使用 Claude Code 生产可持久化内容:HarmonyOS Snapshot 内存泄漏分析实践(THS)
本文记录了一次使用 Claude Code Opus 辅助分析 HarmonyOS Snapshot 内存泄漏的工程实践。与单次问答式分析不同,本文关注的是如何把分析过程中形成的资料、脚本、方法论和报告模板沉淀为可复用资产,使后续同类问题可以从已有知识和工具链继续推进。文章以分时页内存上涨问题为背景,介绍从资料准备、Skill 固化、脚本工具链建设,到自动化分析、人工复核和交叉验证的完整流程,并通
一、背景
分时页优化前的线上版本存在两个典型内存问题:
- 单次打开分时页时,进程内存申请峰值约为 220 MB;离开页面后,仍有约 110 MB 留存。
- 线上 OOM 率处于较高水平。
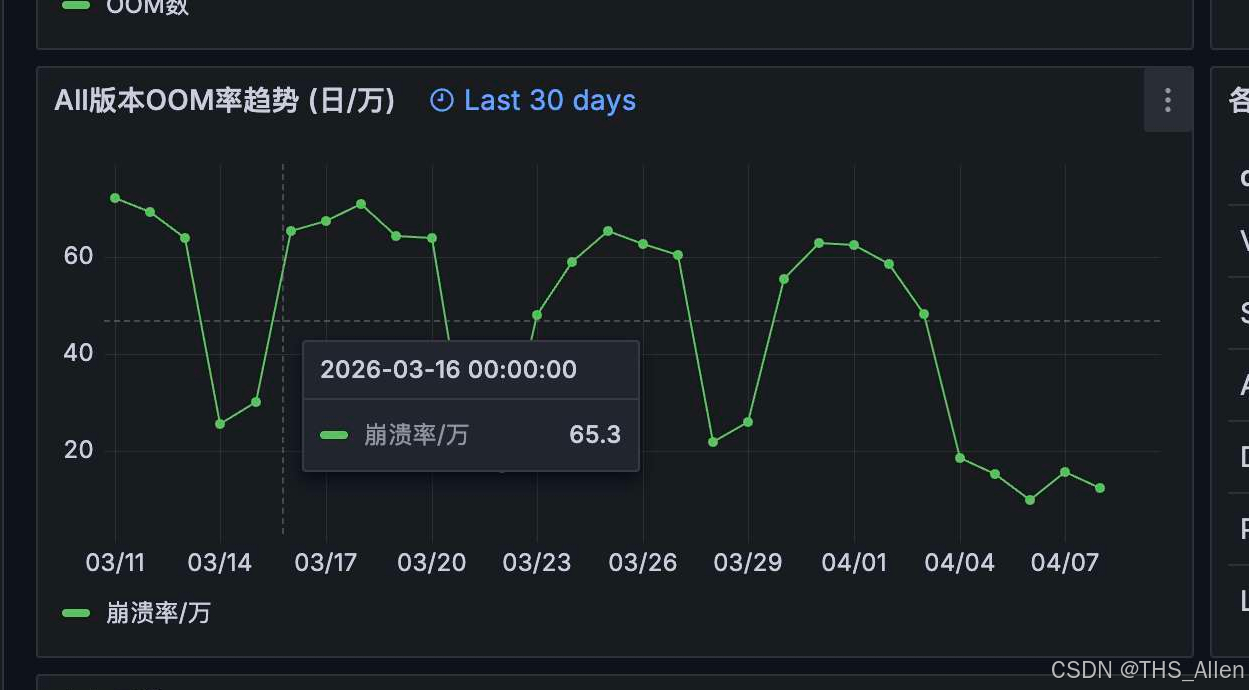
优化收益方面,在同一线上监控口径下,优化前稳定版本 H037.09.024 与优化后稳定版本 H037.09.027 对比,万人 OOM 率从 41.6 降低到 6.09。
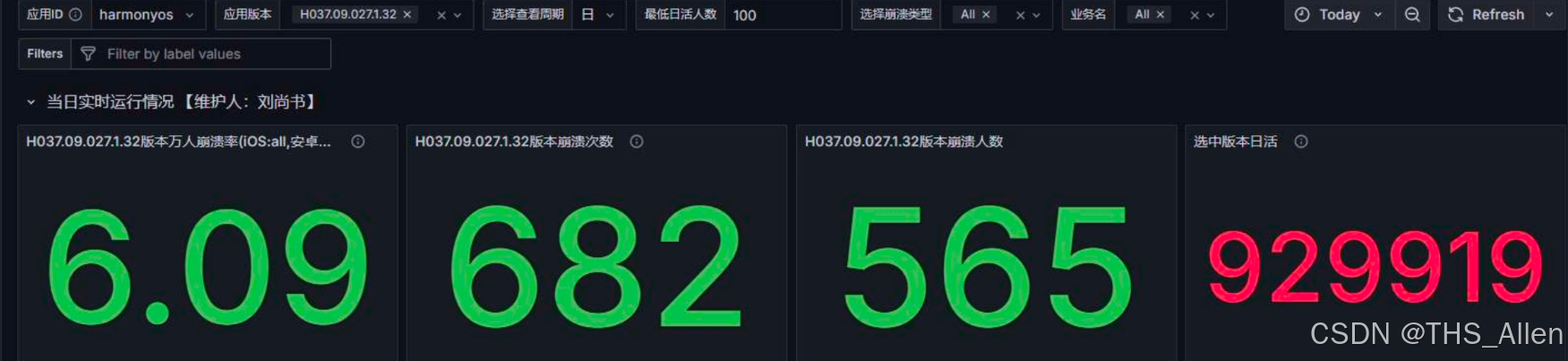
需要说明的是,线上指标通常会受到版本内容、用户分布、采样窗口和设备环境等因素影响。本文把 OOM 率变化作为问题背景和治理收益参考,不把它单独作为某个分析脚本或单个修复点的因果证明。
本文重点讨论的是:如何借助 Claude Code 把一次内存分析过程沉淀为后续可复用的工程资产。
把一次分析变成可复用资产
很多 AI 开发工作流停留在“当前会话给出一个结论”,围绕结论不断迭代提问。
这种方式在复杂工程问题里容易出现三个缺点:
- 会话结束后,资料、判断过程和脚本散落在上下文里,下次需要重新解释背景。
- 输出缺少稳定入口,换一个样本或换一个开发者后,流程难以复现。
- 结论依赖单次模型推理,缺少脚本化证据和人工复核边界。
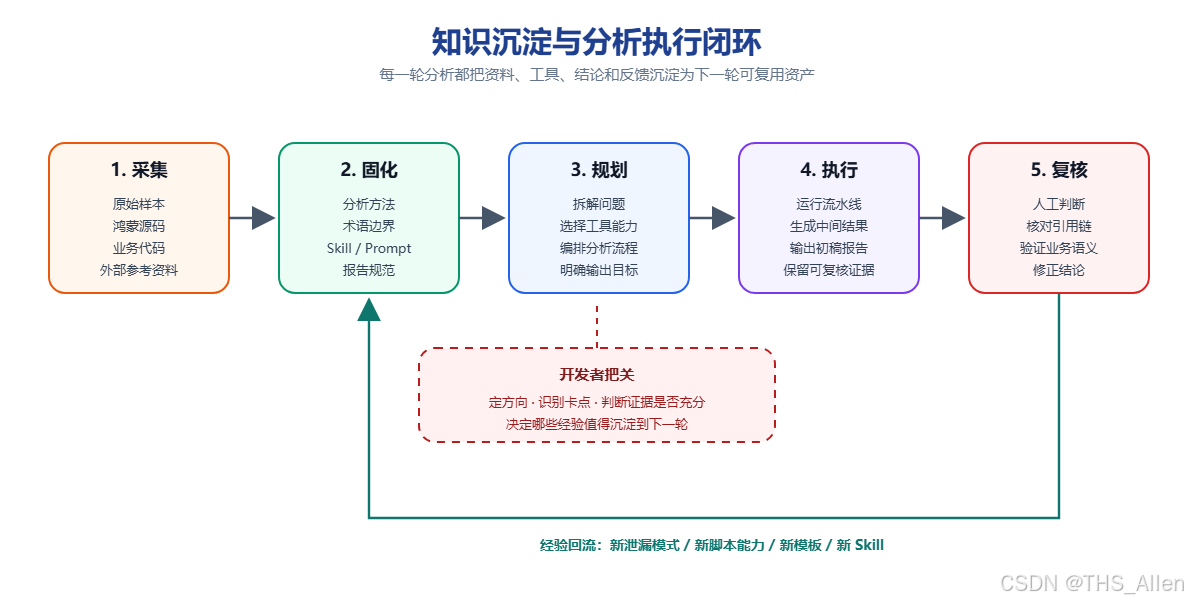
本次实践中,将每轮分析产出有意识地落到文件系统,并按用途拆成五类“可持久化内容”:
|
类别 |
载体 |
示例 |
|
领域知识 |
Markdown / Skill |
HarmonyOS Snapshot 分析笔记、ArkTS GC 资料、 |
|
分析方法论 |
Skill |
|
|
分析工具 |
Python 脚本 |
|
|
输出规范 |
报告 Skill |
|
|
执行入口 |
Prompt 模板 |
采集、分析、复核三类 Prompt |
这些内容的目标不是替代开发者判断,而是把重复性工作固化下来:资料可以被再次加载,脚本可以被再次执行,报告结构可以被再次套用,模型也可以在新会话里更快进入同一套问题空间。
