玩转HarmonyOS AI——使用 Natural Language Kit 实现端侧本地化自然语言处理(NLP)
背景:为什么要在端侧做 NLP?
在传统 AI 应用中,自然语言处理(NLP)任务通常依赖云端大模型或自建推理服务。但这种方式存在三大痛点:
- 网络依赖:无网环境下无法使用;
- 隐私风险:用户输入需上传至服务器;
- 延迟高:往返通信增加响应时间。
而 HarmonyOS NEXT 提供的 Natural Language Kit(NLK),作为系统级 AI 能力组件,支持完全本地化、离线运行的 NLP 功能,覆盖分词、实体识别等常见任务,且无需额外模型部署。
本文将带你从零开始,调用 NLK 实现一个本地情感分析功能,并深入解析其能力边界与适用场景。
Natural Language Kit简介
Natural Language Kit(自然语言理解服务)提供多项文本语义理解基础能力,助力开发者高效处理和分析文本数据。该服务基于深度学习和自然语言处理技术构建,支持多种语言处理,可广泛应用于智能客服、内容审核、舆情分析等多个领域。
核心功能解析
1. 分词处理
- 功能说明:智能切分文本为独立词语单元,准确识别句子中的词汇元素
- 技术特点:
- 支持简体中文、英文、繁体中文等多语种分词
- 支持不超过1000字符的文本
- 应用场景:
- 搜索引擎索引构建
- 文本分类预处理
- 机器翻译的前置处理
- 示例:
- 输入:“我爱自然语言处理”
- 输出:[“我”, “爱”, “自然语言”, “处理”]
2. 实体识别
-
功能说明:精准提取文本中的特定意义实体
-
识别类型:
-
日期时间(DATETIME):提取文本中的具体日期,如“2024年6月18日”等。
-
电子邮件(EMAIL):识别文本中的电子邮件地址,如“***@example.com”。
-
快递单号(EXPRESS_NO):抽取文本中的快递单号信息。
-
航班号(FLIGHT_NO):定位文本中的航班号,如“CA1234”等。
-
地址(LOCATION):从文本中提取详细的地址描述。
-
人名(NAME):找出文本中出现的人名信息。
-
手机号(PHONE_NO):识别文本中的手机号码。
-
网址(URL):抽取文本中的网址链接。
-
验证码(VERIFICATION_CODE):定位文本中的验证码数字。
-
身份证号(ID_NO):识别文本中的身份证号码信息。
-
典型应用:
-
简历信息自动提取
-
合同关键信息识别
-
舆情监控中的事件要素提取
-
示例:
-
输入:“张经理将于5月20日访问北京分公司”
-
输出:
- 人名:张经理
- 时间:5月20日
- 地点:北京分公司
分词
适应场景
分词(Tokenization)的目的是将文本文件中的中文、英文、数字等混合内容切分成独立的词语或词组单元,为后续的文本分析和自然语言处理任务(如词向量表示、文本分类等)提供基础数据。具体来说:
- 分词的核心功能
- 中文处理:将连续的中文字符流切分成有意义的词语(如"人工智能"→"人工"/"智能"或整体保留)
- 英文处理:根据空格和标点切分单词(同时处理缩写和连字符情况)
- 数字处理:识别并保留数字组合(包括电话号码、金额等特殊格式)
- 典型应用场景
- 搜索引擎:用户输入"北京天气怎么样"会被分词为[“北京”,“天气”,“怎么样”],提取关键词进行检索
- 推荐系统:对商品描述"新款iPhone14 Pro 256GB"分词后匹配用户兴趣
- 情感分析:将评论"这部电影太精彩了"分解为可分析的词语单元
