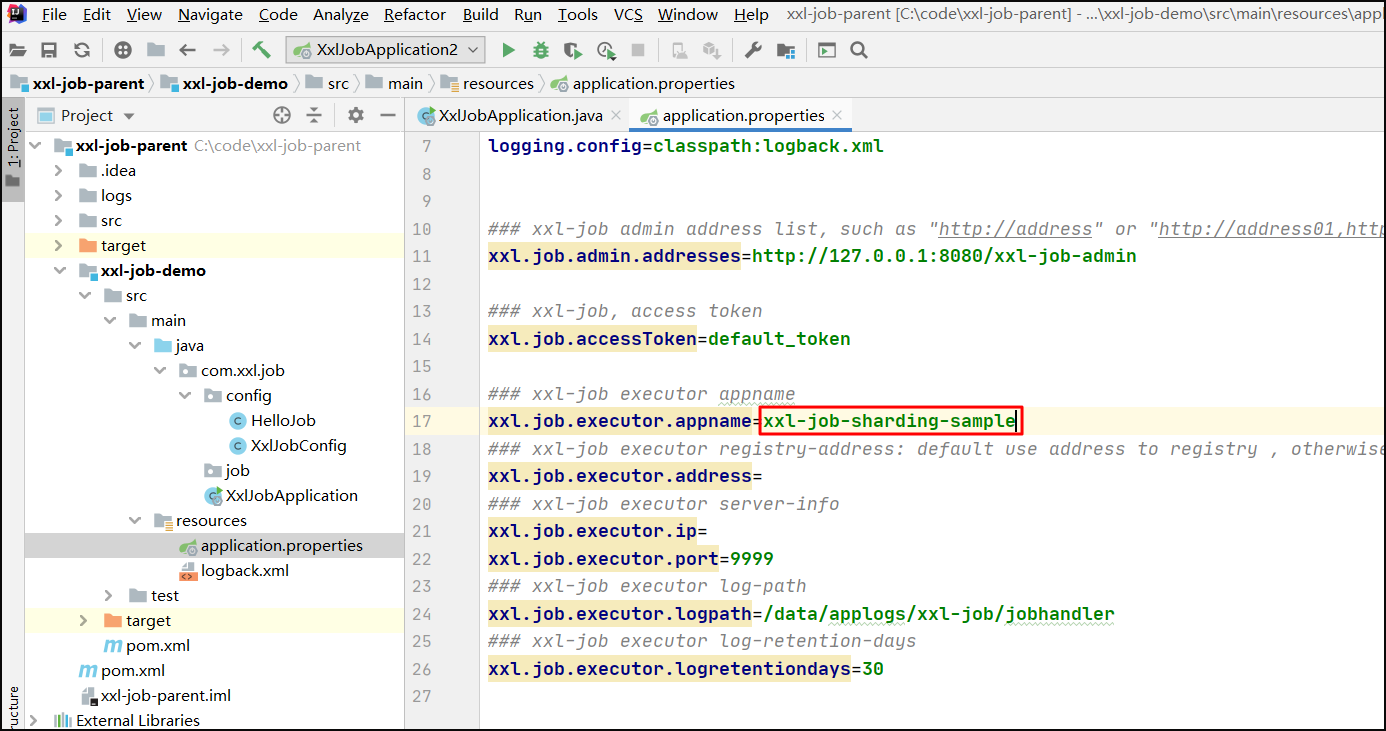
创建任务
package com.xxl.job.config;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
@Component
public class HelloJob1 {
@XxlJob("shardingJobHandler")
public void shardingJobHandler() {
//分片的参数
//1.当前分片序号(从0开始),执行器集群列表中当前执行器的序号;
int shardIndex = XxlJobHelper.getShardIndex();
//2.总分片数,执行器集群的总机器数量;
int shardTotal = XxlJobHelper.getShardTotal();
//业务逻辑
List<Integer> list = getList();
for (Integer integer : list) {
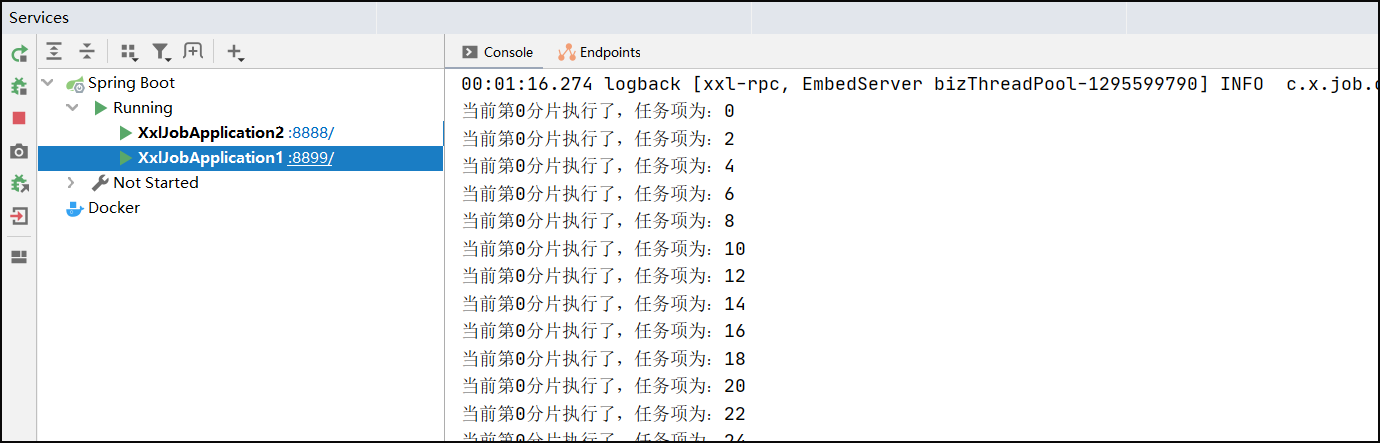
