赫拉(hera)分布式任务调度系统之开发中心(三)
简介开发中心,顾名思义。我们进行开发的地方(当然我们也可以直接在调度中心加任务,建议任务首先在开发中心测试,通过之后再加到调度中心)。目录介绍如图所示,开发中心有两个文件夹。分别是个人文档、共享文档。这两个文件夹不允许删除。个人文档提供给账户登录者使用的,私人目录可以在这里创建,执行任务时的用户,以创建者为准共享文档文件夹内的脚本对所有用户可见,执行时任务的用户以实际的登录者...
赫拉
大数据平台,随着业务发展,每天承载着成千上万的ETL任务调度,这些任务集中在hive,shell脚本调度。怎么样让大量的ETL任务准确的完成调度而不出现问题,甚至在任务调度执行中出现错误的情况下,任务能够完成自我恢复甚至执行错误告警与完整的日志查询。hera任务调度系统就是在这种背景下衍生的一款分布式调度系统。随着hera集群动态扩展,可以承载成千上万的任务调度。它是一款原生的分布式任务调度,可以快速的添加部署wokrer节点,动态扩展集群规模。支持shell,hive,spark脚本调度,可以动态的扩展支持python等服务器端脚本调度。
项目地址:git@gitee.com:dfire/hera.git
简介
开发中心,顾名思义。我们进行开发的地方(当然我们也可以直接在调度中心加任务,建议任务首先在开发中心测试,通过之后再加到调度中心)。