二、数据对象与分析边界
本文先约定几个术语边界。
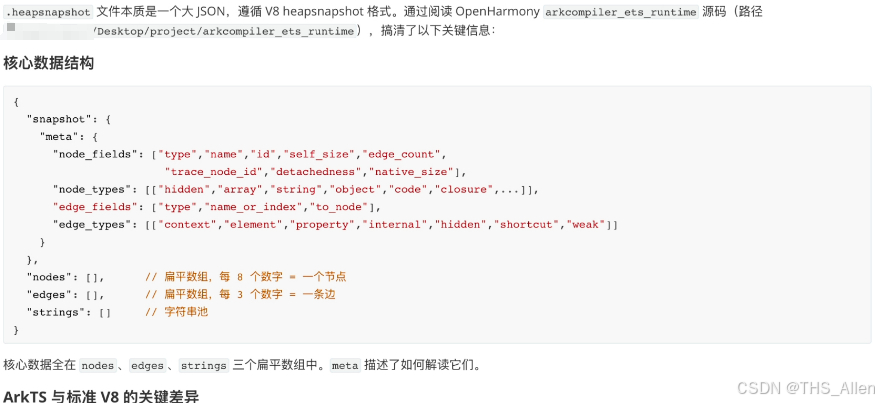
Snapshot:本文中的 snapshot 主要指 DevEco Profiler 导出的 .insight 样本中包含的 ArkTS 堆快照文件,常见后缀为 .heapsnapshot。它不是泛指所有 HarmonyOS 内存数据,也不等同于 Native Heap 或内核态内存数据。
.insight 文件:在本次样本中,.insight 文件可以按 ZIP 包解压,解压后包含一个或多个 .heapsnapshot、PSS 相关数据库、native hook 数据库和会话描述文件。不同 DevEco Studio 版本或不同采集模板的文件组织可能存在差异,因此投稿时更稳妥的表述是“在本次样本中观察到的结构”,而不是把它写成所有 .insight 文件的固定格式。
.heapsnapshot 格式:本次样本中的 .heapsnapshot 使用 JSON 表达对象图,核心字段包含 snapshot.meta、nodes、edges、strings 等。从字段组织和图分析方式看,它与 Chrome/V8 heap snapshot 有可类比之处,因此 V8/Chrome DevTools 的公开资料可以用于理解通用术语和分析方法。但实际分析对象仍然是 HarmonyOS/ArkTS 堆快照,节点语义、对象命名和 GC 行为必须以本次样本、ArkTS/OpenHarmony 源码和公开文档为准,不能把 V8 结论直接套用到 ArkTS 上。
循环引用与泄漏:真正需要关注的是:该循环结构是否仍可从 GC Root、模块作用域、全局注册表、事件总线或其他长生命周期对象到达。只有仍然可达,环及其下游对象才会持续保活。
Skill:本文所称 Skill 主要指在本项目中通过 ECC 插件沉淀出的可复用知识文件和流程文件。Claude Code 官方 Skills 通常以 SKILL.md 作为入口文件,具备目录结构、元信息和自动加载机制。本文中的 ECC learn 产物与官方 Skills 机制目标相似,都是为了跨会话复用知识,但具体文件组织和触发方式需要按实际工具链区分。
输入数据:一个 .insight 样本
分析开始时,可用输入非常有限:一个由 DevEco Profiler 导出的 .insight 文件。
在本次样本中,解压后的目录结构近似如下:
my_session/ ├── HEAP-1770961547611-14617.heapsnapshot # ArkTS 堆快照,JSON 对象图结构 ├── HEAP-1770961558481-14617.heapsnapshot # 多个采样时刻的堆快照 ├── xxx_memory.db # PSS 等内存分区数据 ├── xxx_native_hook.db # native 分配和调用栈相关数据 └── manifest.json # 会话信息
