用仓颉完成编译原理实验-消除左递归和左公共因子,求FIRST集和FOLLOW集
1. 非终结符排序:对非终结符进行字典顺序排序(或者按某个其他特性排序,如出现顺序等)。2. 遍历非终结符:对于每个非终结符 Ai:查找其候选式是否有其他非终结符(排在 Ai 前面的非终结符)作为开头:如果有,将候选式中该非终结符为首用该非终结符的产生式替代,从而将可能的间接左递归转化为直接左递归。如果没有,跳过该候选式。对所有直接左递归的候选式进行处理,⽣成新非终结符,并转换产生式,使其无左递归
目录
实验目的
1. 理解上下文无关文法中左递归的概念及其对语法分析的影响。掌握消去上下文无关文法中直接和间接左递归的算法。
2. 理解上下文无关文法中的左公共因⼦的概念及其对语法分析的影响。掌握从上下文无关文法中提取左公共因子的算法,形成无⼆义性的语法结构。熟练运⽤数据结构(如 Trie 树)处理和优化文法。
3. 理解上下文无关文法中FIRST集和FOLLOW集的概念及其在语法分析中的重要性。掌握计算文法中FIRST集和FOLLOW集的算法及其实现。
实验内容
实现消去上下文无关文法中所有左递归的算法
具体步骤:
1. 对非终结符集合进行排序。
2. 按顺序遍历每个非终结符,检查其候选式是否以排在其前⾯的非终结符开头,并进行代换。
3. 消去直接左递归。
实验要求:
1. 输入:⼀个上下文无关文法,包括非终结符、终结符和产生式。
2. 输出: 消去左递归后的文法。
3. 算法: 应处理直接和间接左递归,确保输出文法与输入文法等价。
4. 测试:提供测试用例,验证算法的正确性。
实现从上下文无关文法中提取左公共因子的算法
具体步骤:
1. 对每个非终结符的候选式,识别最长的公共前缀。
2. 构建字典树(Trie),辅助提取最长公共前缀,将公共前缀提取为新非终结符的候选式。
3. 输出去除左公共因子的等价文法。
实验要求:
1. 输⼊⼀个上下文无关文法,包括非终结符、终结符和产生式。
2. 输出提取左公共因子后的文法。
3. 使用适当的数据结构(如 Trie 树)提高提取效率。
4. 确保输出文法无二义性,且与输入文法等价。
实现求解上下文无关文法的FIRST集和FOLLOW集的算法
具体步骤:
1. 输入上下文无关文法。输入时需要注意,想要多个字符作为一个终结符号,需要在每两个字符中间加上“`”。例如i`d,否则视为两个终结符号。
2. 计算每个非终结符的FIRST集。
3. 计算每个非终结符的FOLLOW集。
实验要求:
1. 输入一个上下文无关文法,包括非终结符、终结符和产生式。
2. 输出每个非终结符的FIRST集和FOLLOW集。
3. 算法应考虑文法的各种情况,确保输出结果准确。
设计方案与算法描述
设计文法的数据结构
文法的数据结构为哈希表,键是字符串,值是哈希集合,集合存储字符串,键按出现顺序存储非终结符号,集合存储该非终结符号的产生式。设置为集合因为产生式有多个且不重复。
//文法的数据结构:HashMap,键存产生式左部,值是哈希集合,存产生式右部
var Rmap = HashMap<String, HashSet<String>>()
//存储非终结符号集合
var Vnarr = ArrayList<String>()
实现消去上下文无关文法中所有左递归的算法
算法流程概述:
1. 非终结符排序:对非终结符进行字典顺序排序(或者按某个其他特性排序,如出现顺序等)。
2. 遍历非终结符:
对于每个非终结符 Ai:查找其候选式是否有其他非终结符(排在 Ai 前面的非终结符)作为开头:如果有,将候选式中该非终结符为首用该非终结符的产生式替代,从而将可能的间接左递归转化为直接左递归。如果没有,跳过该候选式。对所有直接左递归的候选式进行处理,⽣成新非终结符,并转换产生式,使其无左递归。
3.消除左递归后可能需要化简文法。
算法描述:
1. 识别直接左递归:文法规则形式为 A -> Aα | β ,其中 A 是⾮终结符,α 和 β 是任意的文法符号序列(终结符或非终结符),并且至少有⼀个 β 不以 A 开头。要消除直接左递归,可以引⼊⼀个新的非终结符 A' 来替换原产生式的左递归部分,并重新定义 A 的产生式如下:A -> βA' ; A' -> αA' | ε
2. 识别间接左递归:间接左递归的文法规则可能没有直接的形式 A -> Aα ,但是通过⼀系列的推导,A 可以推导出以 A 开头的字符串。消除间接左递归通常需要将间接左递归转换为直接左递归,然后应用直接左递归的消除方法。
3. 转换产生式:对于每个存在左递归的非终结符,引⼊新的非终结符作为辅助符号,并重新定义产生式以消除左递归。
仓颉代码如下:
//判断是否存在直接左递归,存在返回true
func Is_DLeft(Vn: String, P: HashSet<String>): Bool {
var count: Int64 = 0
for (rule in P) {
// 如果产生式的左部与 Vn 相同
if (String(Rune(rule[0])) == Vn) {
count++
}
}
//如果还存在不以Vn开头的产生式则是直接左递归
if (count > 0 && P.size > count) {return true}
else {return false}
}
//判断是否有间接左递归