项目地址:git@gitee.com:scx_white/hera.git
目录介绍
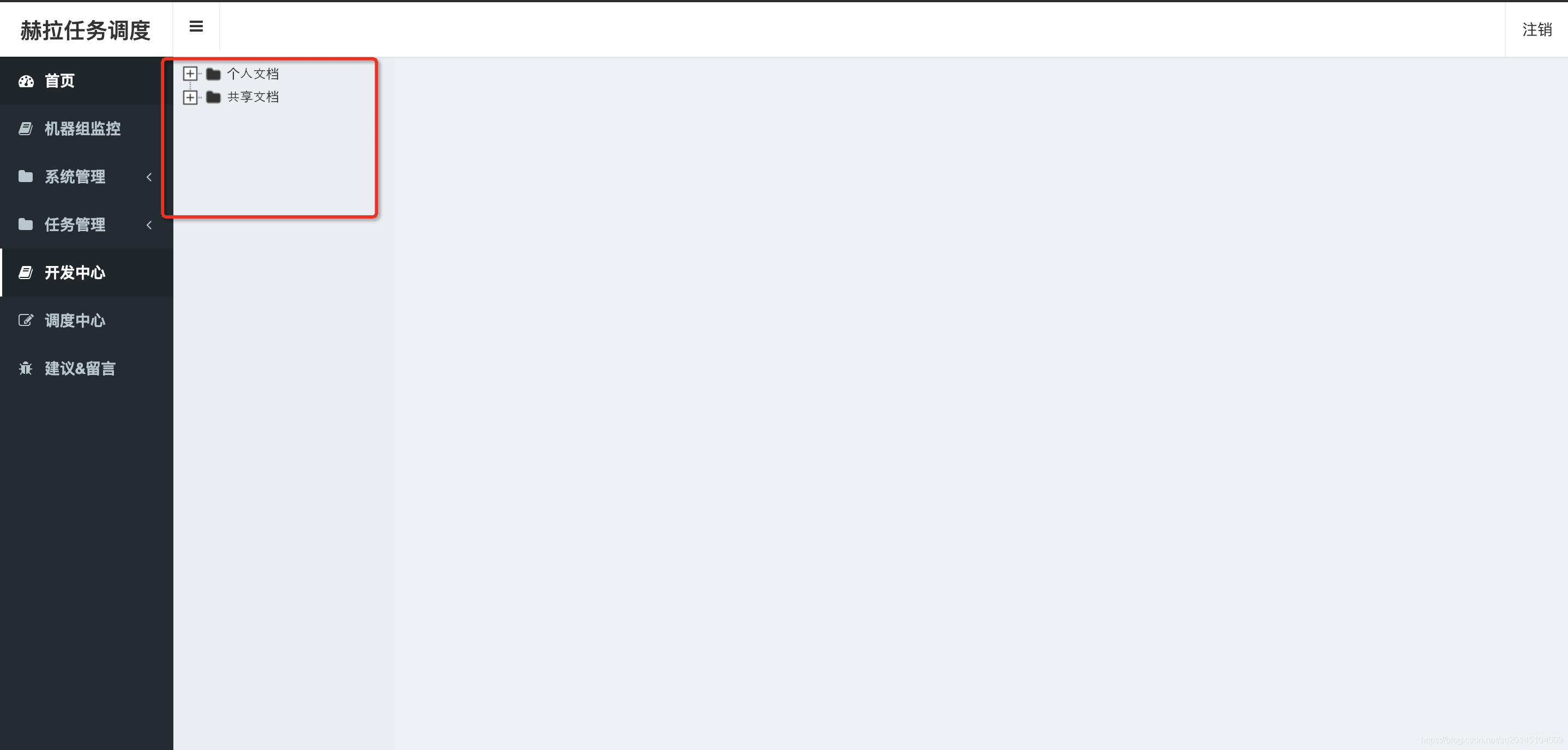
如图所示,开发中心有两个文件夹。分别是个人文档、共享文档。这两个文件夹不允许删除。
- 个人文档
提供给账户登录者使用的,私人目录可以在这里创建,执行任务时的用户,以创建者为准 - 共享文档
文件夹内的脚本对所有用户可见,执行时任务的用户以实际的登录者为准
创建一个脚本