对 Agent 来说,这类数据并不是默认就能准确理解的。它需要知道 .heapsnapshot 的数组压缩结构、node_fields 与 edge_fields 的含义、ArkTS GC 相关背景,以及如何从 GC Root、引用链、依赖图和环结构推导可疑保活路径。由于公开资料中对 HarmonyOS Snapshot 内部结构、内存分析实践和真实案例的系统说明相对有限,前期工作的重点是先围绕鸿蒙源码和实际样本建立知识基础,再把可复用部分固化下来。
三、知识沉淀与工具链建设
先围绕鸿蒙源码和样本补齐知识
本次分析的对象是 HarmonyOS/ArkTS 产生的 heap snapshot,结论必须来自实际 .insight 样本、ArkTS/OpenHarmony 源码以及通过 Context7、Playwright 搜集到的公开文档信息。只是 HarmonyOS 侧公开的内存分析实践文档和案例相对有限,因此需要借鉴 V8/Chrome DevTools heap snapshot 中已经成熟的图结构分析方法,例如对象图、retainer path、双快照对比和可达性判断。这里的借鉴只用于理解通用分析思路和工具设计,不能替代对鸿蒙源码与样本数据的验证。
资料准备方式
本次使用的资料分为四类:
|
资料类型 |
用途 |
|
ArkTS 引擎源码 |
作为主要依据,理解 ArkTS 运行时、GC 和 heap snapshot 相关实现 |
|
OpenHarmony 源码 |
作为主要依据,理解系统侧对象、组件生命周期和框架行为 |
|
Context7 / Playwright / Web Search 搜集的公开文档 |
补充 HarmonyOS、DevEco Profiler、ArkTS、GC 和内存分析相关资料 |
|
V8 / Chrome DevTools 资料 |
作为参考材料,借鉴对象图、retainer path、双快照对比和可达性判断等通用分析方法 |
在实践中,可以通过人工提供、本地源码检索、Web Search、Context7 和 Playwright 等方式获取资料。重点不是固定使用某个检索插件,而是让外部资料能够落盘,并在后续会话中被重新加载。
本次给 Claude 提供或引导其检索的资料包括:
- ArkTS 引擎源码:
~/Desktop/project/arkcompiler_ets_runtime - OpenHarmony 源码:
~/Desktop/project/OpenHarmony/code - V8 源码:
