用仓颉完成编译原理实验-正规式转NFA转DFA
虽然我只用到仓颉语言简单基础的语法,但能感觉到它融合了多种语言的便捷的写法,写起来是比较舒服的。实现子集构造算法,将NFA状态集合的子集映射为DFA的单个状态。设计合理的数据结构来表示NFA和DFA,应包括状态集、状态转移表、初始状态和接受状态的表示。步骤4:设计并实现DFA的数据结构,将其表示为状态集合、状态转换表、初始状态和接受状态。步骤5:模拟DFA,验证对给定输入字符串的接受性,确保DFA
目录
实验目的
1.掌握正规表达式与有限自动机的基本概念和转换方法。
2. 了解非确定有限自动机(NFA)的构建过程。
3. 熟悉编程实现正规表达式到NFA转换的算法。
4. 掌握非确定有限自动机(NFA)与确定有限自动机(DFA)的基本概念及其转换⽅法。
5. 了解NFA到DFA转换过程中的子集构造算法。
6. 实现NFA到DFA的转换算法。
实验要求
1. 输入输出要求:
输入:正规表达式和多个测试字符串。
输出:生成NFA和DFA状态集合及其转换关系。
2. 算法要求:
⽀持基本的正规表达式运算符,如连接(ab)、或(a|b)、闭包(a*)。
实现Thompson构造法,将正规表达式分解为基本操作,然后逐步合成NFA。
实现子集构造算法,将NFA状态集合的子集映射为DFA的单个状态。 处理ε-闭包及其状态转换,生成对应的DFA。
3. 数据结构要求:
设计合理的数据结构来表示NFA和DFA,应包括状态集、状态转移表、初始状态和接受状态的表示。
数据结构需具备扩展性,以便在后续实验中使⽤,如NFA到DFA的转换、DFA的最小化。
考虑实现状态的唯⼀标识符,支持对状态进行增删查操作的⾼效实现。
算法描述
正规式转NFA算法描述
步骤1:解析输入的正规表达式,将其拆分为基本符号和运算符。实现正规表达式从中缀形式变换为后缀形式。仓颉代码如下:
//用'+'表示连接运算
func Add_symbol(regexp: String): String {
var regexp2: String = "" // 用来存储加工后的正则表达式
var c1: Rune // 当前字符
var c2: Rune // 下一个字符
var i: Int64 = 0
while(i < regexp.size - 1){
c1 = Rune(regexp[i])
c2 = Rune(regexp[i + 1])
regexp2 += String(c1)
// 如果当前字符和下一个字符不是运算符或括号,则需要加上连接符 '+'
if(c1 != r'(' && c2 != r')' && c1 != r'|' && c2 != r'|' && c2 != r'*'){
regexp2 += '+'
}
i++
}
// 将最后一个字符添加到新的表达式中
regexp2 += String(Rune(regexp[regexp.size - 1]))
return regexp2
}
//定义优先级
func Priority(ch: String): Int8 {
if(ch == '*') {return 3}
else if(ch == '+') {return 2}
else if(ch == '|') {return 1}
else {return 0} // 其他字符的优先级为0
}
//加工后的正规式转为后缀表达式
func RegExp_to_Postfix(regexp2: String): String {
var postfix: String = ""
var s2 : Stack<String> = Stack() // 运算符栈,用来临时存放运算符
var ch: String
// 遍历加工后的正则表达式
for(i in regexp2){
ch = String(Rune(i))
// 如果是字母(操作数),直接加入后缀表达式
if(ch <= 'z' && ch >= 'a') {postfix += ch}
// 如果是左括号 '(',将其压入栈中
else if(ch == '(') {s2.push(ch)}
// 如果是右括号 ')',将栈中的运算符出栈直到遇到左括号
else if(ch == ')') {
while(s2.top() != '(') {
postfix += s2.pop()
}
s2.pop()
}
else {
// 如果是运算符('+'、'|'、'*'),需要根据优先级判断是否出栈
while(!s2.isEmpty()) {
if(Priority(s2.top()) >= Priority(ch)) {
postfix += s2.pop()
}
else {break}
}
s2.push(ch)
}
}
//检查栈里是否还有剩余元素
while(!s2.isEmpty()) {
postfix += s2.pop()
}
return postfix
}
步骤2:按照Thompson构造法的规则,实现以下几种基本转换: 单个符号的NFA。 两个NFA的连接(拼接)。 两个NFA的并联(或操作)。 ⼀个NFA的闭包(星号操作)。
步骤3:合并所有子NFA,构建完整的NFA。
//分配空间
func Get_are() {