鼠标放在个人中心,然后点击鼠标右键选择新建shell脚本。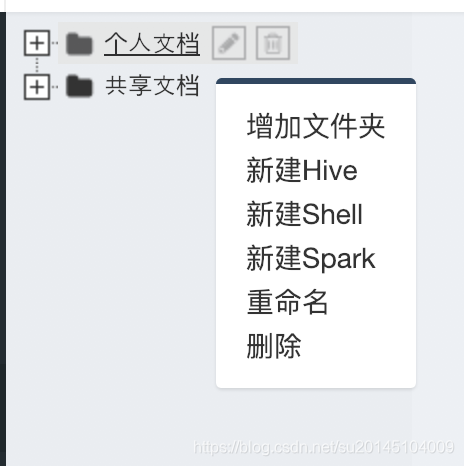
然后在编辑区写入要执行的脚本内容点击执行即可
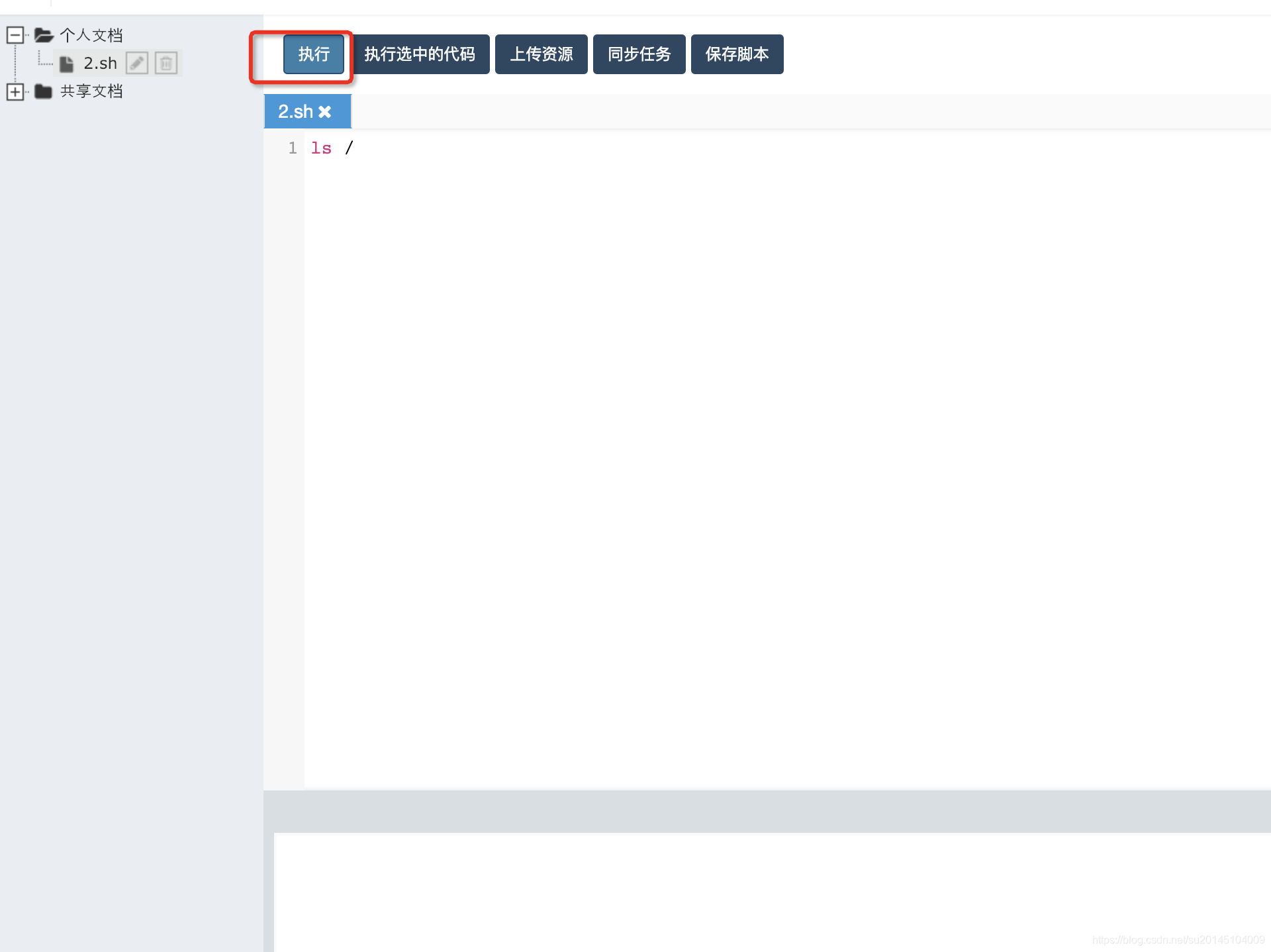
此时在编辑区下方会有当前执行任务的日志信息输出
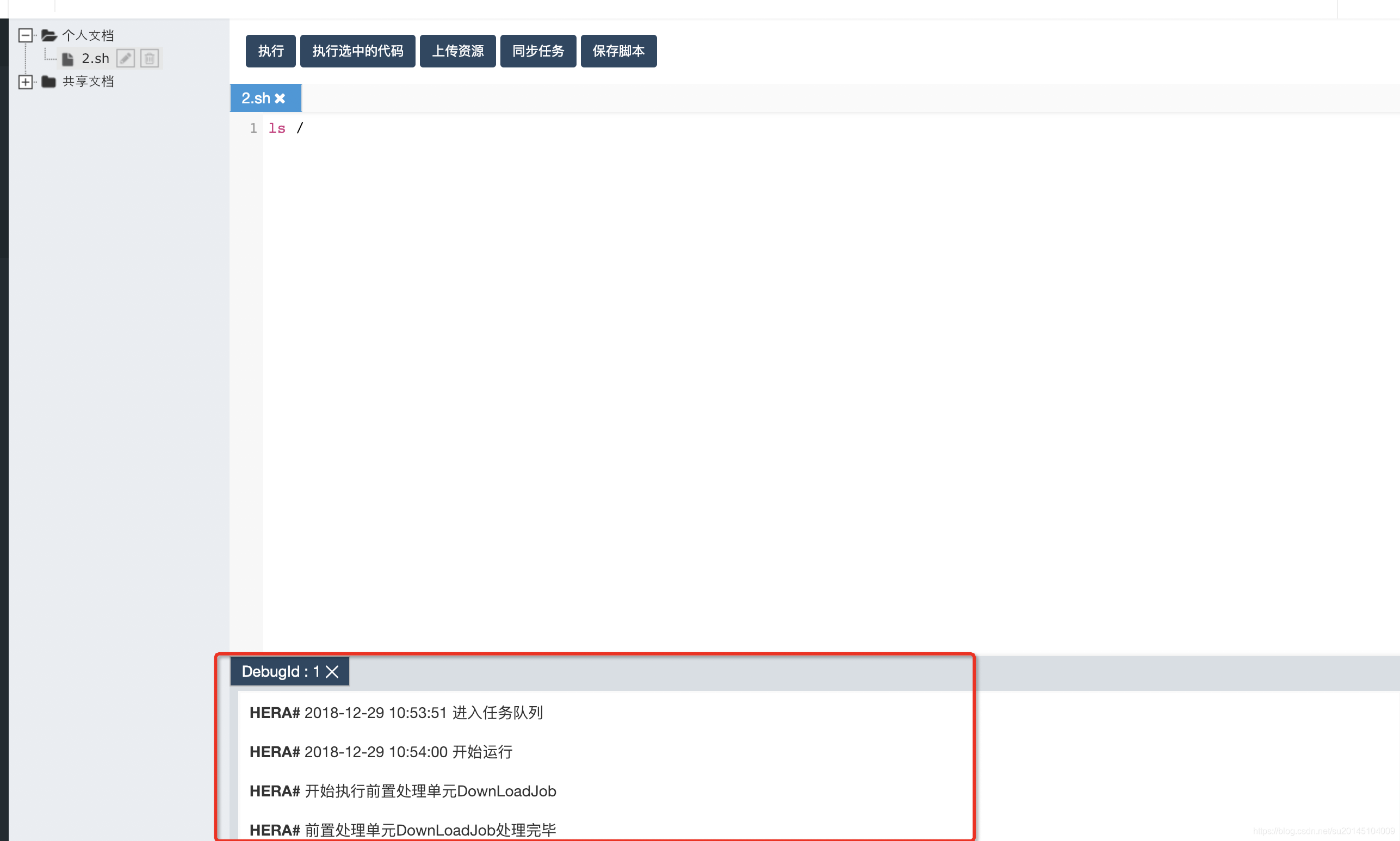
当然也可以通过点击下方历史日志看所有日志信息。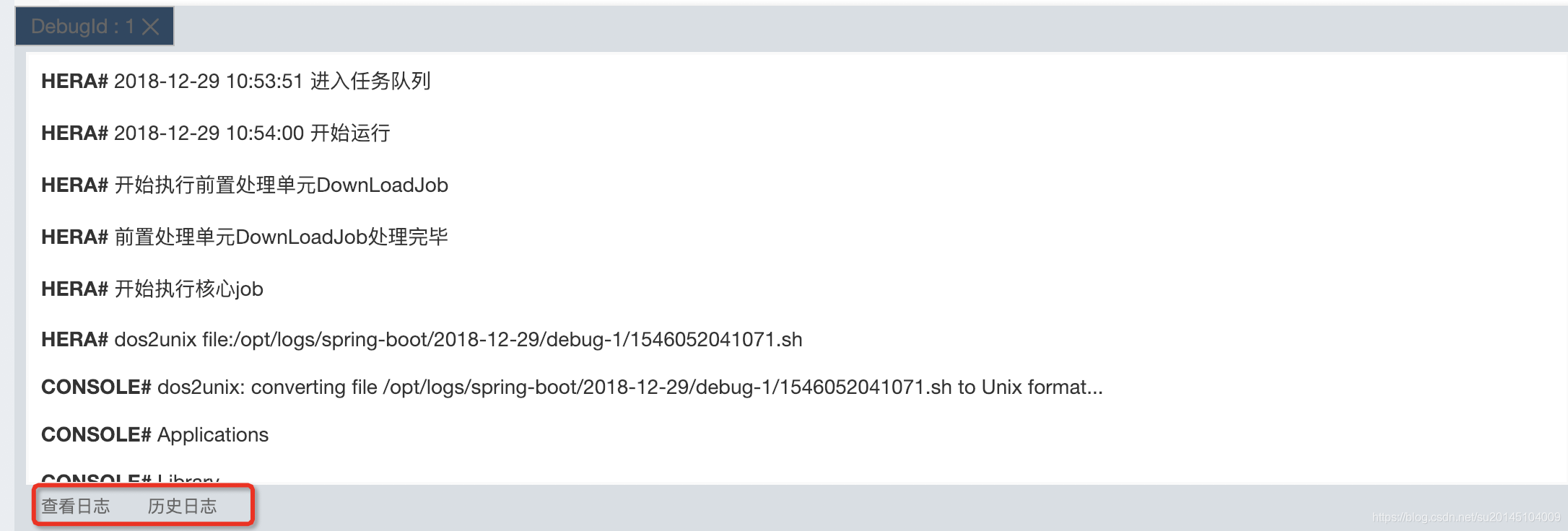
执行选中的代码
我们可以通过在编辑区使用鼠标选中我们要执行的代码,然后点击执行选中代码即可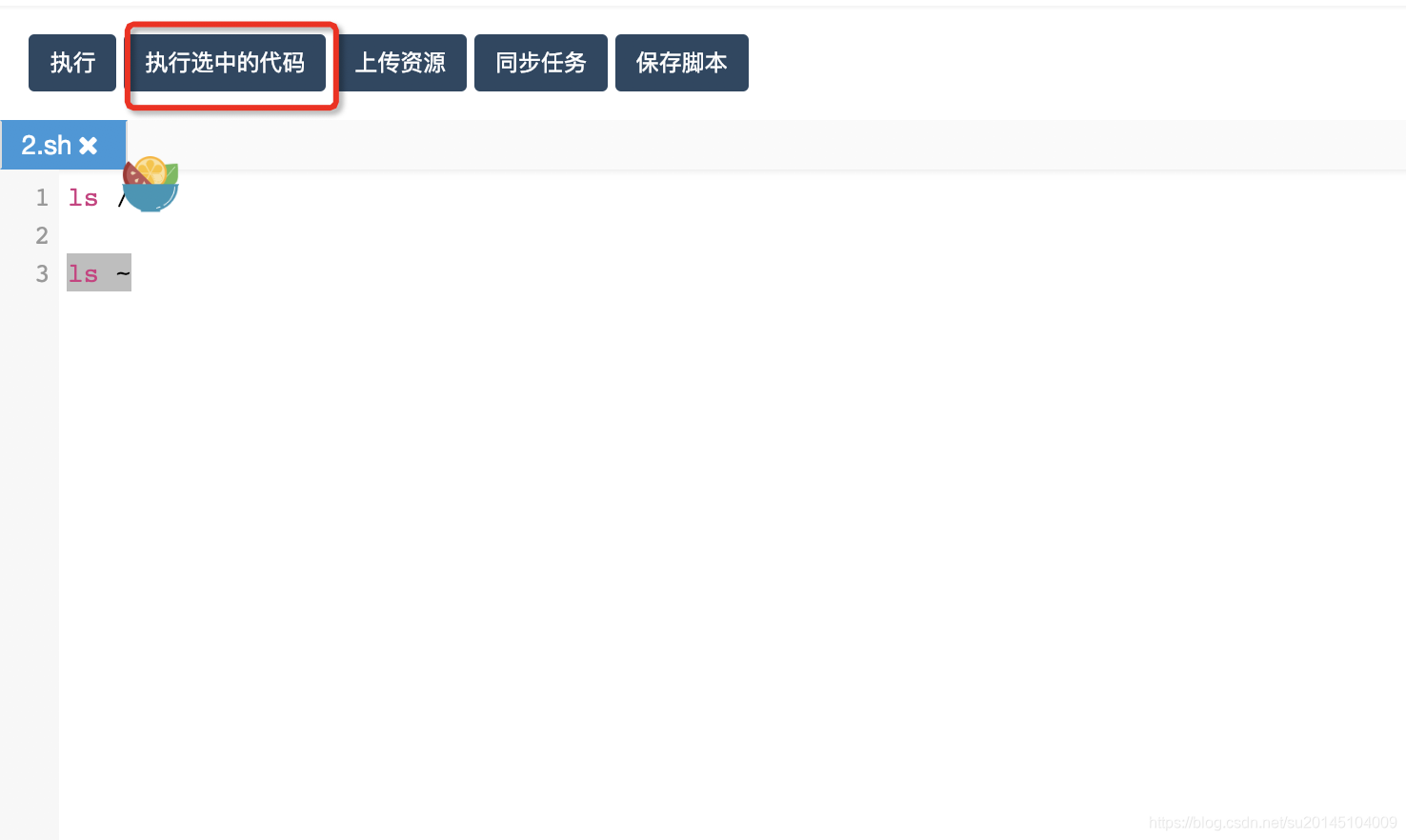