https://github.com/v8/v8 - 通过 Context7、Playwright 搜集到的 HarmonyOS / DevEco Profiler / ArkTS 公开文档信息
V8 源码和 Chrome DevTools heap snapshot 资料只作为外部参考,用于借鉴对象图、引用路径、双快照对比等通用分析方法,不作为 HarmonyOS 内存结论的直接依据。
本次使用过的三类 Prompt 如下。
Prompt 1:采集 HarmonyOS 内存分析相关资料
需要对'左右滑动+分时日线周线五日线.insight'进行内存泄漏分析, 这是一个 HarmonyOS .insight 样本,包含多次 ArkTS heap snapshot。 请通过 Context7 和 Playwright 探索 HarmonyOS / DevEco Profiler / ArkTS 内存分析相关资料, 将内存泄漏、快照分析、GC、组件生命周期相关资料整理为 Markdown, 保存到当前目录的 docs/office 目录下。
Prompt 2:补齐 GC 与 heap snapshot 背景
需要对'左右滑动+分时日线周线五日线.insight'进行内存泄漏分析, 这是一个 HarmonyOS .insight 样本,分析结论必须以 ArkTS/OpenHarmony 源码、公开文档和样本数据为准。 请阅读本地 ArkTS 引擎源码、OpenHarmony 源码, 通过 Context7、Playwright 搜集 HarmonyOS / DevEco Profiler / ArkTS 公开文档, 并参考 V8 / Chrome DevTools heap snapshot 资料中的通用对象图分析方法, 整理一份专业、客观、详细的 GC 与 heap snapshot 分析背景报告。 报告需要说明:哪些结论来自鸿蒙源码和样本,哪些内容只是外部资料的借鉴。
Prompt 3:沉淀 snapshot 分析指导
请基于已整理的 ArkTS/OpenHarmony 源码、公开文档、本次样本结构和外部参考资料,总结 HarmonyOS heap snapshot 的数据结构、解析方法和内存泄漏定位流程。 重点覆盖 nodes / edges / strings / meta、retainer path、依赖图、双快照对比和循环引用识别。 请将结果保存为可复用的 md 指导文档。
这三类 Prompt 的共同点是:明确任务对象,明确资料来源,明确落盘目录,明确后续要复用。
知识准备后的效果
完成资料准备后,Claude 已能辅助完成以下任务:
- 结合样本中的
meta信息,解释.heapsnapshot中node_fields、edge_fields、node_types、edge_types等结构。 - 理解 GC Root、引用链、对象保活和泄漏判断之间的关系。