- 机器翻译:源语言文本需要先分词才能进行跨语言转换
- 技术实现特点
- 支持混合文本处理:"Python3.9安装教程"→[“Python”,“3.9”,“安装”,“教程”]
- 处理歧义情况:"南京市长江大桥"有多种切分方式
- 可配置词典:支持添加专业术语(如"5G网络"作为整体词)
- 上下文感知:根据前后文确定"行"在"银行"和"行业"中的不同切分
- 输出格式要求
- 保持原文本顺序
- 记录每个词的位置信息
- 区分词语类型(中文词/英文单词/数字/符号等)
- 支持特殊标记(如实体识别标签)
分词质量直接影响下游任务的准确性,因此需要根据具体场景选择合适的算法(基于词典/统计/深度学习的方法)和优化策略。
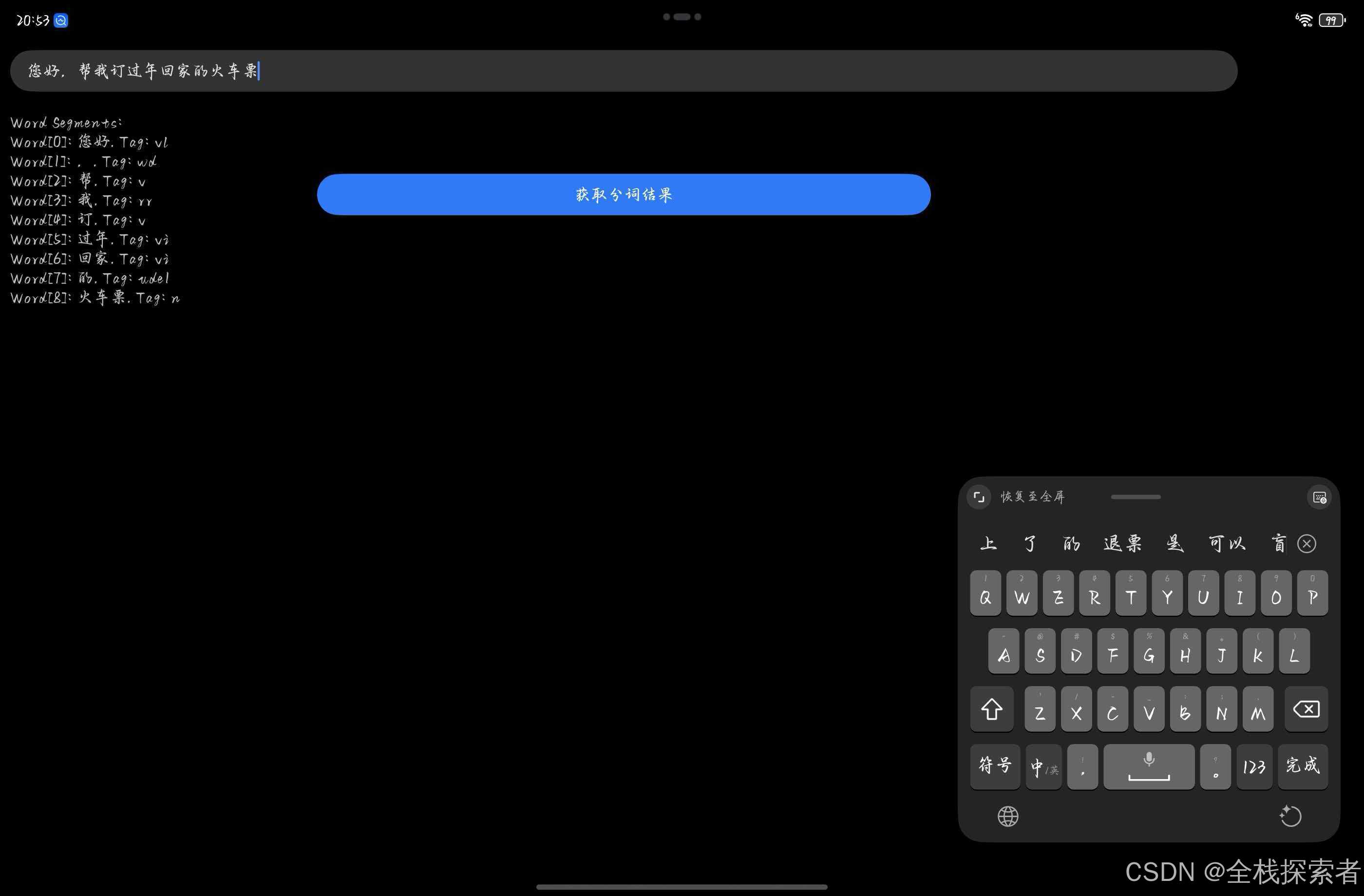
实现步骤
-
引入相关能力
import { textProcessing } from '@kit.NaturalLanguageKit'; -
输入文本
TextInput({ placeholder: '请输入待分词的文本' }) .height(40) .fontSize(16) .width('90%') .margin(10) .onChange((value: string) => { this.inputText = value; }) -
调用分词能力
Button('获取分词结果') .type(ButtonType.Capsule) .fontColor(Color.White) .width('45%') .margin(10) .onClick(async () => { try { let result = await textProcessing.getWordSegment(this.inputText); this.outputText = this.formatWordSegmentResult(result); } catch (err) { console.error(`getWordSegment errorCode: ${err.code}, errorMessage: ${err.message}`); } }) -
展示分词结果
Text(this.outputText) .height(40) .fontSize(16) .width('90%') .margin(10)
实体抽取
适用场景
实体抽取是自然语言处理(NLP)服务的一项核心能力,它通过分析文本的语义和上下文关系,从非结构化文本中准确识别并分类出多种类型的实体信息。这项技术主要基于深度学习模型(如BERT、BiLSTM-CRF等)和知识图谱技术,能够处理包括但不限于以下实体类型:
基础实体类型:
人名(PER):如"张三"、“李四"等
地名(LOC):如"北京市”、“黄浦江"等
组织机构(ORG):如"阿里巴巴”、“清华大学"等
时间(TIME):如"2023年5月1日”、"下午三点"等
领域特定实体:
金融领域:股票代码(如"600036")、金融产品等
医疗领域:药品名称(如"阿司匹林")、疾病名称等
电商领域:商品型号(如"iPhone14 Pro")、订单号等
应用场景示例:
新闻智能阅读:
对新闻正文进行多维度实体抽取
实现实体关联分析,如"马云"→"阿里巴巴"→"杭州市"的关系链
提供实体知识卡片展示,点击人名可显示人物简介
智能客服系统:
自动提取用户咨询中的关键实体
对快递单号进行正则校验(如SF123456789)
对手机号进行格式标准化(如13800138000→138-0013-8000)
结合业务知识库实现自动工单分类
