xxl-job调度平台的使用
xxl-job是一个轻量级分布式任务调度平台,相比于crontab -e,具备分布式/并发/可视化监控/分片等优点。缺点在于相对于单机任务过于重量级以及需要部署中心和执行器。
简介
资源
官方文档:https://www.xuxueli.com/xxl-job/
github地址:https://github.com/xuxueli/xxl-job
gitee地址:https://github.com/xuxueli/xxl-job
可分为有四大模块
doc: 文档
xxl-job-admin:调度中心管理后台
xxl-job-core: 框架核心包
xxl-job-executor-samples: 执行器的案例代码
拉取代码导入项目后准备启动admin项目,修改对应数据库地址账号和密码后,在数据库管理工具中执行sql,tables_xxl_job.sql

启动项目后:
访问http://localhost:8080/xxl-job-admin/toLogin
进入管理页面。默认账号/密码:admin/123456
Linux运行:打包项目后jar -jar 运行
执行器
导入依赖
<!-- xxl-job-core -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.1</version>
</dependency>
配置构件信息
xxl:
job:
admin:
addresses: http://localhost:8080/xxl-job-admin
accessToken:
executor:
appname: zpa-job
#ip: 10.123.1.53
port: 9999
# 日志地址
logpath: /data/applogs/xxl-job/jobhandler