if (integer % shardTotal == shardIndex) {
System.out.println("当前第" + shardIndex + "分片执行了,任务项为:" + integer);
}
}
}
public List<Integer> getList() {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
list.add(i);
}
return list;
}
}
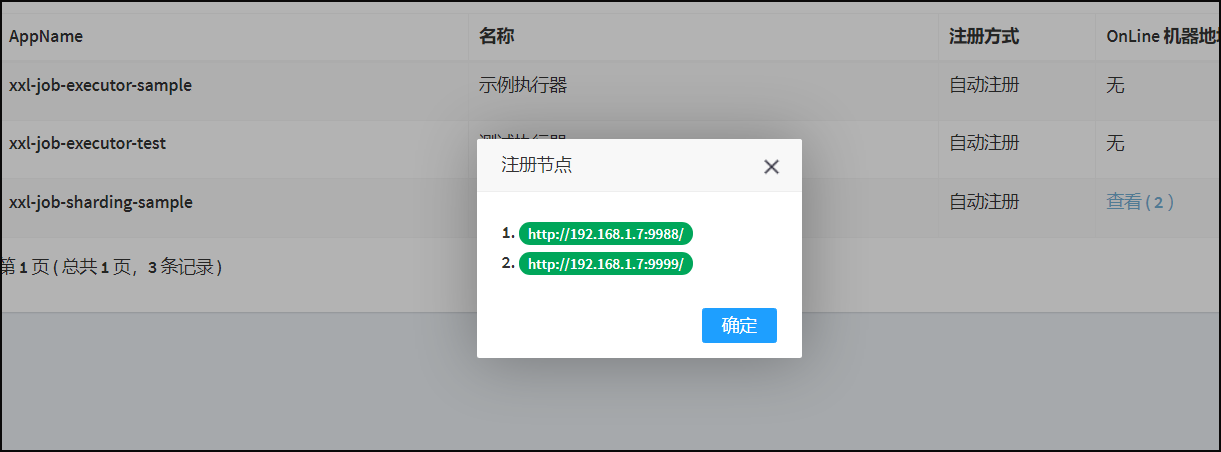
启动多个实例,进行测试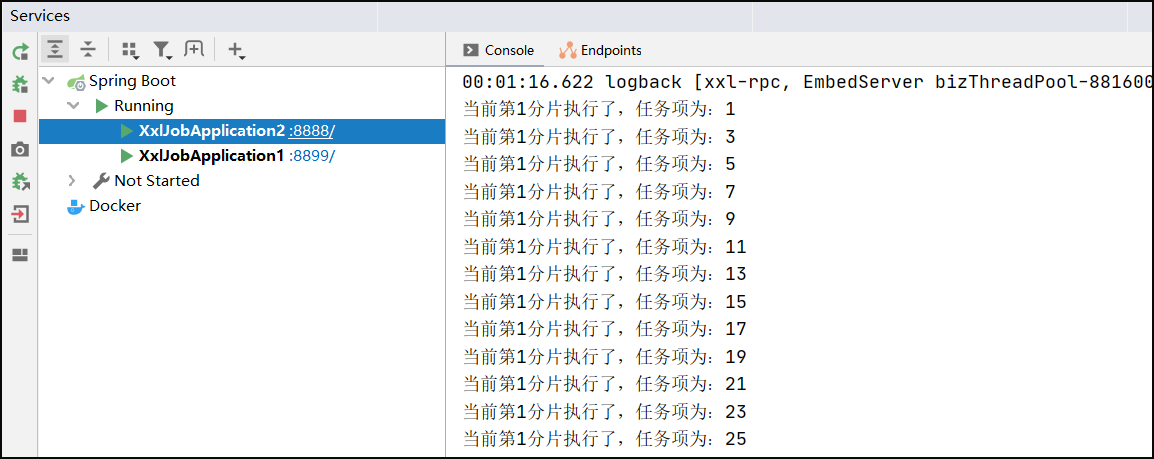
14.父子任务
父子任务,是指父任务执行后回自动调用子任务,完成一种类似于链式调用的调用,再使用时,只需要配置子任务的ID即可!
新建任务,在高级配置中子任务ID包含如下截图模式: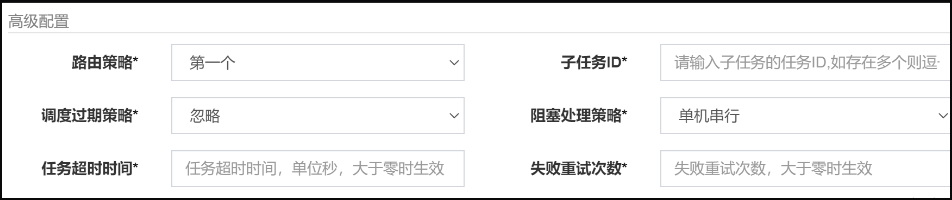
向定时任务,添加如下验证父子任务功能代码片段。