func Is_IDLeft(): Bool {
for (i in 0..Vnarr.size-1) {
for (j in i+1..Vnarr.size) {
for (rule in Rmap[Vnarr[j]]) {
if (rule[0..1] == Vnarr[i]) {
return true
}
}
}
}
return false
}
//消去左递归算法
func Get_Left_Recursive() {
//存储经过算法后的文法
var LRmap = HashMap<String, HashSet<String>>()
//存储临时的文法
var LRmap2 = HashMap<String, HashSet<String>>()
LRmap.putAll(Rmap)
//如果有间接左递归,则转换为直接左递归
if (Is_IDLeft()) {
for (i in 0..Vnarr.size-1) {
for (j in i+1..Vnarr.size) {
for (rule in LRmap[Vnarr[i]]) {
if (String(Rune(rule[0])) == Vnarr[j]) {
LRmap[Vnarr[i]].remove(rule)
for (rule2 in LRmap[Vnarr[j]]) {
//用间接递归的产生式右部替代
LRmap[Vnarr[i]].put("${rule2}${rule[1..]}")
}
break
}
}
}
}
println("\n消除间接左递归后:")
Print_Rmap(LRmap)
}
else {
println("\n没有间接左递归")
}
var flag: Bool = false
//识别直接左递归
for ((k, v) in LRmap) {
//有直接左递归
if (Is_DLeft(k, v)) {
flag = true
LRmap2[k] = HashSet<String>()
LRmap2["${k}'"] = HashSet<String>()
for (rule in v) {
//如果产生式右部开头是产生式左部
if (String(Rune(rule[0])) == k) {
LRmap2["${k}'"].put("${rule[1..]}${k}'")
}
//β,不以k开头
else {
LRmap2[k].put("${rule}${k}'")
}
}
LRmap2["${k}'"].put("#")
Vnarr.append("${k}'")
}
else {
LRmap2.put(k, v)
}
}
if (flag) {
//将LRmap2的值放入LRmap
LRmap.clear()
LRmap.putAll(LRmap2)
LRmap2.clear
println("\n消除直接左递归后:")
Print_Rmap(LRmap)
}
else {
println("\n没有直接左递归")
}
//化简文法
//存储可以由开始符号推出的非终结符号
var Vnarr2 = ArrayList<String>(Vnarr[0])
//用数组模拟简单队列
var Vnqueue = ArrayList<String>(Vnarr[0])
while(Vnqueue.size > 0) {
var Vn = Vnqueue.remove(0)
// println("Vn${Vn}")
// println("size=${Vnqueue.size}")
for (rule in LRmap[Vn]) {
// println("rule=${rule}")
for (i in 0..=rule.size-1) {
var ch: String
if (i < rule.size-1 && rule[i+1..i+2] == "'") {
ch = rule[i..i+1]+"'"
}
else {
ch = rule[i..i+1]
}
//如果是非终结符号
if (Vnarr.contains(ch) && !Vnarr2.contains(ch)) {
Vnarr2.append(ch)
Vnqueue.append(ch)
// println("Vnqueue${Vnqueue}")
}
}
}
}
// println(Vnarr2)
//如果没有化简
if (Vnarr2.size == Vnarr.size) {
//do nothing
}
else {
for (Vn in Vnarr) {
if (!Vnarr2.contains(Vn)) {
LRmap.remove(Vn)
}
}
println("\n化简后:")
Print_Rmap(LRmap)
}
}
实现从上下文无关文法中提取左公共因子的算法
算法流程概述:
1.遍历每个非终结符的候选式,将它们插⼊对应的Trie 树。
2.在 Trie 中查找每个非终结符候选式的公共前缀。
3.以最长公共前缀生成新的非终结符,形成新的候选式,确保生成的文法无二义性且易于解析。
算法描述:
1.Trie 结构的使用:采用 Trie 树帮助分析和识别候选式中的公共前缀。
2.每个节点表示⼀个字符。
3.通过沿路径检查每条候选式的前缀分⽀情况,提取最长公共前缀。