# 日志保存时间
logretentiondays: 30
### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### xxl-job, access token
xxl.job.accessToken=default_token
### xxl-job executor appname
xxl.job.executor.appname=xxl-job-executor-sample
### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
xxl.job.executor.address=
### xxl-job executor server-info
xxl.job.executor.ip=
xxl.job.executor.port=9999
### xxl-job executor log-path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job executor log-retention-days
xxl.job.executor.logretentiondays=30
注册xxl配置类参数到构件中:
@Configuration
@Slf4j
class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appName;
/*@Value("${xxl.job.executor.ip}")
private String ip;*/
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
log.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appName);
xxlJobSpringExecutor.setAddress(adminAddresses);
// xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}
示例代码
@Component
public class myXxlHandler {
@XxlJob("Demo")
public ReturnT<String> demo(){
String param = XxlJobHelper.getJobParam();
XxlJobHelper.log("-------------测试开始-------------");
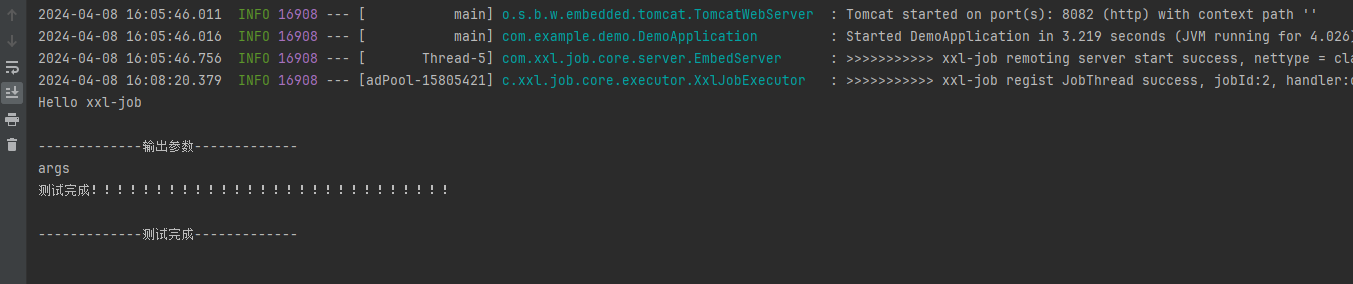
System.out.println("Hello xxl-job");
System.out.println();
System.out.println("-------------输出参数-------------");
System.out.println(param);
System.out.println("测试完成!!!!!!!!!!!!!!!!!!!!!!!!!!!!");
System.out.println();
System.out.println("-------------测试完成-------------");
System.out.println();
XxlJobHelper.log("测试`结束");
return ReturnT.SUCCESS;
}
}

若为无则是未注册成功。
比较坑的是,这里需要手动新增执行器和任务,才会刷新到列表里面。
注册报错信息:
xxl-job registry fail, registryParam:RegistryParam{registryGroup=‘EXECUTOR’, registryKey=‘zpa-job’, registryValue=‘http://localhost:8080/xxl-job-admin’}, registryResult:ReturnT [code=500, msg=The access token is wrong., content=null]
执行任务报错:
出现登录界面的原有是,自动注册把admin的页面地址注册进去,改为手动注册,编写执行器应用服务对应地址和端口即可。




操作中配置crontab 命令启动定时任务:

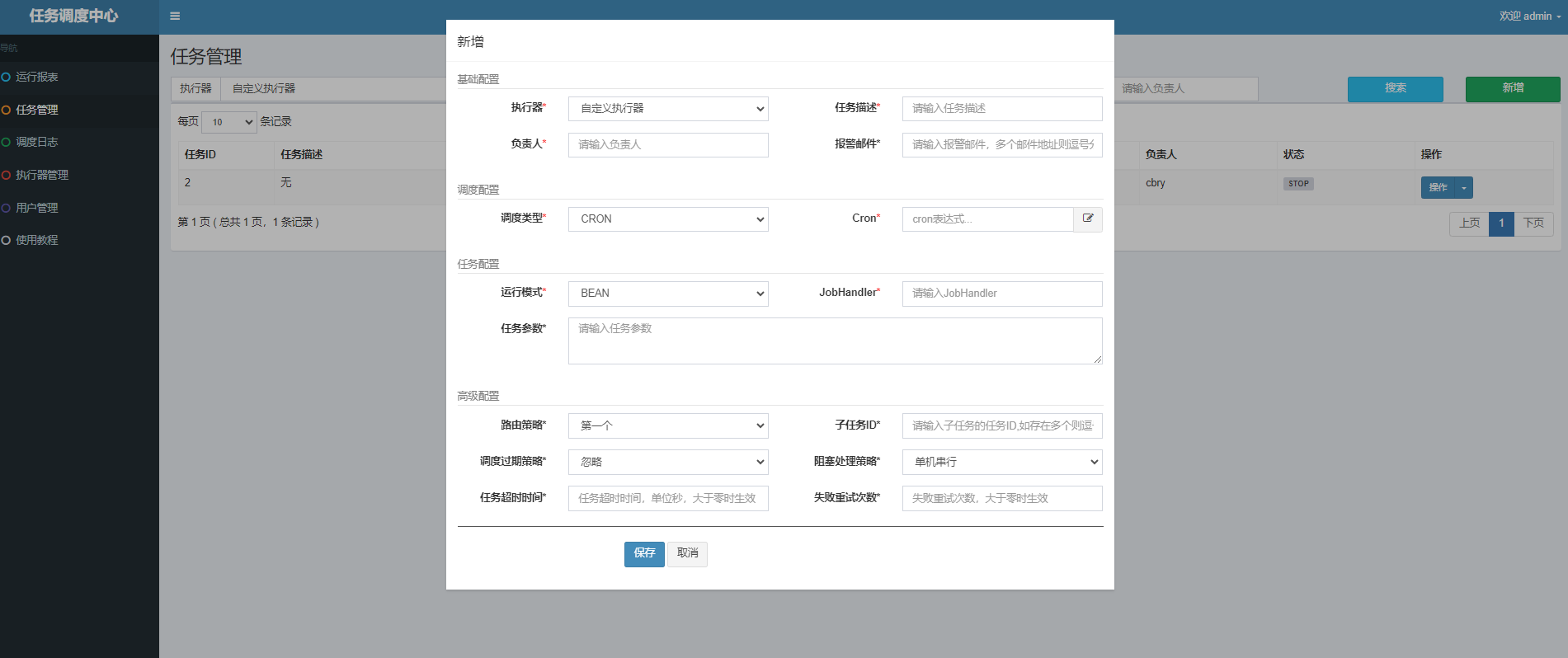
一、XXL-JOB任务类型:
1、BEAN模式: Spring应用中的 ①类形式 ②方法形式
2、GLUE模式:注入admin应用(调度中心维护)中 Java / Shell / Python / Nodejs / Php
使用GLUE 的 WebIDE编辑


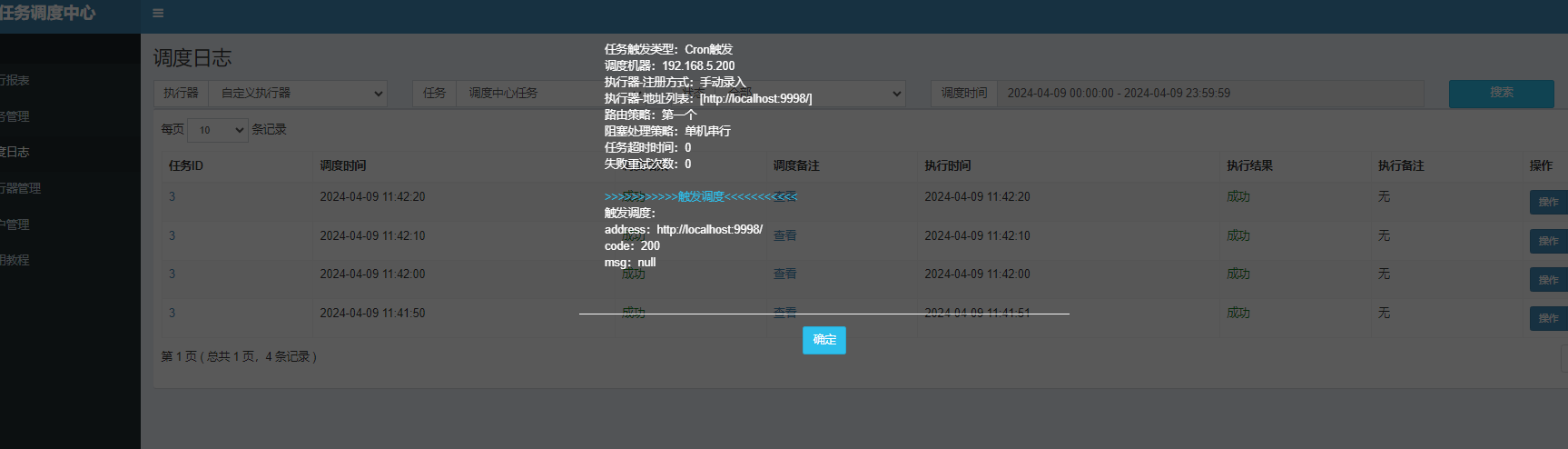
查看执行日志

二、XXL-JOB的日志清理:
日志分类:
1、调度日志:任务调度的时候,会告知一些比如执行器信息,调度结果等2、
2、执行日志:JOB执行过程中日志,XxlJobLogger.log(“”)中进行打印

注意选项是多久/条数之前的数据。
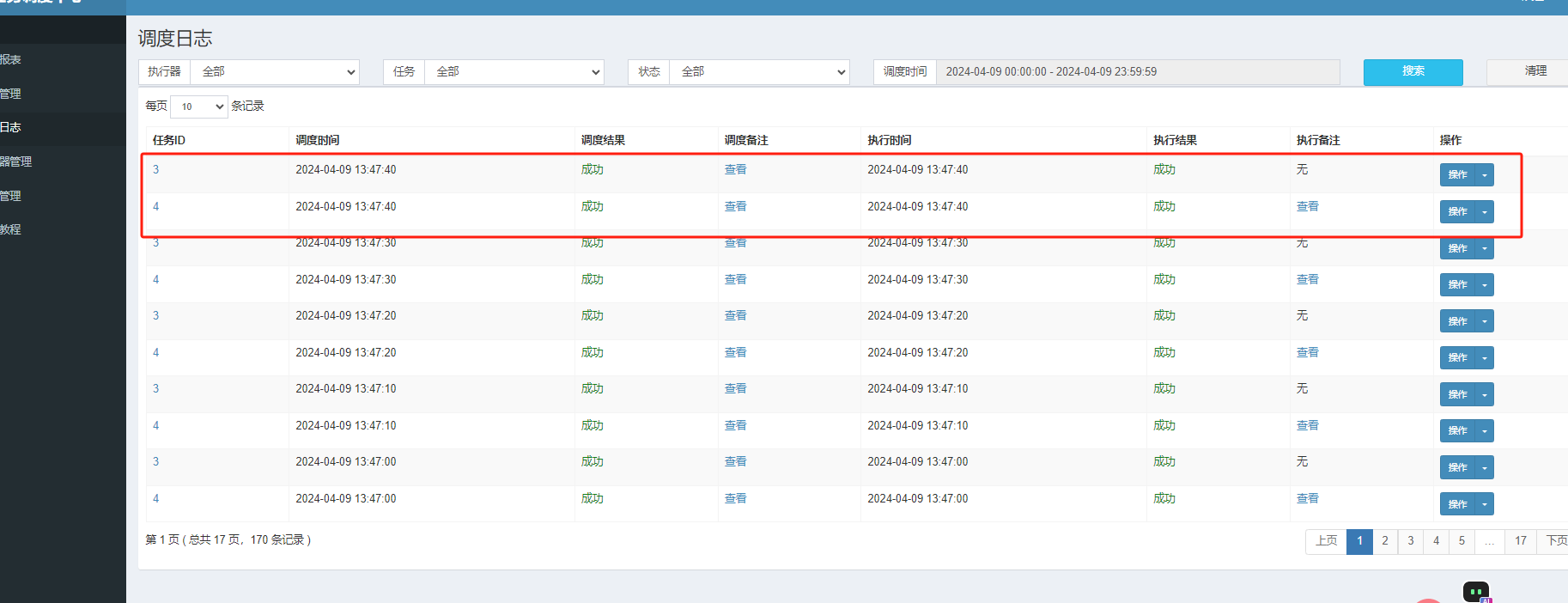
XLL-JOB子任务介绍:
XXL-JOB中有自带子任务编排功能,支持当前任务执行成功后调用子任务,多个子任务使用逗号分隔;
如在任务4中设置3为子任务,如下:
XLL-JOB分片广播任务:
执行器集群部署时,任务路由策略选择 【分片广播】路由策略情况下,一次任务调度将会广播触发对应集群中所有执行器都触发执行一次任务,同时系统自动传递分片参数,可根据分片参数开发分片任务。