金融风控场景:
抽取合同文本中的关键条款实体
识别交易记录中的异常账户信息
自动生成风险实体关系图谱
技术实现流程:
文本预处理:分词、词性标注、句法分析
特征提取:词向量表示、上下文特征捕获
实体识别:基于序列标注的实体边界检测
实体分类:通过分类器确定实体类型
后处理:实体消歧、标准化输出
当前主流实体抽取系统的准确率可达90%以上,部分垂直领域通过领域适配(fine-tuning)后能达到95%以上的识别准确率。这项技术正持续向多模态(结合图像、语音)、跨语言等方向发展,为各行业的智能化转型提供更强大的基础支持。
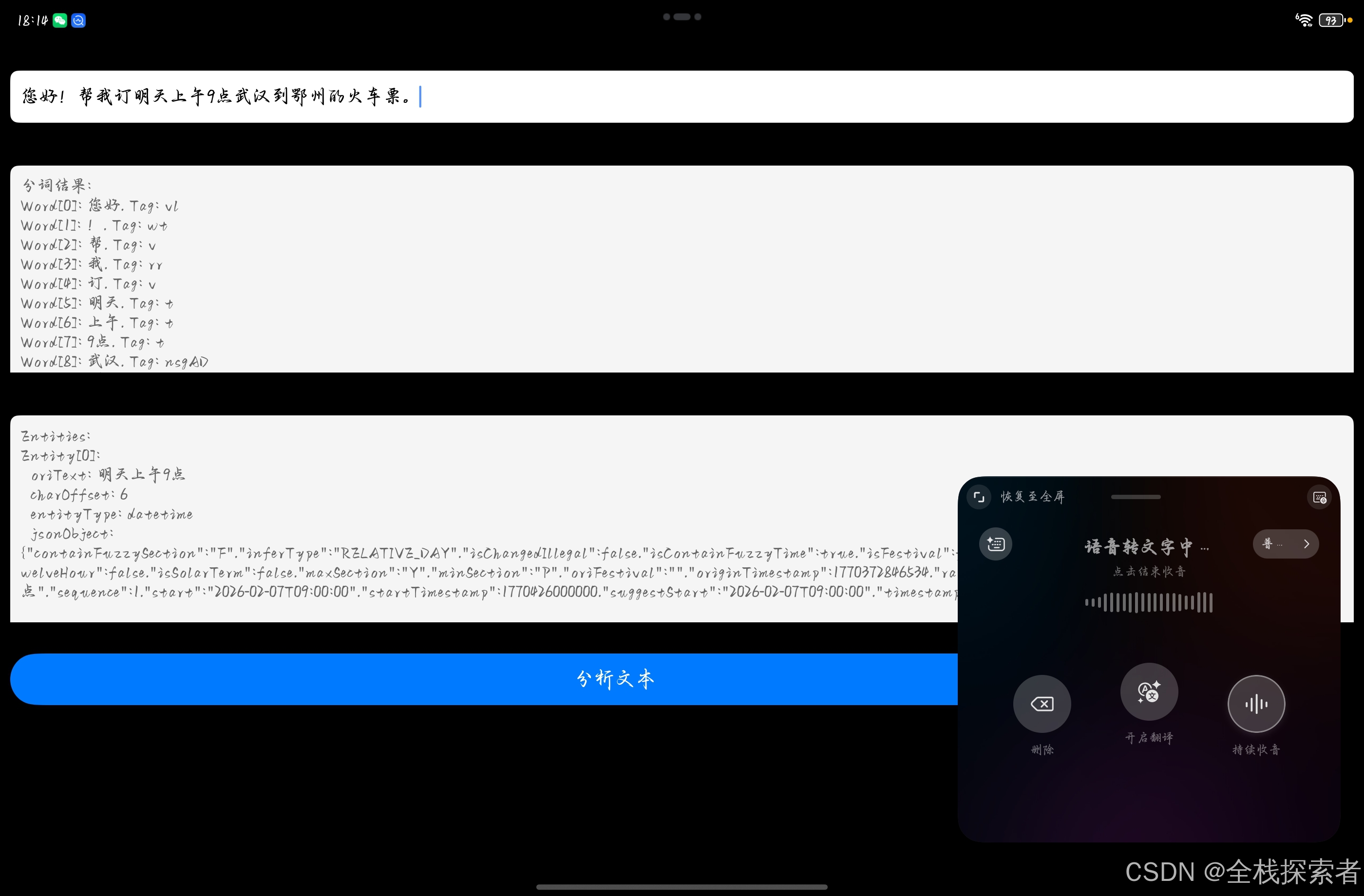
实现步骤
-
在使用实体抽取功能时,将实现实体抽取的类添加至工程。
import { textProcessing, EntityType } from '@kit.NaturalLanguageKit'; -
配置按钮,调用实体抽取
textProcessing.getEntity接口。Button('获取结果') .type(ButtonType.Capsule) .fontColor(Color.White) .width('45%') .margin(10) .onClick(async () => { try { let result = await textProcessing.getEntity(this.inputText, {entityTypes: [EntityType.NAME, EntityType.PHONE_NO]}); this.entityText = this.formatEntityResult(result); } catch (err) { console.error(`getEntity errorCode: ${err.code}, errorMessage: ${err.message}`); this.outputText = 'Error occurred while getting entities.'; } }) -
在界面上展示实体抽取结果。
private formatEntityResult(entities: textProcessing.Entity[]): string { if (!entities || !entities.length) { return 'No entities found.'; } let output = 'Entities:\n'; for (let i = 0; i < entities.length; i++) { let entity = entities[i]; output += `Entity[${i}]:\n`; output += ` oriText: ${entity.text}\n`; output += ` charOffset: ${entity.charOffset}\n`; output += ` entityType: ${entity.type}\n`; output += ` jsonObject: ${entity.jsonObject}\n\n`; } return output;
}
```
完整实现代码
import { textProcessing, EntityType } from '@kit.NaturalLanguageKit';
@Entry
@Component
struct Index {
private inputText: string = '';
