hadoop基础【Zookeeper概述和安装】
一、概述Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。Zookeeper从设计模式角度理解是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。Zookeeper的两项核心功能:存储数据,通知机制。h
一、概述
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。Zookeeper从设计模式角度理解是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
Zookeeper的两项核心功能:存储数据,通知机制。
hdfs已经存储了数据,那么Zookeeper不会存储全部数据,存储的一般是一些元信息或是一些配置信息,这些信息所占内存很小。
不同框架之间协调或者是框架内部需要协调,都可以使用Zookeeper,一般开发人员会直接和框架之间产生联系,不会和Zookeeper发生关系,Zookeeper对于开发人员来说是不可改制。一般我们布置好Zookeeper,启动就成功了,之后告诉这些框架Zookeeper在哪里,在大数据的应用中,Zookeeper常作为一个背景。
Zookeeper特点:
- 一个leader,多个follower组成的集群;
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务;
- 全局数据一致:每个server保存一份相同的数据副本,client无论连接到那个server,数据都是一致的;
- 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行;
- 数据更新的原子性,一个更新要么一起成功,要不一起失败;
- 实时性,在一定时间范围内,client能读到最新的数据。
正因为以上特点,Zookeeper才能够成为中央协调平台。
Zookeeper数据结构:
Zookeeper数据模型的结构与Unix文件系统类似,是一个树形结构,每个节点称作一个ZNode,每一个ZNode默认能够存储1MB数据,每个ZNode都可以通过其路径唯一标识,与Unix不同在于,Zookeeper节点不区分文件和文件夹,统称为ZNode,每一个ZNode都可以有子节点,且能够存储数据。
二、Zookeeper安装
拷贝Zookeeper安装包到Linux系统下
tar -zxvf zookeeper-3.5.7.tar.gz -C /opt/module/
修改名字:mv apache-zookeeper-3.5.7-bin/ zookeeper
环境变量:sudo vim /etc/profile.d/my_env.sh
#ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
同步环境变量:sudo xsync /etc/profile.d/my_env.sh
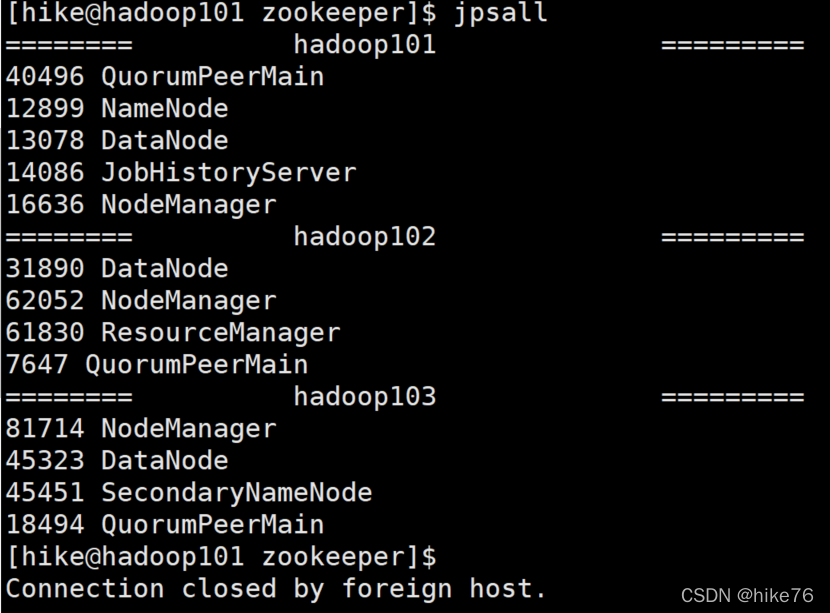
出现下图即为安装成功:

配置修改
(1)将/opt/module/zookeeper-3.5.7/conf这个路径下的zoo_sample.cfg修改为zoo.cfg;
[atguigu@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
(2)打开zoo.cfg文件,修改dataDir路径:
[atguigu@hadoop102 zookeeper-3.5.7]$ vim zoo.cfg
修改如下内容:
dataDir=/opt/module/zookeeper-3.5.7/zkData
分布式环境下的配置,进入zoo.cfg
server.1=hadoop101:2888:3888
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
(3)在/opt/module/zookeeper-3.5.7/这个目录上创建zkData文件夹
[atguigu@hadoop102 zookeeper-3.5.7]$ mkdir zkData
cd zkData/
vim myid
在这个文件中写入1
xsync zookeeper/
将所有机器上的myid文件中的数字依次改为2和3
分别在三台机器启动Zookeeper:zkServer.sh start
出现下图即为配置完成!

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)