上传资源
当需要上传资源(py, jar, sql, hive, sh, js, txt, png, jpg, gif等等)时要注意,要保证我们的master和work有hadoop环境,能够执行hadoop fs -copyFromLocal命令。
上传完资源后。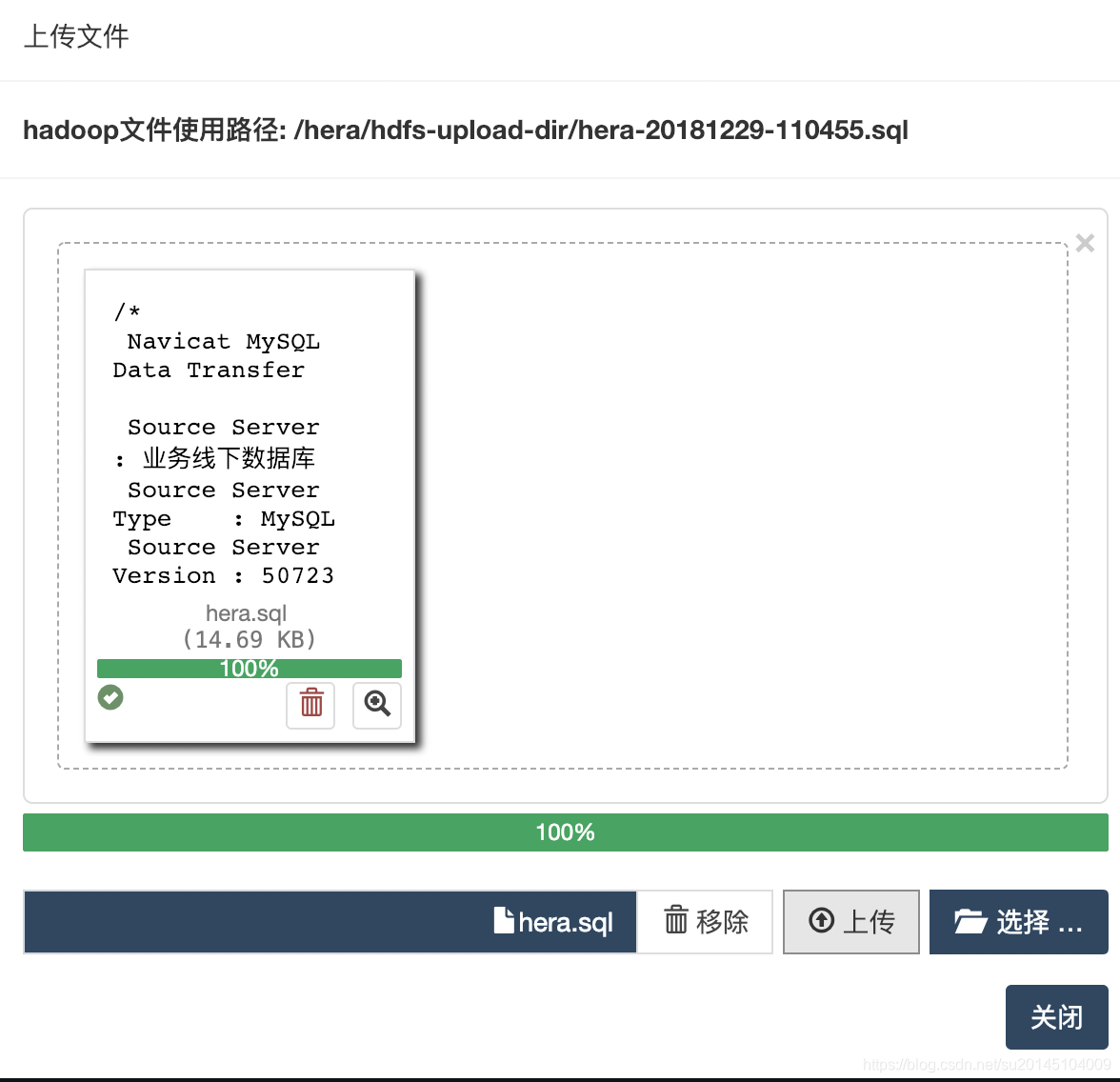
最上方会返回该资源文件的使用地址。
/hera/hdfs-upload-dir/hera-20181229-110455.sql