@State outputText: string = '';
@State entityText: string = '';
private formatWordSegmentResult(segments: textProcessing.WordSegment[]): string {
let output = '分词结果:\n';
segments.forEach((segment, index) => {
output += `Word[${index}]: ${segment.word}, Tag: ${segment.wordTag}\n`;
});
return output;
}
private formatEntityResult(entities: textProcessing.Entity[]): string {
if (!entities || !entities.length) {
return 'No entities found.';
}
let output = 'Entities:\n';
for (let i = 0; i < entities.length; i++) {
let entity = entities[i];
output += `Entity[${i}]:\n`;
output += ` oriText: ${entity.text}\n`;
output += ` charOffset: ${entity.charOffset}\n`;
output += ` entityType: ${entity.type}\n`;
output += ` jsonObject: ${entity.jsonObject}\n\n`;
}
return output;
}
build() {
List({ space: 10 }) {
ListItem() {
Column() {
TextInput({ placeholder: '请输入待分词的文本' })
.height(50)
.fontSize(18)
.fontColor(Color.Black)
.width('100%')
.padding(10)
.borderRadius(8)
.backgroundColor(Color.White)
.onChange((value: string) => {
this.inputText = value;
})
}
.margin({ top: 20 })
}
ListItem() {
Column() {
Text('分词结果')
.fontSize(20)
.fontColor(Color.Black)
.margin({ bottom: 8 })
.width('100%')
Scroll() {
Text(this.outputText)
.fontSize(16)
.fontColor('#666')
.width('100%')
.padding(10)
.backgroundColor('#f5f5f5')
.borderRadius(8)
}
.height(200)
}
}
ListItem() {
Column() {
Text('实体识别')
.fontSize(20)
.fontColor(Color.Black)
.margin({ bottom: 8 })
.width('100%')
Scroll() {
Text(this.entityText)
.fontSize(16)
.fontColor('#666')
.width('100%')
.padding(10)
