DCGAN
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS (基于深度卷积生成对抗网络的无监督表示学习)1 INTRODUCTIONLearning reusable feature representations from large unlabeled datasets
目录
2.1 REPRESENTATION LEARNING FROM UNLABELED DATA
3 APPROACH AND MODEL ARCHITECTURE
4 DETAILS OF ADVERSARIAL TRAINING
5 EMPIRICAL VALIDATION OF DCGANS CAPABILITIES
6 INVESTIGATING AND VISUALIZING THE INTERNALS OF THE NETWORKS
6.1 WALKING IN THE LATENT SPACE
6.3.2 VECTOR ARITHMETIC ON FACE SAMPLES
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS (基于深度卷积生成对抗网络的无监督表示学习)
1 INTRODUCTION
- We propose that one way to build good image representations is by training Generative Adversarial Networks (GANs) ,
- and later reusing parts of the generator and discriminator networks as feature extractors for supervised tasks.
- GANs provide an attractive alternative to maximum likelihood techniques.
defect:
- GANs have been known to be unstable to train,
- often resulting in generators that produce nonsensical outputs.
In this paper, they make the following contributions :
- We propose and evaluate a set of constraints on the architectural topology of Convolutional GANs that make them stable to train in most settings. We name this class of architectures Deep Convolutional GANs (DCGAN)
- We use the trained discriminators for image classification tasks, showing competitive performance with other unsupervised algorithms.
- We visualize the filters learnt by GANs and empirically show that specific filters have learned to draw specific objects.
2 RELATED WORK
2.1 REPRESENTATION LEARNING FROM UNLABELED DATA
从未标记的数据中学习表示
Some methods of unsupervised learning are introduced
2.2 GENERATING NATURAL IMAGES
3 APPROACH AND MODEL ARCHITECTURE
- Replace any pooling layers with strided convolutions (discriminator) and fractional-strided convolutions (generator).
- Use batchnorm in both the generator and the discriminator.
- Remove fully connected hidden layers for deeper architectures.
- Use ReLU activation in generator for all layers except for the output, which uses Tanh.
- Use LeakyReLU activation in the discriminator for all layers.
4 DETAILS OF ADVERSARIAL TRAINING
- No pre-processing was applied to training images besides scaling to the range of the tanh activation function [-1, 1].
- All models were trained with mini-batch stochastic gradient descent (SGD) with a mini-batch size of 128.
- All weights were initialized from a zero-centered Normal distribution with standard deviation 0.02.
- In the LeakyReLU, the slope of the leak was set to 0.2 in all models.
- While previous GAN work has used momentum to accelerate training, we used the Adam optimizer with tuned hyperparameters.
- We found the suggested learning rate of 0.001, to be too high, using 0.0002 instead.
- Additionally, we found leaving the momentum term β1 at the suggested value of 0.9 resulted in training oscillation and instability while reducing it to 0.5 helped stabilize training.
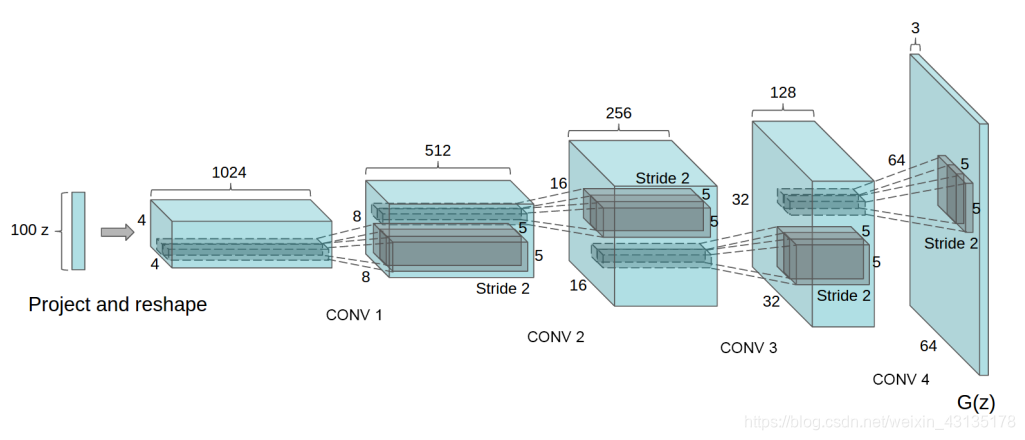
5 EMPIRICAL VALIDATION OF DCGANS CAPABILITIES
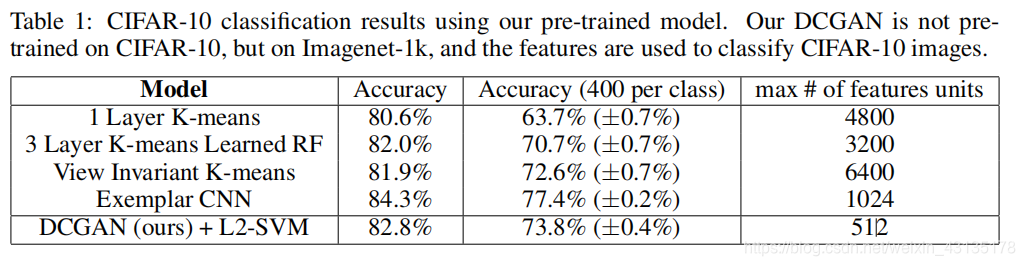
6 INVESTIGATING AND VISUALIZING THE INTERNALS OF THE NETWORKS
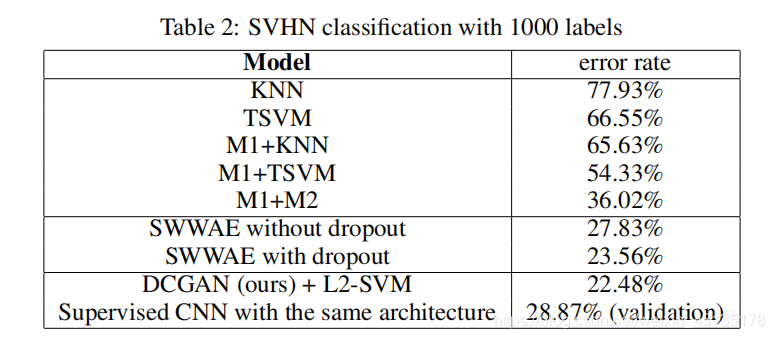
6.1 WALKING IN THE LATENT SPACE
意思就是G学习到了潜在的图像(生成和原来风格差异很大的图像),例如:它可以自动的添加或者删除某些物品,那么我们就认为模型不错