var newnode: FAnode = FAnode()
var newnode2: FAnode = FAnode()
nfa.append(newnode)
nfa.append(newnode2)
}
//处理a
func Do_ab(i: Int64) {
Get_are()
nfa[len].node[i].append(len + 1) // 将当前节点的 i 位置指向下一个节点
s.push(len)
s.push(len + 1) //将这两个节点入栈方便下一次与其他节点连接
len += 2 // 递增节点计数器,表明已经分配了两个新节点
}
//处理'*'
func Do_star() {
var b: Int64 = s.pop()
var a: Int64 = s.pop()
Get_are()
nfa[b].node[0].append(a)
nfa[len].node[0].append(a)
nfa[len].node[0].append(len + 1)
nfa[b].node[0].append(len + 1)
s.push(len)
s.push(len + 1)
len += 2
}
//处理'|'
func Do_or() {
var a: Int64 = s.pop()
var b: Int64 = s.pop()
var c: Int64 = s.pop()
var d: Int64 = s.pop()
Get_are()
nfa[a].node[0].append(len + 1)
nfa[len].node[0].append(b)
nfa[c].node[0].append(len + 1)
nfa[len].node[0].append(d)
s.push(len)
s.push(len + 1)
len += 2
}
//处理'+'
func Do_add() {
var d: Int64 = s.pop()
var b: Int64 = s.pop()
var a: Int64 = s.pop()
var c: Int64 = s.pop()
// NFA[a][0] = b
nfa[a].node[0].append(b)
s.push(c)
s.push(d)
}
//后缀表达式转为NFA(Thompson构造法)
func Postfix_to_NFA(postfix: String) {
var ch: String
for(i in postfix) {
ch = String(Rune(i))
if (ch <= 'z' && ch >= 'a') {Do_ab(Int64(i) - 97 + 1)}
else if (ch == '*') {Do_star()}
else if (ch == '+') {Do_add()}
else if (ch == '|') {Do_or()}
else {println("输入非法字符")}
}
}
步骤4:设计合理的数据结构表示NFA(本文中NFA的数据结构为一个动态数组里包含27个静态数组,静态数组里包含动态数组)
import std.collection.*
struct FAnode {
var node = Array(27, {_ => ArrayList<Int64>()})
}
var nfa = ArrayList<FAnode>()
var len: Int64 = 0
步骤5:实现NFA的模拟算法,判断输入字符串是否被NFA接受。
步骤6:进行测试,使用几个正规表达式和测试字符串验证程序的正确性。
NFA转DFA算法描述
步骤1:读取NFA的输入,包括状态集合、转换关系、初始状态和接受状态。
步骤2:计算NFA各状态的ε-闭包,并根据子集构造算法生成DFA的状态。
步骤3:根据输入符号集,对NFA状态集合进行扩展,生成对应的DFA转换关系。
//求状态t的ε闭包,返回包含所有可通过 ε 转换到达的状态的集合
func E_closure(t: Int64): HashSet<Int64> {
var I = HashSet<Int64>()
I.put(t)
for (j in nfa[t].node[0]) {
//如果状态集里没有这个元素
if (!I.contains(j)) {
//加入这个元素
I.put(j)
//求该元素的闭包
I.putAll(E_closure(j))
}
}
return I
}
//求状态子集I的ε闭包,在I的基础上增加ε闭包集合
func E_closure(I: HashSet<Int64>): HashSet<Int64>{
var I2 = HashSet<Int64>()
for (i in I) {
I2.putAll(E_closure(i))
}
return I2
}
//状态t的a边转换,不包括状态t
func Edge(t: Int64, a: Int64): HashSet<Int64> {
var I = HashSet<Int64>()
for (j in nfa[t].node[a]) {
//如果状态集里没有这个元素
if (!I.contains(j)) {
//加入这个元素
I.put(j)
//求该元素的a边转换
I.putAll(Edge(j, a))