- 初步生成解析脚本,对多个 snapshot 做趋势、对比和可疑对象提取。
到这一步,知识仍然分散在会话上下文和 Markdown 文档里。下一步要解决的是:如何让这些知识在新会话里被稳定复用。
用 Skill 固化知识
把资料保存为 Markdown,开新对话时就需要重新读取,同时需要占用大量的上下文,需要将他们进行总结归纳,并将长篇内容做成外部引用。
对于跨会话复用而言,每次只喂关键信息:什么场景下应该加载哪些知识,按什么步骤执行,输出应该符合什么结构。
本项目使用 ECC 插件的 learn 能力,把当前会话中已经验证过的知识和流程整理为可复用 Skill。

本项目中沉淀的 Skill 大致分为三类:
|
Skill 类型 |
解决的问题 |
示例 |
|
领域知识 Skill |
让模型理解 ArkTS/GC 语义,并借鉴 heap snapshot 通用图分析方法 |
HarmonyOS Snapshot 分析笔记、 |
|
流程 Skill |
让模型按固定步骤分析 |
|
|
输出 Skill |
让模型按统一结构生成报告和复核清单 |
|
这种组织方式的好处是:知识、流程和输出规范被拆开维护。后续换一个模块或换一个 snapshot 样本时,通常只需要调整业务配置和 Prompt,而不需要重新解释 HarmonyOS snapshot 的样本结构、ArkTS 运行时背景和通用对象图分析方法。
构建脚本化工具链
有了前置知识后,Claude 不再只是解释单个快照,而是可以参与工具链设计。实践中先让 Claude 基于已有 Skill 和项目背景产出分析计划,再把计划拆成可执行脚本。
示例规划 Prompt:
/ecc:plan 设计一个详细的内存泄漏分析计划。 目标是对“左右滑动+分时日线周线五日线.insight”进行并行内存泄漏分析, 并生成专业、可复核的分析报告。 请将计划保存到项目的 plan 目录下。
后续迭代围绕几个核心问题展开:
- 如何基于样本
meta解析.heapsnapshot中的压缩数组结构。 - 如何构建节点和边组成的对象图。
- 如何寻找从 GC Root 到目标对象的 retainer path。
- 如何做双快照对比,找出增长对象类型。
- 如何识别循环引用,并把关键回边可视化。
经过多轮迭代,脚本从零散文件演进为分层工具集。顶层是一键入口 analyze_insight.py,底下按“基础层 / 单快照分析 / 辅助工具”组织,并通过可选的 leak_config.json 支持跨项目复用。
analyze_insight.py # 一键入口,自动编排以下脚本
│
├── lib/ # 共享基础层,被 import,不直接执行