如果我们是使用spark-submit 或者hive udf 的 add jar 命令,直接加上hadoop路径即可。
比如:
add jar hdfs:///hera/hive_custom_udf/2dfire-hivemr-log.jar;
或者:
spark2-submit --class com.dfire.start.App \
--jars hdfs:///spark-jars/common/binlog-hbase-1.1.jar \
当然如果是一些python脚本,或者txt。我们需要下载下来执行的。就需要执行
download[hdfs:///hera/hdfs-upload-dir/hera-20181229-110455.sql hera.sql]
启动download为hera的定制命令。[]分为两部分,使用空格分开。空格左部分为hdfs文件的路径,空格右部分为重命名后的文件名。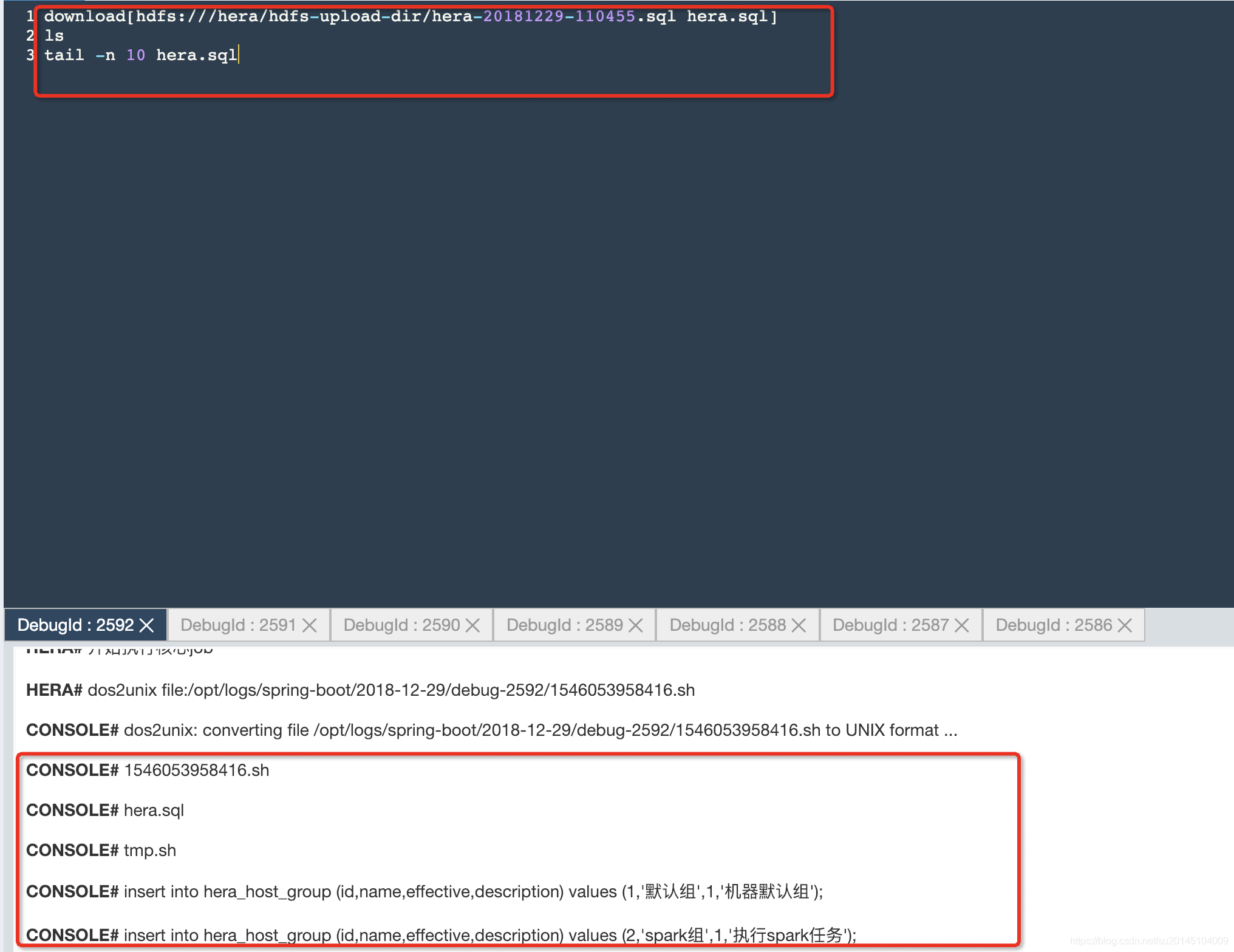
同步任务
暂未开发
脚本自动保存
当在开发中心写脚本时,脚本会自动保存。当然也可以通过点击保存脚本进行手动保存。
加入群聊

个人微信(失效加我拉你进去)

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)