仓颉代码如下:
//Tire树(用来查找字符串前缀)
class Trienode {
var childmap: HashMap<String, Trienode>
var childnum: Int64 //有几个子节点
var isend: Bool // 标记是否为某个单词的结束节点
public init() { //初始化
childmap = HashMap()
childnum = 0
isend = false
}
}
// 判断整个文法是否包含公共前缀
func Has_prefix(map: HashMap<String, HashSet<String>>): Bool {
var arr = ArrayList<String>()
for ((k, v) in map) {
for (rule in v) {
if (arr.contains(rule[0..1])) {
return true
}
else {
arr.append(rule[0..1])
}
}
arr.clear()
}
return false
}
// 判断该产生式右部是否包含公共前缀
func Has_prefix(v: HashSet<String>): Bool {
var arr = ArrayList<String>()
for (rule in v) {
if (arr.contains(rule[0..1])) {
return true
}
else {
arr.append(rule[0..1])
}
}
return false
}
// 构建Trie树
func Build_trie(word: String, root: Trienode) {
var p = root // 从根节点开始
// 遍历单词中的每个字符
for (w in word) {
//检查根节点是否有指向该字符的子节点
//没有,则创建,移动到该节点
var ch = String(Rune(w))
if (!p.childmap.contains(ch)) {
p.childmap[ch] = Trienode()
p.childnum++
p = p.childmap[ch]
}
//有,移动到该节点
else {
p = p.childmap[ch]
}
}
// 标记当前字符为单词的结束
p.isend = true
}
// 消除左公共因子总函数
func Remove_left() {
var CRmap = HashMap<String, HashSet<String>>()
//临时
var CRmap2 = HashMap<String, HashSet<String>>()
CRmap.putAll(Rmap)
//处理嵌套公共前缀
while(Has_prefix(CRmap)) {
for ((k, v) in CRmap) {
//如果有前缀
if (Has_prefix(v)) {
//对每一条产生式创建一个Trie树,得到前缀
var root: Trienode = Trienode()
for (rule in v) {
Build_trie(rule, root)
}
//得到公共前缀数组
var prefixarr = ArrayList<String>()
var str: String = ""
for (ch1 in root.childmap.keys()) {
var p = root.childmap[ch1]
str += ch1
// 如果当前子节点只有一个子节点且不是单词结尾,继续添加字符
while (p.childnum == 1) {
if (p.isend) {
break
}
var a = p.childmap.keys()
var b = a.toArray()
str += b[0]
p = p.childmap[b[0]]
}
if (p.childnum < 1) {
str = ""
}
else {
prefixarr.append(str)
str = ""
}
}
// println("左公共因子为${prefixarr}")
//得到消去公共前缀的文法
CRmap2[k] = HashSet<String>()
//分配空间
for (i in 0..prefixarr.size) {
CRmap2["${k}"+"'"*(i+1)] = HashSet<String>()
}
for (rule in v) {
var cp: Bool = false //判断是否有前缀
for (i in 0..prefixarr.size) {
//更新k,引入k'
var index = prefixarr[i].size
CRmap2[k].put("${prefixarr[i]}${k}"+"'"*(i+1))
//匹配前缀,更新k',加入后缀
if (rule.startsWith(prefixarr[i])) {
cp = true
if (rule[index..] == "") {
CRmap2["${k}"+"'"*(i+1)].put("#")
}
else {
CRmap2["${k}"+"'"*(i+1)].put(rule[index..])