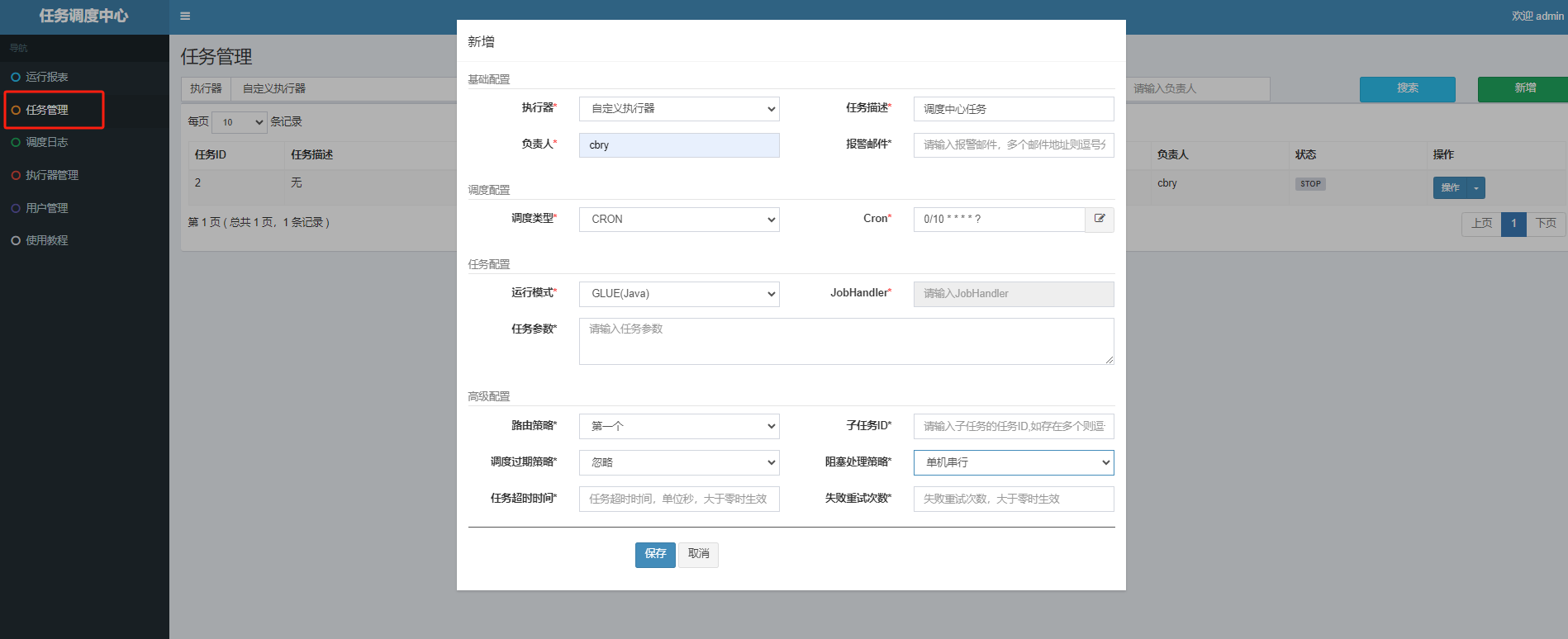
首先,创建一个新的集群执行器(这里摸索半天才摸索出分片怎么用):
手动录入机器地址:http://localhost:9998/,http://localhost:9999/,

在集群执行器下面建造新的任务编写如下代码,勾选路由策略为分片广播。
使用GLUE 的 WebIDE编辑如下官方示例代码:
public class DemoGlueJobHandler extends IJobHandler {
@Override
public void execute() throws Exception {
int shardCount = 10; // 分片总数
int shardIndex = XxlJobHelper.getShardIndex(); // 当前分片项
XxlJobHelper.log("XXL-JOB, 分片广播示例-"+String.valueOf(shardIndex));
// 执行任务逻辑
for (int i = 0; i < 100; i++) {
if (i % shardCount == shardIndex) {
// 当前分片项需要执行的任务逻辑
XxlJobHelper.log("Shard " + shardIndex + " is running: " + i);
}
}
}
}
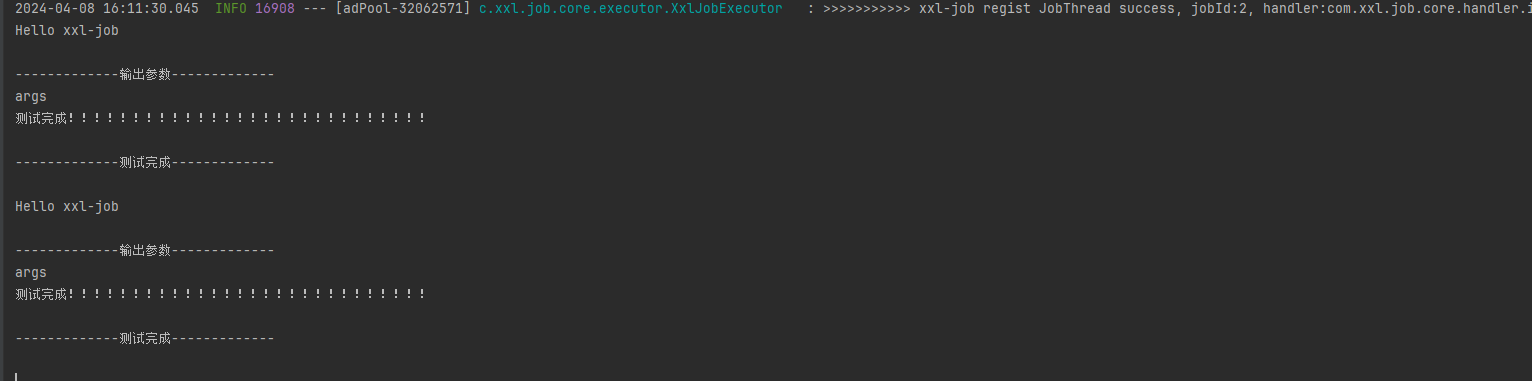
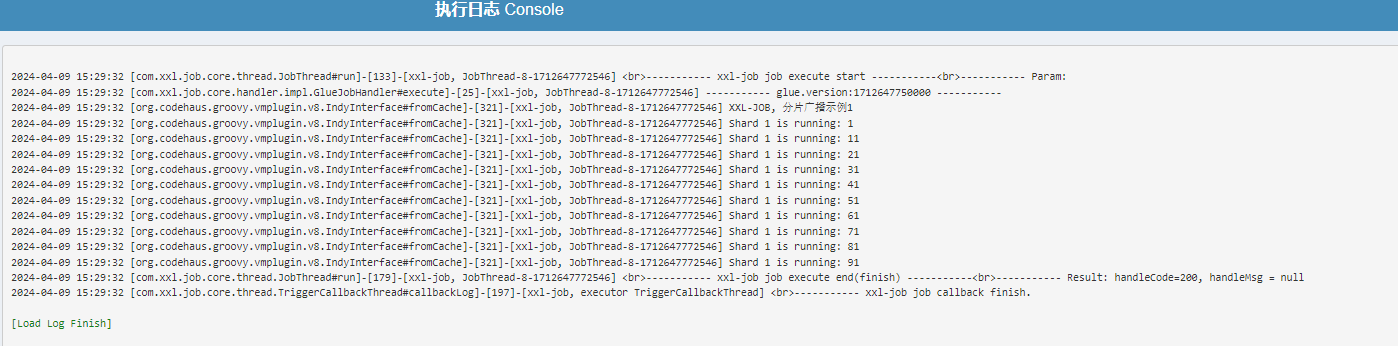
在调度日志中可以看到集群执行器的两个机器都调度了结果:

其中第二个分片id为1的日志如下:
xxl-job执行器路由选择策略
- 路由策略:当执行器集群部署时,提供丰富的路由策略,包括:
FIRST(第一个):固定选择第一个机器;