package com.xxl.job.config;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import groovy.util.logging.Slf4j;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class HelloJob2 {
/**
* 父子任务之父任务
*/
@XxlJob("fatherTask")
public ReturnT fatherTask(){
System.out.println("父任务执行");
return ReturnT.SUCCESS;
}
/**
* 父子任务之子任务
*/
@XxlJob("childTask")
public ReturnT childTask(){
System.out.println("子任务执行");
return ReturnT.SUCCESS;
}
}
打开Xxl-job 调度中心管理端。选择任务管理/新增父子任务。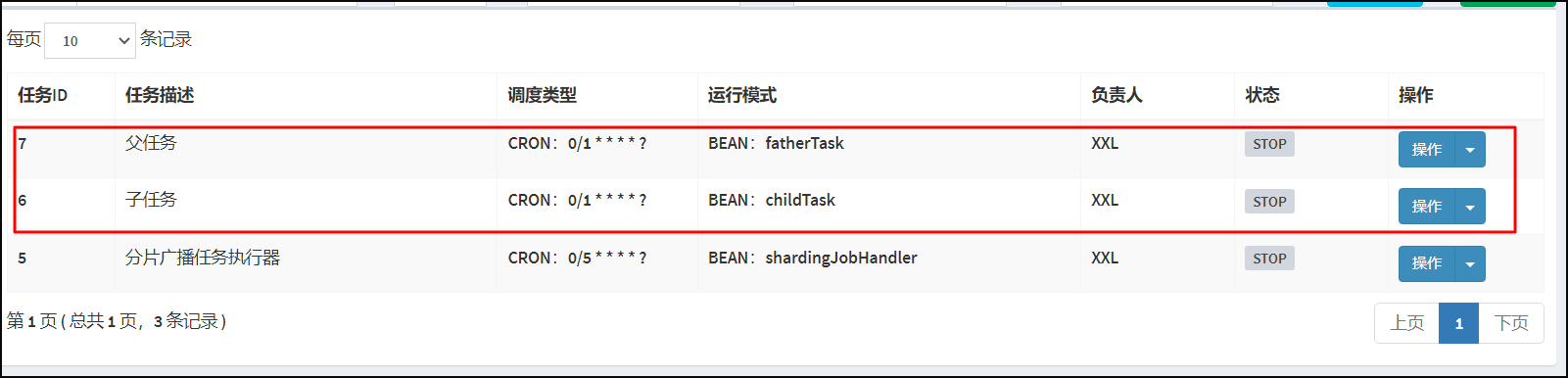