}
}
return I
}
//状态集I的a边转换
func Edge(I: HashSet<Int64>, a: Int64): HashSet<Int64> {
var J = HashSet<Int64>()
for (t in I) {
J.putAll(Edge(t, a))
}
return J
}
//状态子集I的a边转换
func DFA_edge(I: HashSet<Int64>, a: Int64): HashSet<Int64> {
return E_closure(Edge(I, a))
}
//NFA转DFA(子集构造法Subset Construction)
func NFA_to_DFA() {
//求第一个状态子集,q0是NFA的开始状态
Dstates.append(E_closure(Get_q0()))
//目前做边转换的状态子集
var j: Int64 = 0
var ab = Get_ab()
var flag: Bool
while (j <= p) {
//遍历符号集合,是a则i为1
for (i in ab) {
var e = DFA_edge(Dstates[j], i)
flag = false
var newnode: FAnode = FAnode()
dfa.append(newnode)
//判断是否是已有的状态子集
for (k in 0..=p) {
//有
if (e == Dstates[k]) {
flag = true
//建立状态转换关系
dfa[j].node[i - 1].append(k)
break
}
}
//否,添加一个新的状态子集
if (!flag) {
p++
Dstates.append(e)
dfa[j].node[i - 1].append(p)
}
}
j++
}
}
步骤4:设计并实现DFA的数据结构,将其表示为状态集合、状态转换表、初始状态和接受状态。
步骤5:模拟DFA,验证对给定输入字符串的接受性,确保DFA与NFA的接受结果⼀致。
步骤6:进行测试。
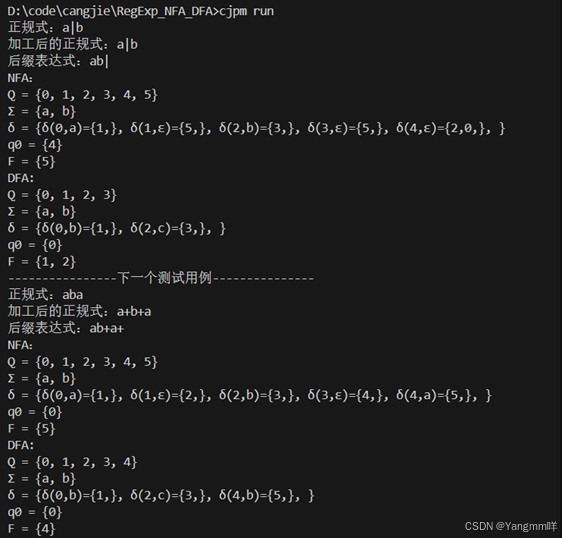
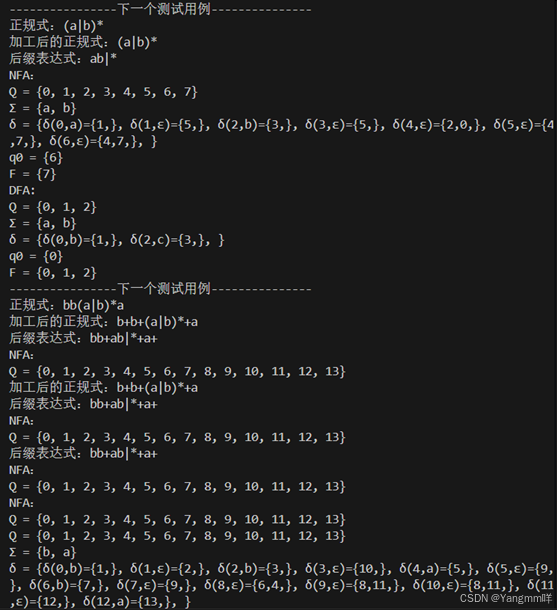
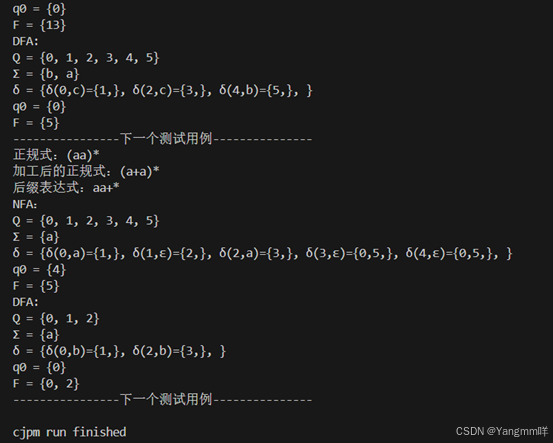
测试结果
main(){
for (regexp in ["a|b","aba","(a|b)*","bb(a|b)*a","(aa)*"]) {
nfa.clear()
dfa.clear()
len = 0
p = 0
Dstates.clear()
while(!s.isEmpty()){
s.pop()
}
Print_NFA(regexp)
NFA_to_DFA()
Print_DFA()
println("----------------下一个测试用例---------------")
}
}
实验随手记
字符类型有时候要加r或者Rune,有时候可以不用
单引号和双引号没有区分
字符和字符串不能用“+”连接
Array没有增删函数, ArrayList有
仓颉里没有switch用match
没有现成的栈
没有null也没有none,要用option才能有
插值字符串很好用print("${i}")
Rune(int型)会根据ascii码转换
给数组分配空间时不要分配同一空间,否则修改其中一个会影响另一个
动态数组赋值前要分配空间,不要把新空间定义为全局变量,否则还是同一空间
对仓颉的感受
这是一个大三学生在没系统学过仓颉的情况下第一次写的代码,有很多的不足之处,请谅解。虽然我只用到仓颉语言简单基础的语法,但能感觉到它融合了多种语言的便捷的写法,写起来是比较舒服的。
完整的代码在gitcode和github上有
GitCode - 全球开发者的开源社区,开源代码托管平台GitCode是面向全球开发者的开源社区,包括原创博客,开源代码托管,代码协作,项目管理等。与开发者社区互动,提升您的研发效率和质量。![]() https://gitcode.com/yangmie2/compilingyang-yang-a/compilation-experiment-with-cangjie: 正规式转NFA转DFA,消除左递归,消除左公共因子,求FIRTST集和FOLLOW集
https://gitcode.com/yangmie2/compilingyang-yang-a/compilation-experiment-with-cangjie: 正规式转NFA转DFA,消除左递归,消除左公共因子,求FIRTST集和FOLLOW集![]() https://github.com/yang-yang-a/compilation-experiment-with-cangjie
https://github.com/yang-yang-a/compilation-experiment-with-cangjie

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 35
35 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)