│ ├── heap_core.py # 数据加载与图构建
│ └── leak_config.py # 业务配置加载
│
├── analysis/ # 单快照与双快照分析
│ ├── retainer_path.py # 引用链追溯
│ ├── cycles.py # 环检测
│ ├── compare.py # 双快照对比
│ ├── dominator_tree.py # 可选:支配树与保留量辅助分析
│ ├── visualize.py # 交互式 HTML 可视化
│ └── pss.py # PSS 分区趋势
│
└── tools/ # 辅助工具
├── snapshot_timeline.py # 多快照时间线对比
├── inspect_node.py # 单节点深度探查
├── view_tracker.py # ViewPU 组件追踪
└── clean_app_cache.sh # 设备缓存清理
一条命令可以跑完整条分析流水线:
python3 script/analyze_insight.py path/to/xxx.insight
产物按固定目录组织:
script/out/{insight_name}/
├── overview.txt # 多快照趋势
├── pss.txt # PSS 分区趋势
├── S1/ # 单快照分析
├── S2/
├── S3/
└── S1_vs_S3/ # 双快照对比
脚本执行顺序也被 harmonyos-memory-leak-analysis-skill.md 固化为标准分析流程:
- 解压
.insight,识别快照、PSS 数据和 native 数据。 - 运行
snapshot_timeline,确认整体增长阶段。 - 运行
pss,判断增长主要来自 ArkTS heap、native heap 还是其他分区。 - 运行
compare,找出基线快照与峰值快照之间增长最多的对象类型。 - 运行
retainer_path,从 GC Root 追踪可疑对象的保活路径。 - 运行
cycles,识别闭包自引用、组件互引用等环结构。 - 运行
dominator_tree,辅助查看对象保留量和保留范围。 - 运行
visualize,生成可交互依赖图,用于人工核对关键引用链和回边。
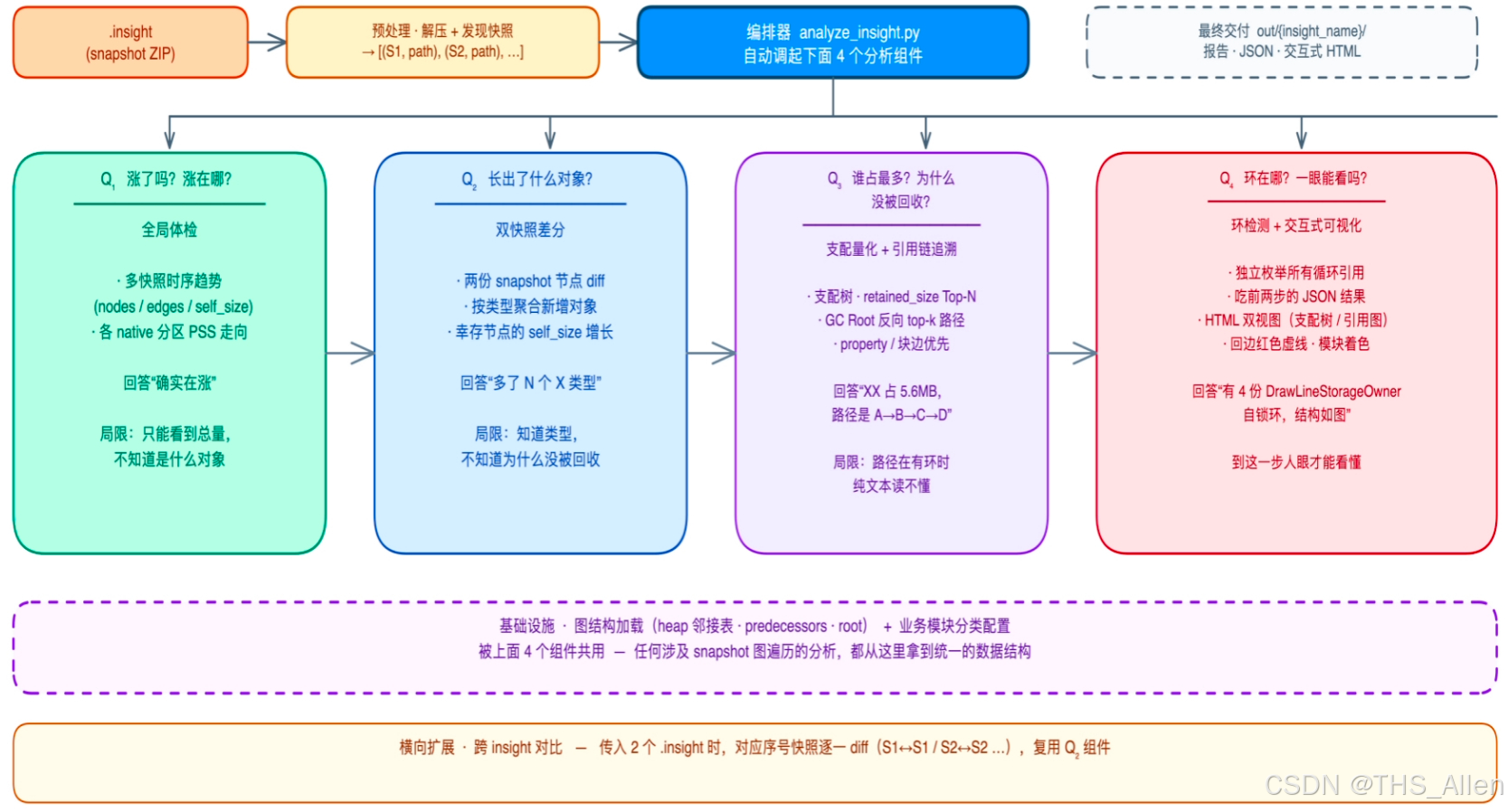
上图展示的是完整工具链能力,这一阶段的关键变化是:知识不再停留在说明文档中,而是被固化为脚本、配置和执行顺序。
模型的作用也从“自由发挥分析”变成“按既定方法编排工具、解释结果、补充报告”。
执行分析并生成报告
实际使用时,并不一定由开发者手动执行每个脚本,而是把任务交给 Claude,由它根据 Skill 匹配流程并调用一键入口。