}
}
}
// 如果规则没有公共前缀,直接加入原规则
if (!cp) {
CRmap2[k].put(rule)
}
}
}
else {
CRmap2.put(k, v)
}
}
CRmap.clear()
CRmap.putAll(CRmap2)
CRmap2.clear()
println("\n提取左公共因子后:")
Print_Rmap(CRmap)
}
}
实现求解上下文无关文法的FIRST集和FOLLOW集的算法
FIRST集计算:
1.基本规则:
对于每个终结符 a,将 FIRST(a),设置为{a}
对于每个非终结符 A,根据其产生式进行计算:
如果产生式为 A →aα,则将a加入FIRST(A)。
如果产生式为 A ->B1,B2...Bn,则依次计算B1的FIRST 集。若B1的 FIRST 集中包含空串 ε,则继续计算,B2以此类推。
FOLLOW集计算:
1. 基本规则:
对于开始符号S,将$加⼊FOLLOW(S) 。
初始化每个非终结符的FOLLOW(S)集为空。
2. 迭代计算过程:
设定⼀个标志变量 changed 用于检测FOLLOW集是否发生变化。
反复进行以下步骤,直到没有任何FOLLOW集发生变化为止:
遍历每个产生式A->αBβ:
将FIRST(β)中的所有符号(去除空串)加⼊ FOLLOW(B)。
如果β可以推导出空串ε ,则将FOLLOW(A)中的所有符号加⼊FOLLOW(B)。
仓颉代码如下:
var FIRST = HashMap<String, HashSet<String>>()
var FOLLOW = HashMap<String, HashSet<String>>()
//终结符号集合
var Vtset = HashSet<String>()
//初始化FIRST集
func init_FIRST() {
//将每个终结符号a加入FIRST(a)
for ((k, v) in Rmap) {
for (rule in v) {
// 初始化当前规则的FIRST集为空集合
FIRST[rule] = HashSet<String>()
var i: Int64 = 0
while (i < rule.size) {
var ch = rule[i..i+1]
//处理连接在一起的字符,如id
if (i < rule.size-2 && rule[i+1..i+2] == "`") {
ch = rule[i..i+1] + rule[i+2..i+3]
i = i + 3
}
// 如果是终结符号,加入到FIRST集中并跳到下一个字符
if (!Vnarr.contains(ch) && ch != "'") {
FIRST.put(ch, HashSet(ch))
Vtset.put(ch)
i++
}