.backgroundColor('#f5f5f5')
.borderRadius(8)
}
.height(200)
}
}
ListItem() {
Button('分析文本')
.width('90%')
.height(50)
.fontSize(20)
.fontColor(Color.White)
.backgroundColor('#007aff')
.borderRadius(25)
.margin({ top: 20, bottom: 30 })
.onClick(async () => {
try {
let result = await textProcessing.getWordSegment(this.inputText);
this.outputText = this.formatWordSegmentResult(result);
} catch (err) {
console.error(`getWordSegment errorCode: ${err.code}, errorMessage: ${err.message}`);
}
try {
let result = await textProcessing.getEntity(this.inputText, {entityTypes: [
EntityType.DATETIME,
EntityType.LOCATION,
]});
this.entityText = this.formatEntityResult(result);
} catch (err) {
console.error(`getEntity errorCode: ${err.code}, errorMessage: ${err.message}`);
this.outputText = 'Error occurred while getting entities.';
}
})
}
}
.padding(10)
}
}
NLK vs 自定义模型:如何选择?
| 维度 | Natural Language Kit | 自定义 MindSpore Lite 模型 |
|---|---|---|
| 开发成本 | 极低 | 高(需训练、转换、集成) |
| 隐私性 | 系统级保障 | 依赖自身实现 |
| 定制化 | 不支持 | 完全可控 |
| 多语言 | 简体中文、英文、繁体中文 | 需自行训练 |
| 更新机制 | 随系统 OTA 升级 | 需手动推送新模型 |
✅ 推荐策略:
- 通用 NLP 任务 → 优先使用 NLK;
- 垂直领域(如金融、医疗)→ 结合 NLK + 自定义小模型做后处理。
结语
Natural Language Kit 是 HarmonyOS NEXT 赋能开发者“开箱即用 AI 能力”的典型代表。它让普通应用也能轻松具备本地化、低延迟、高隐私的智能语言理解能力。
对于 AI 工程师而言,这不仅是工具升级,更是思维转型:从追求模型规模,转向追求场景价值。
📌 提示:HarmonyOS NEXT 的 AI 能力仍在快速迭代,建议定期查阅 华为开发者联盟 - Natural Language Kit(自然语言理解服务) 获取最新接口。
欢迎留言讨论:你在鸿蒙开发中遇到过哪些 NLP 需求?是否考虑过端侧方案?

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐

 19
19 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)