父任务关联子任务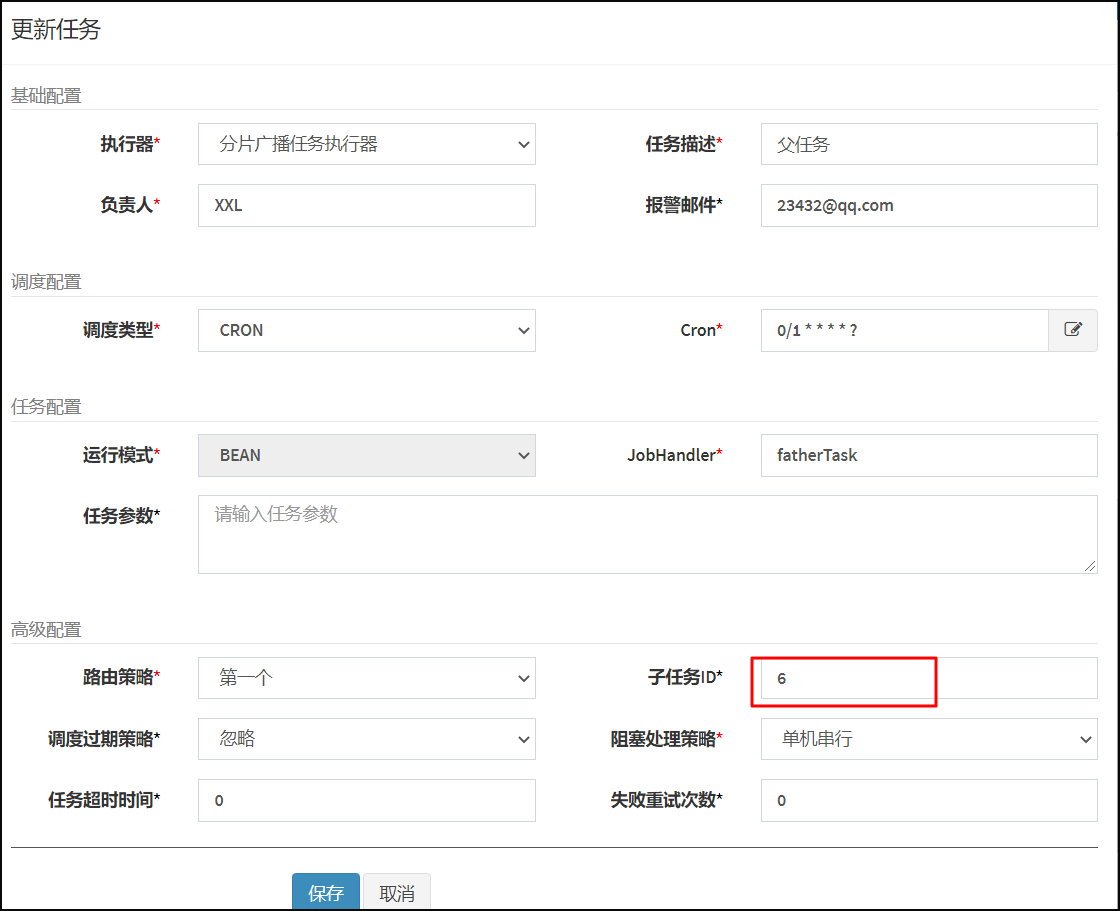
执行结果,执行父任务的时候,子任务自动执行: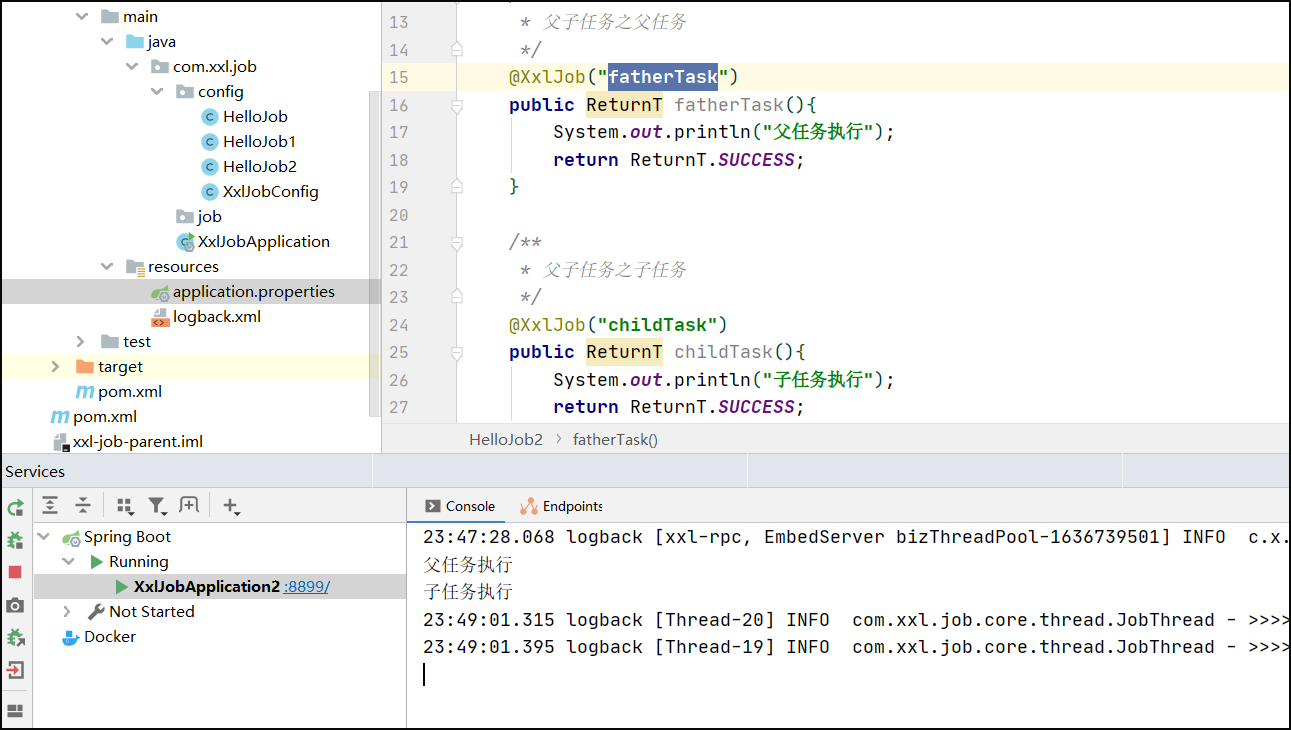
15.动态参数任务
xxl-job 支持动态的接受参数进行任务调度,调度器可以传指定参数给具体的任务,
具体任务接受调度参数后,进行相应的业务逻辑处理。
向定时任务,添加如下验证动态参数任务功能代码片段。
/**
* 动态参数任务
*/
@XxlJob("parameterTask")
public ReturnT parameterTask(){
logger.info("动态参数任务执行");
// 通过XxlJobHelper.getJobParam() 获取参数
String param = XxlJobHelper.getJobParam();
logger.info("参数值为:" + param);
return ReturnT.SUCCESS;
}