else {i++}
}
}
}
// 对每个非终结符Vn初始化其FIRST集,如果可以推导出ε,加入ε
for (Vn in Vnarr) {
FIRST[Vn] = HashSet<String>()
//如果可以推出ε,把ε加入FIRST
if (Rmap[Vn].contains("#")) {
FIRST[Vn].put("#")
}
}
// println("非终结符号集合为${Vnarr}")
// println("终结符号集合为${Vtset}")
}
// 获取某非终结符Vn的FIRST集
func Get_firstVn(Vn: String): HashSet<String> {
for (rule in Rmap[Vn]) {
var i: Int64 = 0
while (i < rule.size) {
var ch = ""
//处理id
if (i < rule.size-2 && rule[i+1..i+2] == "`") {
ch = rule[i..i+1] + rule[i+2..i+3]
i = i + 2
}
else {
ch = rule[i..i+1]
}
//如果产生式为A -> aα则将a加⼊FIRST(A)是否可以合并
if (Vtset.contains(ch)) {
FIRST[Vn].put(ch)
break
}
//如果是非终结符号
else {
var first = Get_firstVn(ch)
//如果能推出ε
if (first.contains("#")) {
if (i == rule.size-1) {
FIRST[Vn].putAll(first)
}
else {
first.remove("#")
FIRST[Vn].putAll(first)
}
}
//不能推出,退出for循环
else {
FIRST[Vn].putAll(first)
break
}
}
i++
}
}
return FIRST[Vn]
}
// 计算所有非终结符的FIRST集
func Get_FIRST() {
init_FIRST()
var set = HashSet<String>()
println("\nFIRST集:")
//对于每个非终结符A
for (Vn in Vnarr) {
Get_firstVn(Vn)
for (rule in FIRST[Vn]) {
var rule2 = rule
rule2 = rule2.replace("#", "ε")
set.put(rule2)
}
println("FIRST(${Vn}) = ${set}")
set.clear()
//得到产生式右部的FIRST集
// for (rule in Rmap[Vn]) {