LAST(最后一个):固定选择最后一个机器;
ROUND(轮询):;
RANDOM(随机):随机选择在线的机器;
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参
阻塞策略
阻塞策略是处理任务执行过程中可能出现的阻塞问题的一种机制。在任务执行过程中,可能会遇到任务处理时间比调度周期还要长的情况,这时候就需要用到阻塞策略来决定如何处理这些密集的调度请求。
阻塞策略的类型
- 单机串行(默认)
- 当任务调度请求进入单机执行器后,所有的调度请求将会进入一个FIFO(先进先出)队列中,并以串行的方式运行。这意味着,如果当前有一个任务正在执行,新的调度请求将会等待前一个任务完成后才能开始执行。
- 丢弃后续调度
- 在这种策略下,如果执行器已经存在正在运行的调度任务,那么新的调度请求将会被丢弃,并标记为失败。这种策略适用于那些不需要连续执行的任务,可以容忍任务的丢失。
- 覆盖之前调度
- 当新的调度请求到达时,如果执行器正在运行任务,那么当前运行的任务将被终止,队列中的其他任务也会被清空,然后执行新的调度任务。这种策略适用于那些最新任务的执行比之前的任务更加重要的场景。
如何选择阻塞策略
选择哪种阻塞策略取决于具体的业务需求和任务特性。例如,对于不需要连续处理的任务,可以选择“丢弃后续调度”策略,以避免任务积压;而对于关键任务,可能需要选择“覆盖之前调度”策略,确保最新的任务能够及时得到处理。
阻塞策略的应用场景
- 单机串行适用于任务之间没有依赖关系,且每个任务可以独立执行的场景。
- 丢弃后续调度适用于任务执行频率较高,但任务丢失对系统影响较小的情况。
- 覆盖之前调度适用于任务执行的时效性要求较高,新任务的执行优先级高于旧任务的场景。

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)