Prompt:
path/to/左右滑动+分时日线周线五日线.insight 是一个鸿蒙snapshot数据。 快照时序为:S1 打开页面前,S2 首次进入分时页,S3 多次切股后,S4 离开页面后,S5 等待一段时间后。 请按 harmonyos-memory-leak-analysis-skill 的流程分析内存泄漏, 运行已有脚本,并将分析报告生成到指定目录。
Agent 收到任务后,会读取相关 Skill,调用 analyze_insight.py 跑完整条流水线,并根据 overview.txt、pss.txt、retainer.json、compare.txt、可选的 dominator.json 和可视化结果生成报告。脚本执行阶段可以高度自动化,但关键结论仍需人工抽样复核,尤其是以下几类判断:
- 采集到的对象是否与实际业务逻辑对应。
- 修复方案是否正确有效,代码修改是否会影响到其他模块,修复建议是否会破坏页面生命周期或事件订阅语义。
- 分析报告中的增长对象是否排除了正常缓存、懒加载等情况。
四、案例:DrawLineStorageOwner 覆盖未释放
业务场景
分时页支持用户左右滑动切换股票。按预期,切股后旧股票相关数据和不再使用的组件引用应被释放;但在本次样本中,旧组件树没有释放干净,并在多次切股后持续累积。
本案例主要由 Claude/Opus 调用前述脚本生成初稿结论,再经过人工复核和整理。
引用路径与环结构给出关键线索
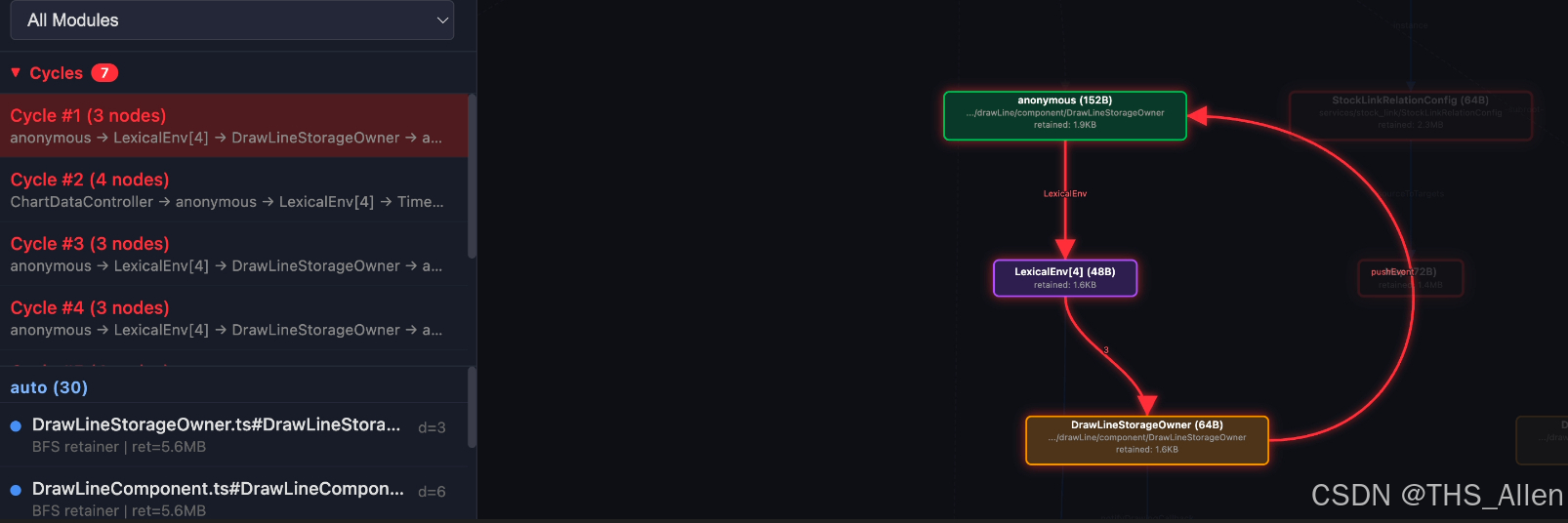
retainer.txt 文本版记录了目标对象到 GC Root 的最短线性路径;retainer.json 中额外包含脚本识别到的 cycles 字段。其中 4 个环与 DrawLineStorageOwner 相关,对应多次切股留下的多份独立副本。
DrawLineStorageOwner 把注册出去的闭包又存回自身 pushEvent 字段,形成 owner 与 closure 之间的闭合环。但需要强调的是,真正导致持续保活的不是“有环”本身,而是这个环仍然存在外部锚点:一条 -subroot- 边将 closure 挂到 GC Root 下,另一个 LexicalEnv 从模块作用域指向 owner。只要任一外部锚点存在,该环及其下游组件树就仍可能无法回收。
依赖图可视化辅助人工核对
visualize.py 生成的 S3/vis.html 将关键依赖图和环结构画出。回边以红色虚线标记,Cycles 面板按环编号列出多份副本,方便人工核对每一份残留对象是否对应一次切股。
五、复盘与可复用经验
这套流程的自动化程度并不均匀。适合脚本化的部分应尽量固定下来,需要业务判断的部分则必须保留人工复核。
|
环节 |
自动化程度 |
