NaturalLanguageKit自然语言处理服务开发实录
让 App 看懂你说的话——Natural Language Kit 自然语言处理开发手记
你有没有好奇过,手机上那些"智能助手"是怎么理解你说的话的?比如你对它说"明天北京天气怎么样",它就能识别出"明天"是时间、"北京"是地点、"天气"是你要查的东西。这种"理解人类语言"的能力,背后就涉及自然语言处理(NLP,Natural Language Processing)。
华为 HarmonyOS 提供了一个叫 Natural Language Kit(自然语言理解服务) 的 SDK,里面封装了一些常用的自然语言处理能力。今天这个 Codelab 教我们两个功能:
- 分词(Word Segmentation)——给一段文字,自动把它拆分成一个个有意义的词。比如"我明天要去北京出差"会被拆成"我"、“明天”、“要”、“去”、“北京”、“出差”。
- 实体抽取(Entity Extraction)——从文字里提取出命名实体,比如人名、地名、机构名之类的。比如"张三去了腾讯总部"会抽出"张三"(人名)、“腾讯”(机构名)。
这两个能力看起来简单,但实际应用场景很多。比如搜索框的智能提示(你输入几个字它就能猜到你要搜什么)、聊天机器人的意图理解、内容审核里的敏感词检测等等,底层都要用到分词和实体抽取。
环境准备
老规矩,先确认环境:
- DevEco Studio:6.1.0 Release 及以上
- HarmonyOS SDK:6.1.0 Release SDK 及以上
- 设备:华为手机、平板或 2in1
- 系统:HarmonyOS 5.0.5 Release 及以上

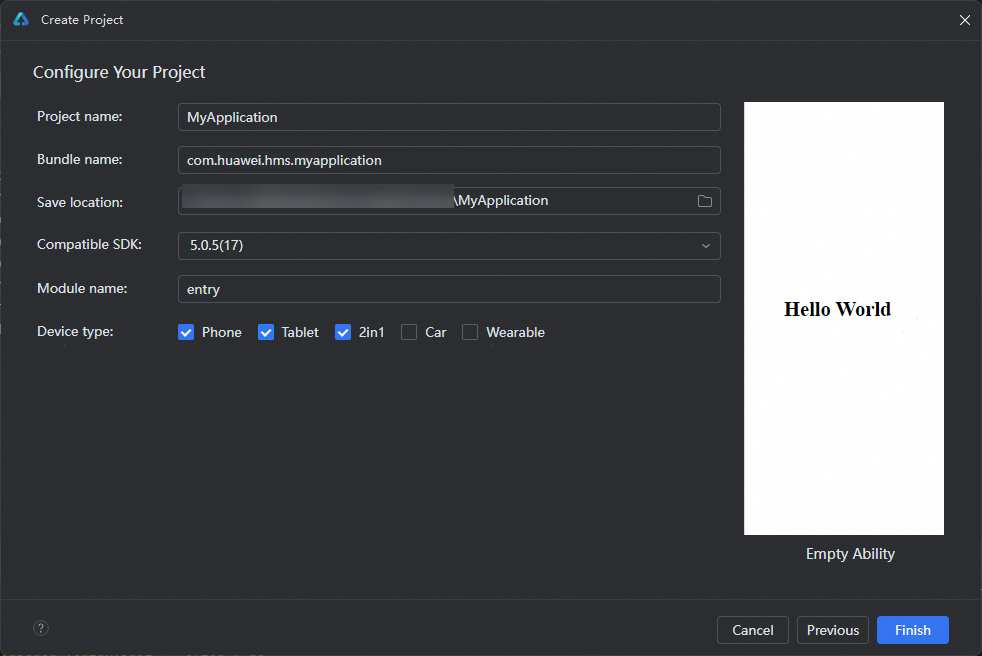
工程结构
这个 Demo 的结构非常简洁:
├─entry/src/main/ets // 代码区
│ ├─entryability
│ │ └─EntryAbility.ets // 入口Ability
│ └─pages
│ └─Index.ets // 主页界面
├─entry/src/main/resources // 应用资源目录
└─screenshots // 截图
就一个页面 Index.ets,所有功能都在里面。这倒也合理——这个 Demo 的核心就是两个 API 调用,确实不需要拆太多文件。
导入依赖
import { hilog } from '@kit.PerformanceAnalysisKit';
import { textProcessing } from '@kit.NaturalLanguageKit';
两个 import,一个日志工具,一个自然语言处理的核心包。
textProcessing 这个名字起得很有意思——“文本处理”。它不像 CoreVisionKit 里的 faceDetector、textRecognition 那样按功能细分命名,而是用了"文本处理"这个更宽泛的名字。这说明这个包未来可能会加入更多功能(比如情感分析、文本分类之类的),现在先上了分词和实体抽取两个最基础的能力。
注意看,这个 Demo 里没有导入 BusinessError。为什么?因为源码里用的是 catch (err) 而不是 catch (err: BusinessError),所以不需要单独导入错误类型。不过在正式项目里,我建议还是加上,这样你在 catch 的时候就能用 err.code 和 err.message 来做更精确的错误处理,而不是用 err 这个 any 类型。
页面 UI
@Entry
@Component
struct Index {
private inputText: string = '';
@State outputText: string = '';
build() {
Column() {
TextInput({ placeholder: 'Please enter text' })
.height(40)
.fontSize(16)
.width('90%')
.margin(10)
.onChange((value: string) => {
this.inputText = value;
})
Scroll() {
Text(this.outputText)
.fontSize(16)
.width('90%')
.margin(10)
}
.height('40%')
Row() {
Button('Get Word Segmentation Result')
.type(ButtonType.Capsule)
.fontColor(Color.White)
.width('45%')
.margin(10)
.onClick(async () => {
try {
let result: textProcessing.WordSegment[] = await textProcessing.getWordSegment(this.inputText);
this.outputText = this.formatWordSegmentResult(result);
} catch (err) {
hilog.error(0x0000, 'testTag', `getWordSegment error: code: ${err.code}, message: ${err.message}`);
}
})
Button('Get Entity Results')
.type(ButtonType.Capsule)
.fontColor(Color.White)