In the 6th row, you see a room without a window slowly transforming into a room with a giant window.
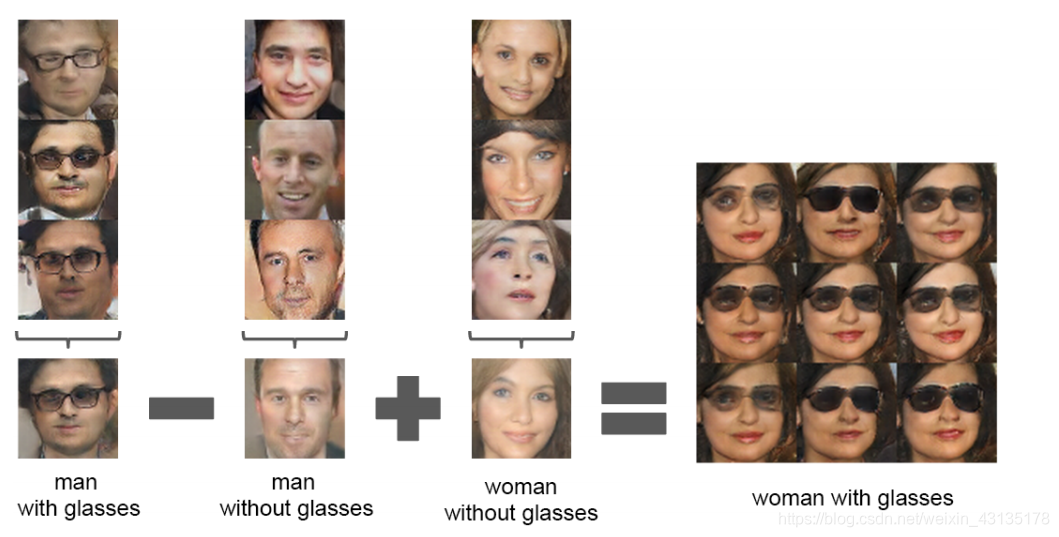
6.3.2 VECTOR ARITHMETIC ON FACE SAMPLES

ACKNOWLEDGMENTS
REFERENCES

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)