// Get_firstright(rule)
// // println("FIRST(${rule}) = ${FIRST[rule]}")
// }
}
}
// 初始化FOLLOW集
func init_FOLLOW() {
//将$加入FOLLOW(开始符号)
FOLLOW.put(Vnarr[0], HashSet("$"))
for (i in 1..Vnarr.size) {
FOLLOW[Vnarr[i]] = HashSet<String>()
}
}
// 计算所有非终结符的FOLLOW集
func Get_FOLLOW() {
init_FOLLOW()
var changed: Bool = true // 标记FOLLOW集是否更新
// 只要FOLLOW集发生变化,就继续迭代
while (changed) {
changed = false
for ((k, v) in Rmap) {
for (rule in v) {
var i: Int64 = 0
while (i < rule.size) {
var ch = rule[i..i+1]
while (i < rule.size-1 && rule[i+1..i+2] == "'") {
ch += "'"
i++
}
//终结符号则跳过
if (!Vnarr.contains(ch)) {
i++
continue
}
//是非终结符号
else {
// println("ch=${ch}")
var followch = FOLLOW[ch].clone()
// println("followch=${followch}")
//如果是最后一个字符
if (i == rule.size-1) {
// var follow = FOLLOW[k]
FOLLOW[ch].putAll(FOLLOW[k])
}
else {
//求下一个字符
var j = i+1
var nextch = rule[j..j+1]
while (j < rule.size-1 && rule[j+1..j+2] == "'") {
nextch += "'"
j++
}
//处理id
while (j < rule.size-2 && rule[j+1..j+2] == "`") {
nextch += rule[j+2..j+3]
j = j + 2
}
// println("nextch=${nextch}")
var first = FIRST[nextch].clone()
first.remove("#")
FOLLOW[ch].putAll(first)
//如果下一个字符可以推出ε
if (FIRST[nextch].contains("#")) {
FOLLOW[ch].putAll(FOLLOW[k])