打开Xxl-job 调度中心管理端。选择任务管理/新增动态参数任务。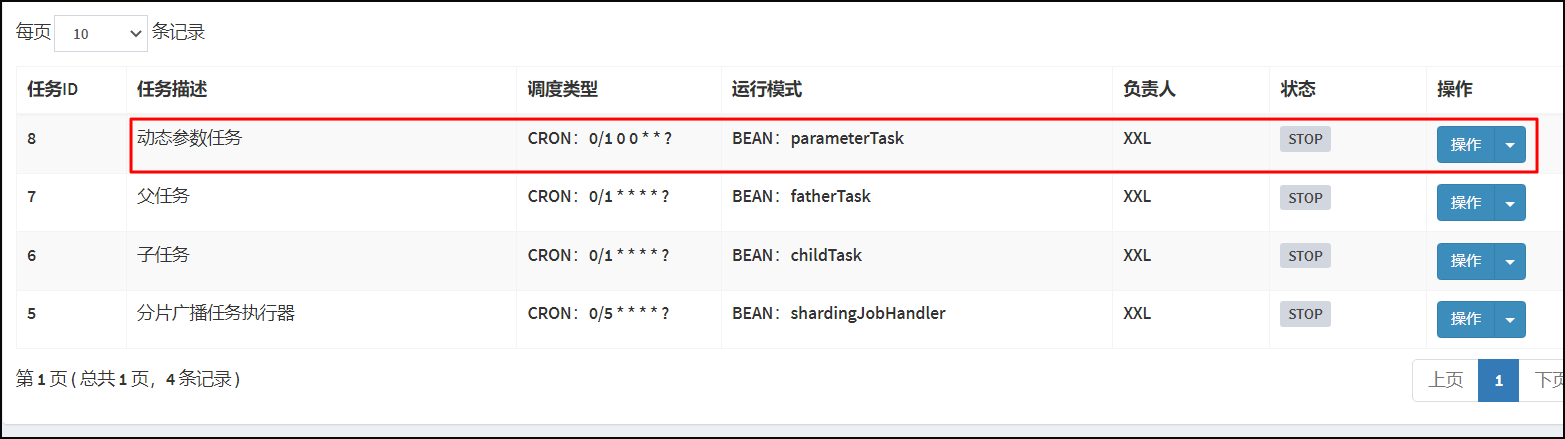
执行操作,选择仅执行一次,在任务参数中传入当前日期"2023-10-23"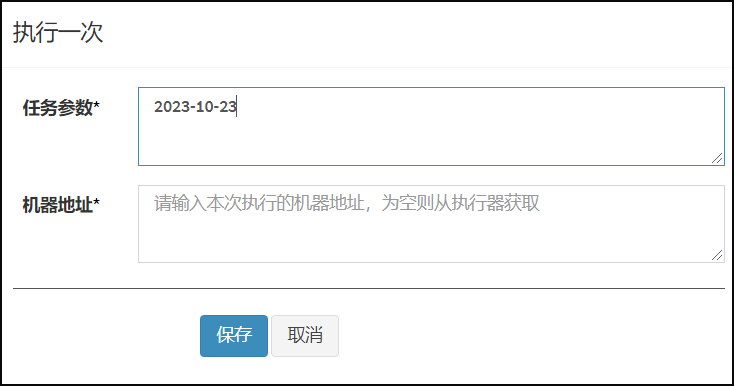
执行结果: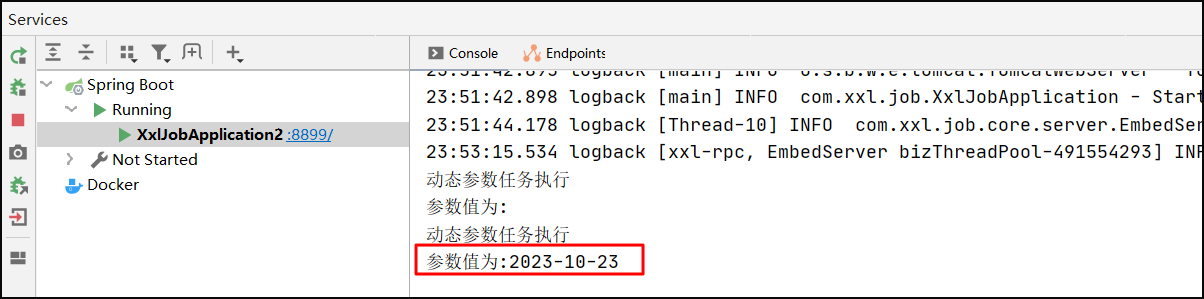
16.高级配置之日志回调
日志回调是指执行器在执行任务时可以将执行日志传递给调度中心,即使任务没有执行完成,调度中心也可以看到回调的调度日志内容,便于开发者能够更细化的分析任务的执行情况。
向定时任务,添加如下验证任务日志回调功能代码片段。
/**
* 任务日志回调
*/
@XxlJob(value = "logCallBackTask")
public ReturnT logCallBackTask() throws InterruptedException {
logger.info("任务日志回调执行");
XxlJobHelper.log("当前日志执行至{}行", 143);