人工介入点 |
|
|
脚本自动化 |
通常不需要 |
|
timeline / PSS 初筛 |
脚本自动化 |
确认采样时序是否正确 |
|
compare / retainer / cycles 定位 |
脚本自动化 |
抽样核对关键引用链和环结构 |
|
dominator_tree 辅助分析 |
脚本自动化 |
在需要保留量视角时使用 |
|
根因归纳与代码映射 |
半自动 |
阅读源码并确认生命周期语义 |
|
修复实现 |
人工为主,AI 辅助 |
Code Review、回归验证 |
|
Codex 交叉复核 |
半自动 |
分歧点人工裁决 |
|
最终报告生成 |
模板辅助 |
结论复核、表达润色 |
本项目还使用 Codex 做交叉验证。做法是将相同背景资料、脚本和 snapshot 提供给 Codex,让它独立跑一遍分析流程,再将 Claude 与 Codex 的报告互相复核。两边一致的结论可信度更高;两边分歧的地方则优先交给人工复核。
这种“脚本证据 + 模型解释 + 人工决策”的组合,比单次模型回答更适合复杂内存问题。模型擅长整合资料、生成脚本和解释现象;脚本负责可重复计算;开发者负责判断业务生命周期、确认源码语义和决定修复策略。
可复用经验
本次实践中,最有复用价值的不是某一个具体 Prompt,而是下面的规范:
第一,先落盘,再迭代。 搜索到的资料、调通的脚本、确认过的结论都应保存到项目目录或 Skill 目录。只存在对话窗口里的知识,很难在下一次问题中稳定复用。
第二,区分样本事实、模型推断和人工结论。 timeline、compare、retainer path、cycles 输出属于样本事实;“疑似事件总线注册”属于基于路径的推断;最终根因和修复建议必须经过人工结合源码确认。
第三,脚本优先处理可规则化工作。 解压、解析、排序、对比、路径搜索、可视化都适合脚本化。模型应更多承担编排、解释和生成报告的工作,而不是每次重新“凭感觉”判断。
第四,报告模板也需要版本化。 内存分析报告不是简单列 Top N 对象,而应包括采样时序、增长阶段、PSS 分区、保活路径、可疑根因、排除项、修复建议和验证方式。
结语
这次实践表明,Claude Code 在复杂内存问题中的价值,不只在于“回答一次问题”,更在于帮助开发者把知识、脚本和判断流程沉淀成可复用资产。
这份文档实践于 26 年 2 月,具有一定时效性。截至 2026 年 4 月,相关工具仍在快速变化,新出的开源项目和插件可能会覆盖本文中的部分步骤。
相对稳定的是从学习到输出的迭代过程:学习 → 输出 → 校验 → 再学习。本文只是把这套方法迁移到 AI 辅助开发和内存分析场景中。

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)