}
}
// println(FOLLOW[ch])
// println(followch)
if (FOLLOW[ch] != followch) {
changed = true
// println("break")
break
}
}
i++
}
}
}
}
//打印FOLLOW集
println("\nFOLLOW集:")
for (k in FOLLOW.keys()) {
println("FOLLOW(${k}) = ${FOLLOW[k]}")
}
}
测试结果
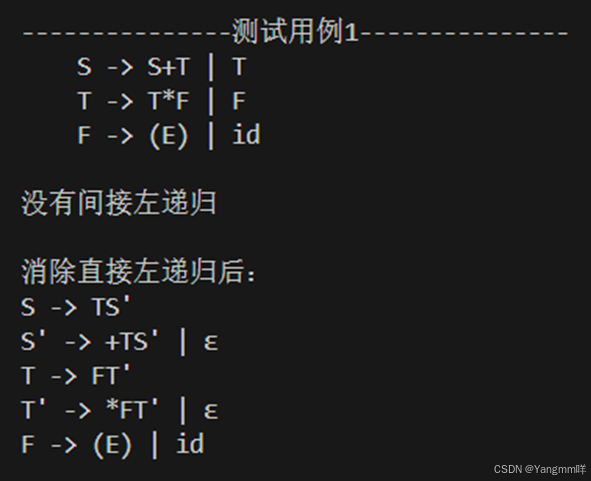
1.对测试用例1消除左递归,发现没有间接左递归,消除了直接左递归,打印算法后的文法
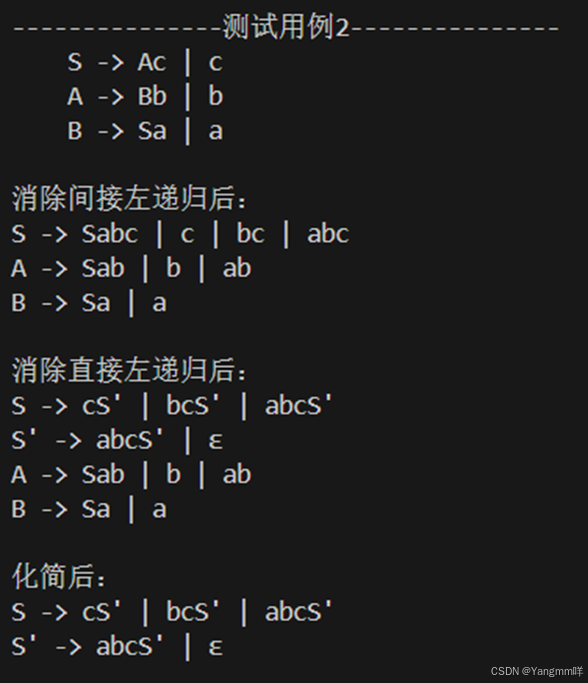
2.对测试用例2消除间接左递归后消除直接左递归,再进行文法的化简,打印文法
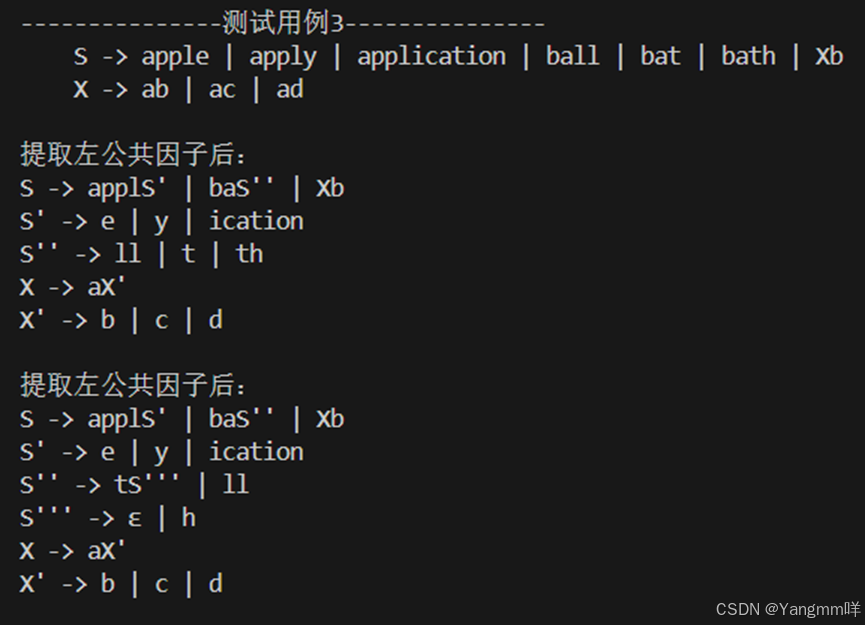
3.对测试用例3提取左公共因子后发现文法还存在左公共因子,再次进行提取左公共因子计算,打印文法
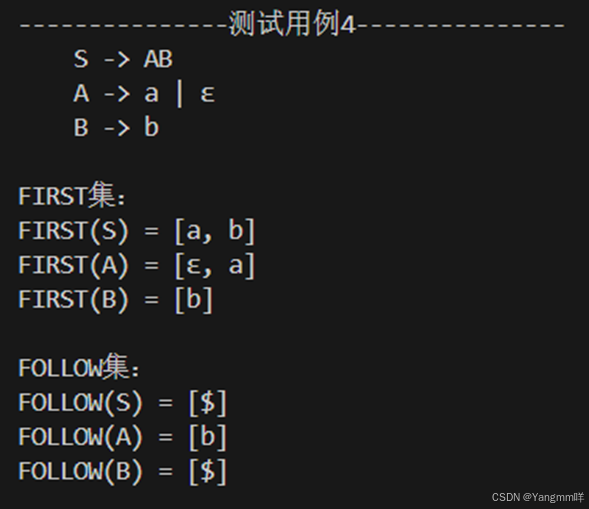
4.对测试用例4求FIRST集,FOLLOW集
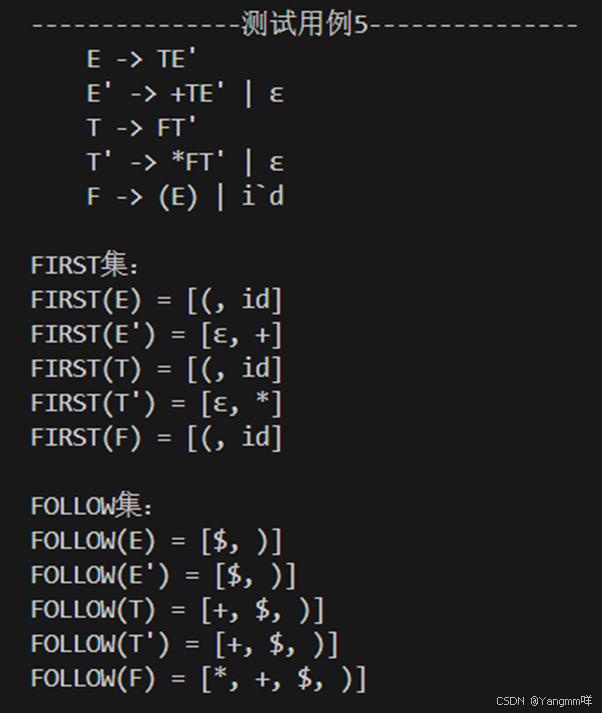
5.对测试用例5求FIRST集,FOLLOW集
实验随手记
1.在for in 循环的时候改变in右边的会报错
2.注意值传递和引用传递的区别,我的代码中Trie树得用class类型,不能用struct类型
值传递:在值传递中,函数接收的是参数值的副本。任何对参数的修改都只影响副本,而不会影响原始变量。大多数基本数据类型(如整数、浮点数、布尔值和字符串)都是通过值传递的。
引用传递:在引用传递中,函数接收的是参数引用的副本。这意味着对参数的任何修改都会影响到原始变量。对于复杂的数据结构(如数组、字典、对象等),很多语言默认使用引用传递。
3.对字符串进行一个范围的切片得到的是字符串,取一个值是ASCII码
Str[0]和Str[0..1]的类型不一样
4.HashSet 是引用类型,HashSet 在作为表达式使用时不会拷贝副本,同一个 HashSet 实例的所有引用都会共享同样的数据。想要拷贝HashSet的副本需要使用内置函数clone
对仓颉的感受
这是一个大三学生在没系统学过仓颉的情况下第二次写的代码,有很多的不足之处,请谅解。虽然我只用到仓颉语言简单基础的语法,但能感觉到它融合了多种语言的便捷的写法,写起来是比较舒服的。
完整的代码在gitcode和github上有

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)