Thread.sleep(3000);
XxlJobHelper.log("当前日志执行至{}行", 145);
Thread.sleep(3000);
XxlJobHelper.log("当前日志执行至{}行", 147);
return ReturnT.SUCCESS;
}
打开Xxl-job 调度中心管理端。选择任务管理/新增任务日志回调任务。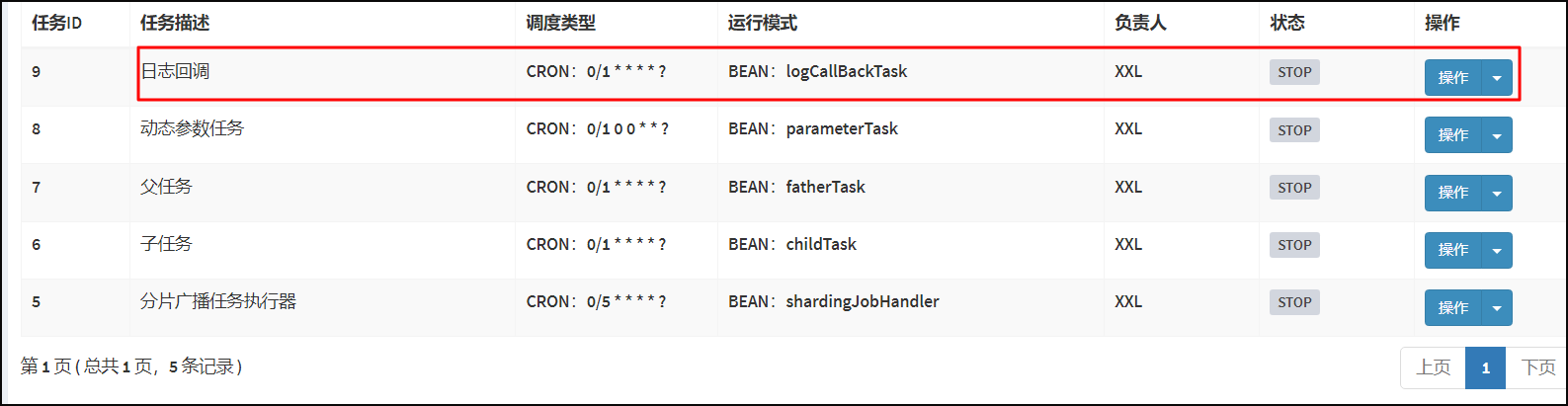
根据任务ID,将页面切换至调度日志,点击查询执行日志信息。
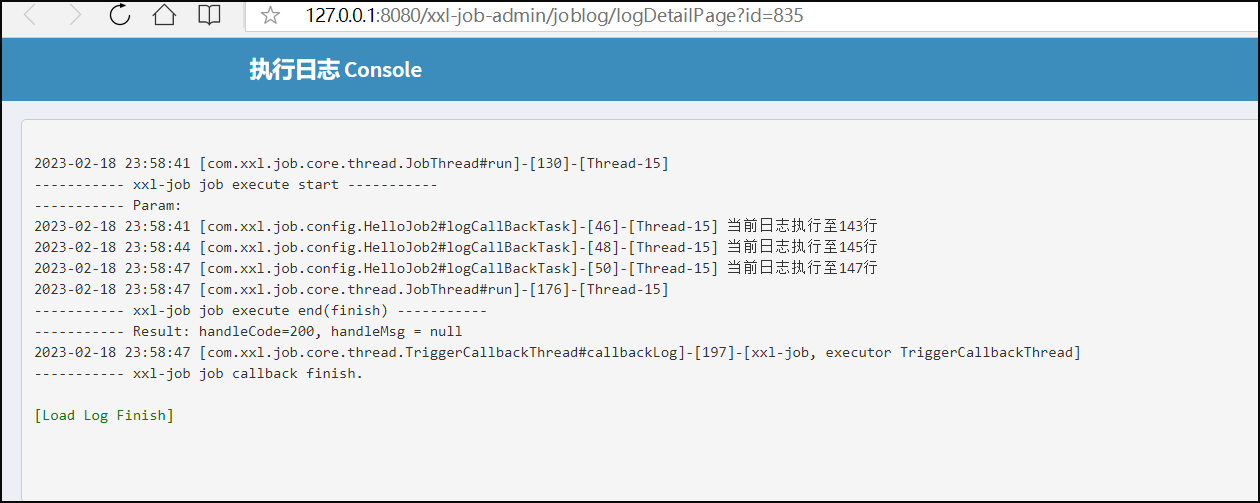
日志打印: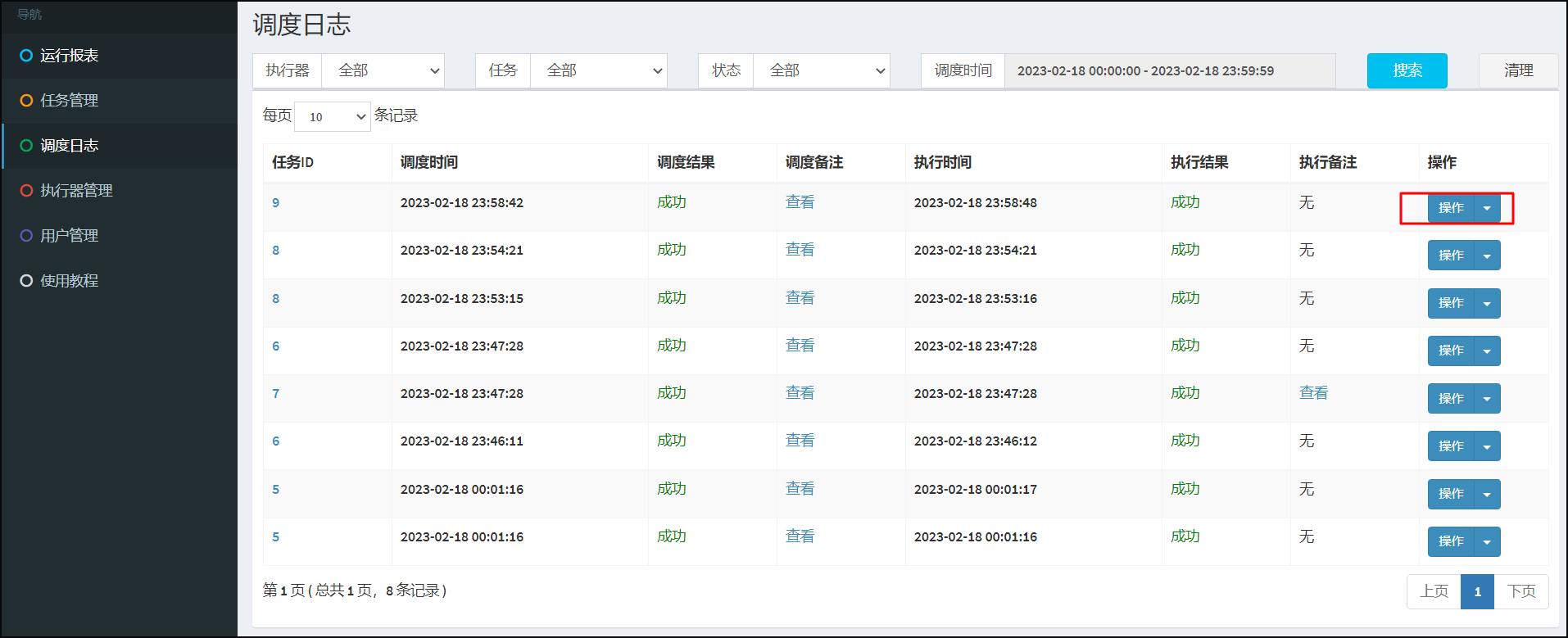
17.xxl-job高级配置之任务生命周期
xxl-job 支持在任务调用时,第一次调用时先执行指定方法,然后在执行具体的任务,
当执行器停止时会执行指定方法,这就是xxl-job 任务的生命周期。
向定时任务,添加如下验证任务生命周期功能代码片段。
/**
* 任务生命周期方法
*/
@XxlJob(value = "lifeCycleTask", init = "init", destroy = "destroy")
public ReturnT lifeCycleTask(){
logger.info("任务生命周期执行");
return ReturnT.SUCCESS;
}
public void init(){
logger.info("任务初始化方法");
}
public void destroy() {
logger.info("任务销毁方法");
}
打开Xxl-job 调度中心管理端。选择任务管理/新增任务生命周期任务。
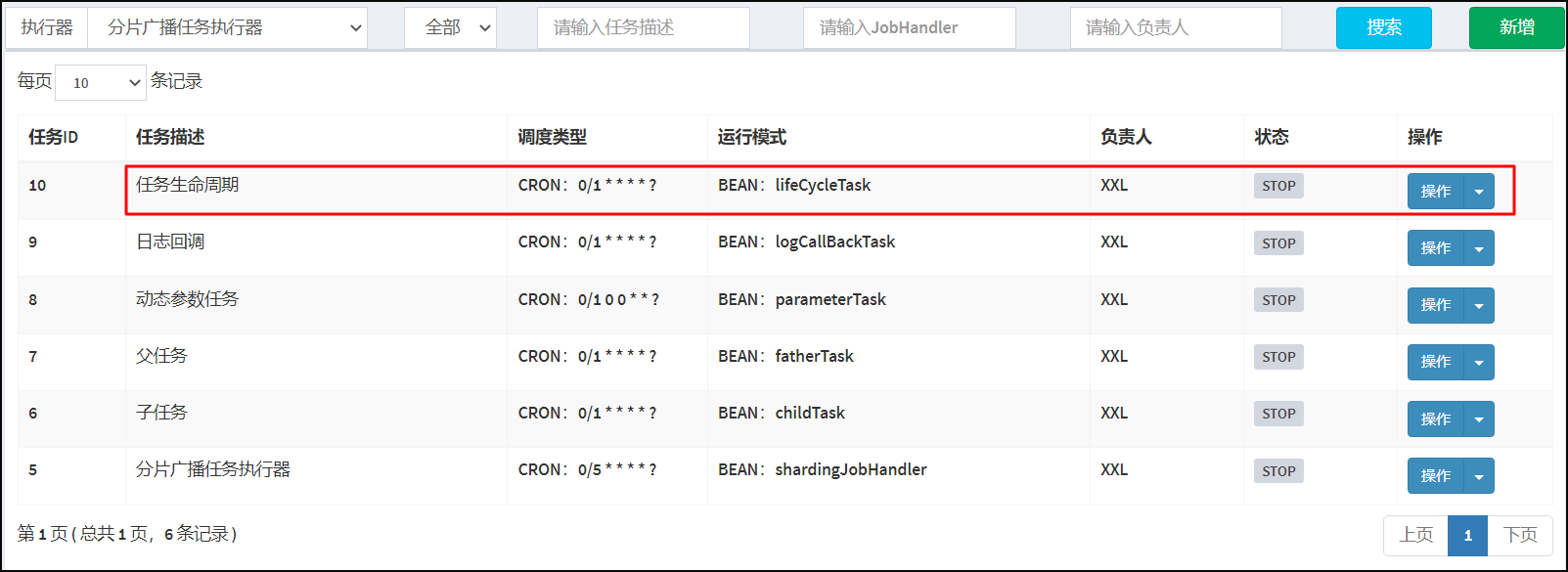
执行器控制台打印相关结果参数: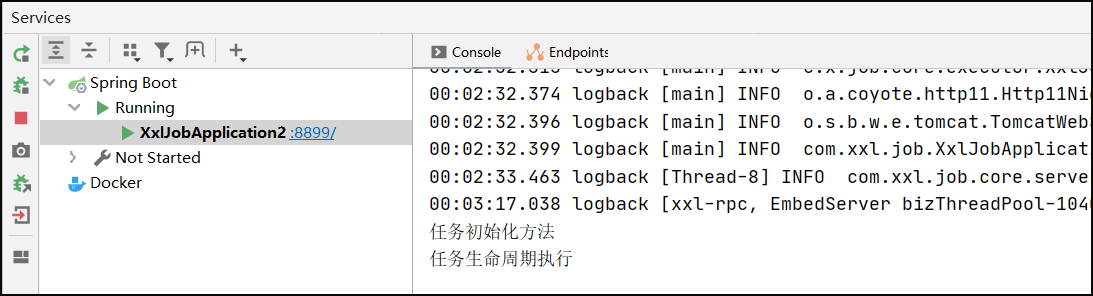
当关闭执行器时候,销毁方法调用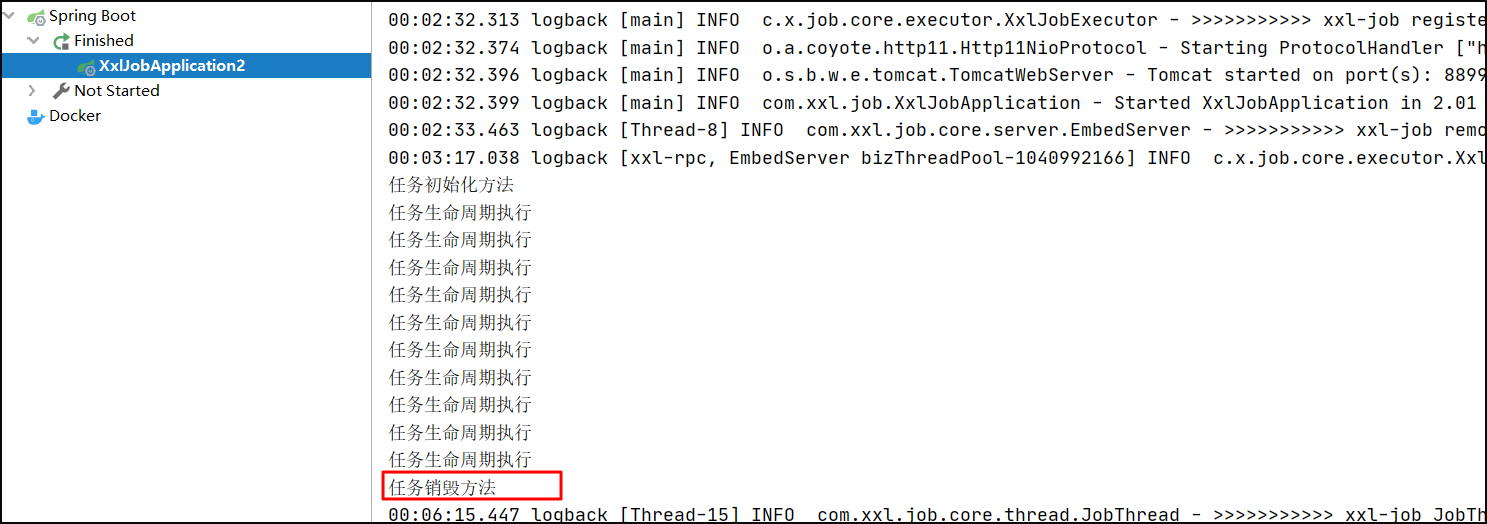
18.xxl-job高级配置之任务生命周期
任务以源码方式维护在调度中心,支持通过Web IDE在线更新,实时编译和生效,因此不需要指定JobHandler。
打开Xxl-job 调度中心管理端。选择任务管理/新增GLUE【Java】任务。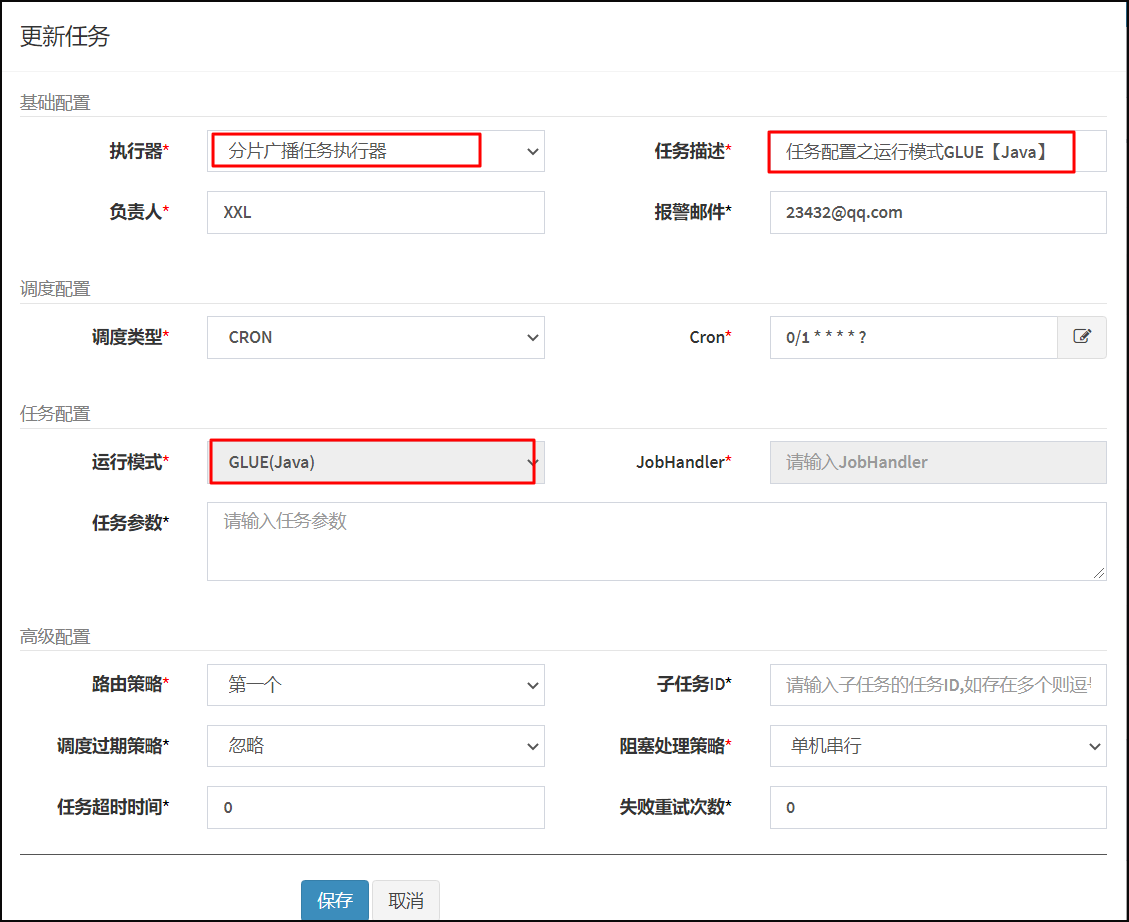
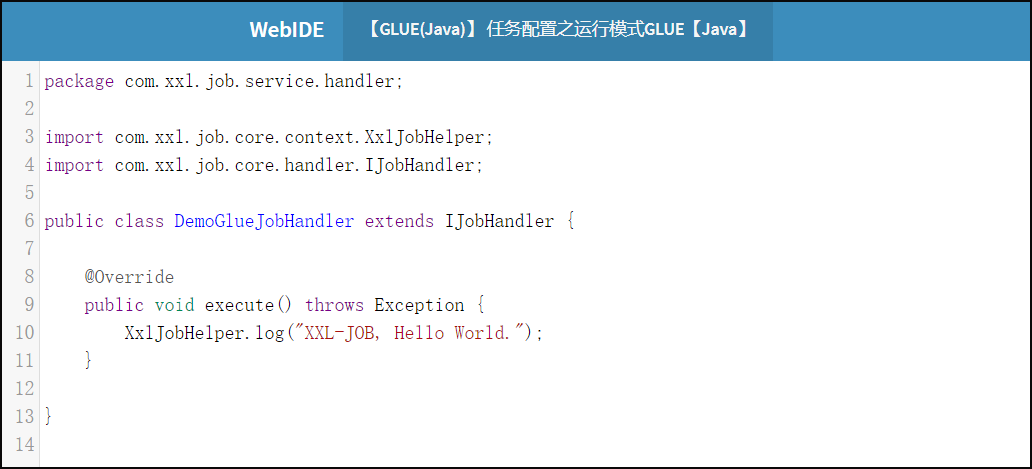
开发任务代码:
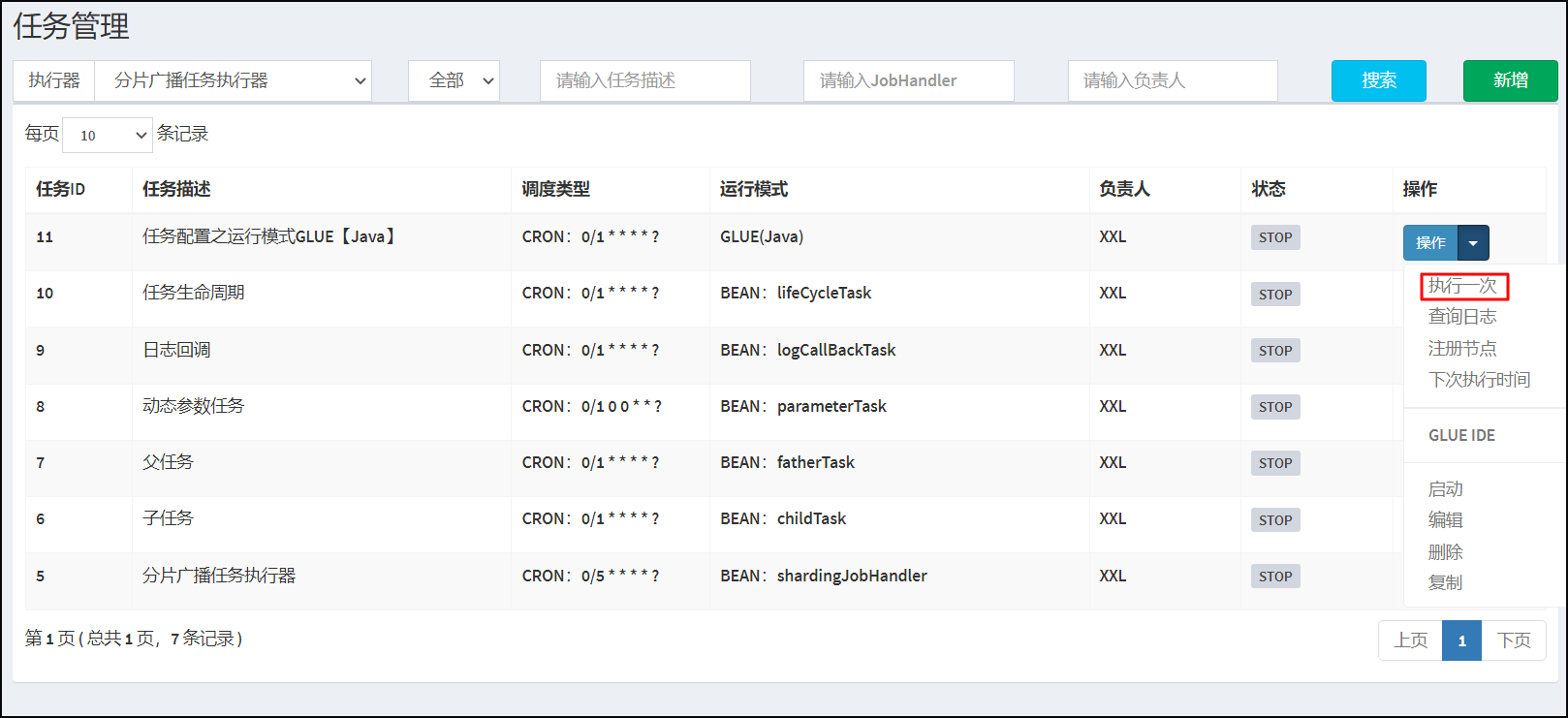
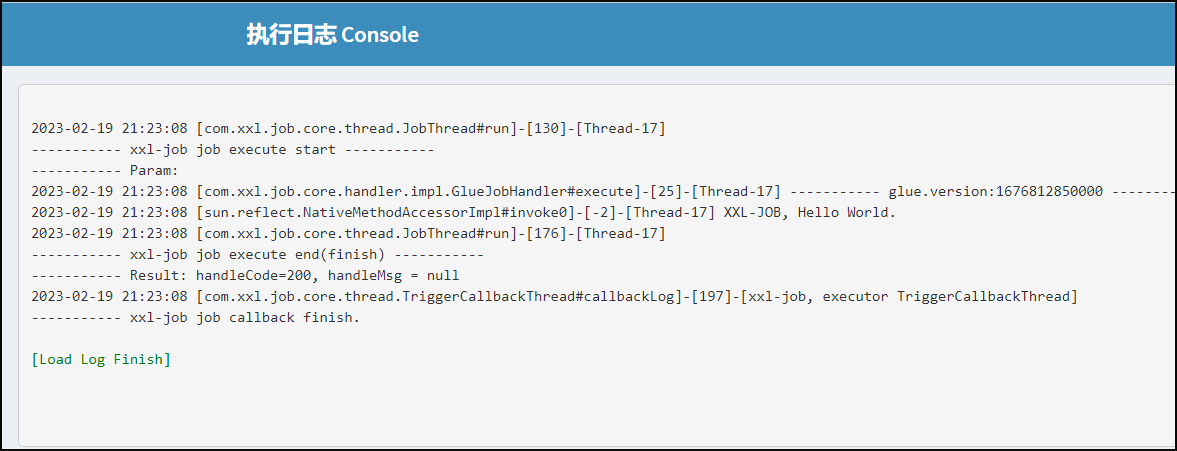
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)。
版本回溯功能(支持30个版本的版本回溯):在GLUE任务的Web IDE界面,选择右上角下拉框“版本回溯”,会列出该GLUE的更新历史,选择相应版本即可显示该版本代码,保存后GLUE代码即回退到对应的历史版本;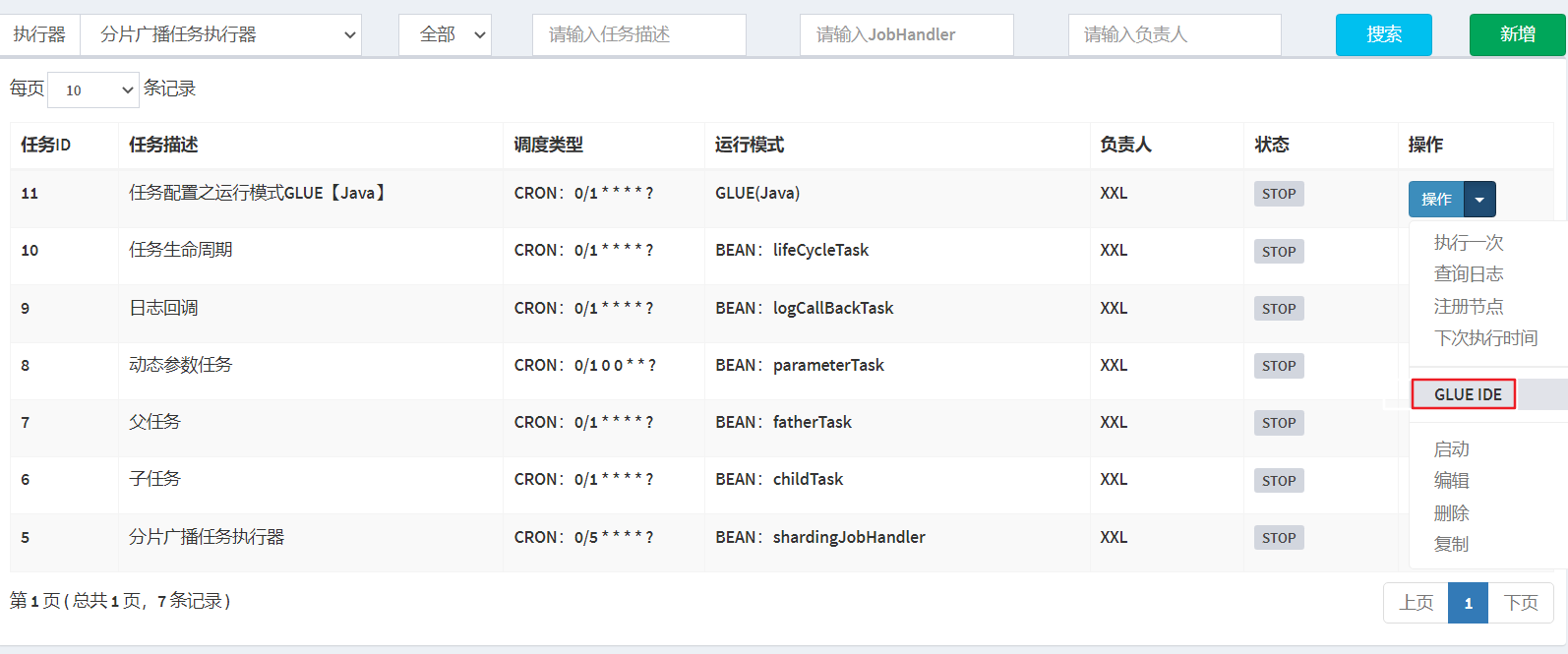

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)