.width('45%')
.margin(10)
.onClick(async () => {
try {
let result: textProcessing.Entity[] = await textProcessing.getEntity(this.inputText);
this.outputText = this.formatEntityResult(result);
} catch (err) {
hilog.error(0x0000, 'testTag', `getEntity error: code: ${err.code}, message: ${err.message}`);
}
})
}
}
.width('100%')
.height('100%')
.justifyContent(FlexAlign.Center)
}
页面结构一目了然:
上面是一个 TextInput 文本输入框,用户在这里输入要分析的文本。每次输入变化时,onChange 回调会把最新值存到 this.inputText。注意 inputText 没有 @State 装饰符——它只是内部变量,不需要驱动 UI 刷新。真正需要显示在界面上的是处理后的结果,那个才用 @State outputText。
中间是一个 Scroll 包裹的 Text 组件,用来显示处理结果。为什么要包一层 Scroll?因为结果可能很长(比如一句话拆出来十几个词),不滚动的话就看不到下面的内容了。
下面是一个 Row 里面放两个按钮,并排排列:
- 左边按钮 “Get Word Segmentation Result”:点击触发分词
- 右边按钮 “Get Entity Results”:点击触发实体抽取
两个按钮的 onClick 都是 async 的,因为分词和实体抽取都是异步操作(await)。这点很重要——自然语言处理涉及模型推理,不可能瞬间完成,所以 API 都是异步的。
有个小细节注意:两个按钮共用同一个 outputText 来显示结果。这意味着你点了分词再点实体抽取,分词结果就会被覆盖。在实际项目里,你可以用两个 @State 变量分别存两个结果,或者用 Tab 切换显示。
分词功能——把句子拆成词
分词是整个 Demo 里最核心的功能之一。来看具体实现:
.onClick(async () => {
try {
let result: textProcessing.WordSegment[] = await textProcessing.getWordSegment(this.inputText);
this.outputText = this.formatWordSegmentResult(result);
} catch (err) {
hilog.error(0x0000, 'testTag', `getWordSegment error: code: ${err.code}, message: ${err.message}`);
}
})
核心就一行代码:
textProcessing.getWordSegment(this.inputText)
传入一段文本字符串,返回一个 WordSegment[] 数组。就这么简单。
getWordSegment 内部做了什么呢?它会调用华为 NLP 引擎对文本进行分析,按照中文的语言规则把句子拆分成词,同时给每个词打上词性标签。整个过程在设备端完成,不需要联网,所以速度很快,隐私也更好。
返回的每个 WordSegment 对象包含:
word:词的文本,比如"北京"wordTag:词性标签,比如名词、动词、形容词等
格式化分词结果
private formatWordSegmentResult(segments: textProcessing.WordSegment[]): string {
let output = 'Word Segments:\n';
segments.forEach((segment, index) => {
output += `Word[${index}]: ${segment.word}, Tag: ${segment.wordTag}\n`;
});
return output;
}
这个方法把分词结果格式化成可读的文本。对于每个词,显示它的序号、文本和词性标签。
比如你输入"我明天要去北京出差",分词结果可能长这样:
Word Segments:
Word[0]: 我, Tag: pronoun
Word[1]: 明天, Tag: noun
Word[2]: 要, Tag: auxiliary
Word[3]: 去, Tag: verb
Word[4]: 北京, Tag: noun
Word[5]: 出差, Tag: verb
词性标签用的是英文(pronoun=代词, noun=名词, verb=动词 等),这是 NLP 领域的通用做法。如果你觉得英文字段对用户不够友好,可以在项目里做一个映射表,把英文标签翻译成中文显示。
实体抽取功能——找出句子里的"名字"
实体抽取是另一个核心功能,它能从文本中识别出"命名实体"——人名、地名、机构名等等。
.onClick(async () => {
try {
let result: textProcessing.Entity[] = await textProcessing.getEntity(this.inputText);
this.outputText = this.formatEntityResult(result);
} catch (err) {
hilog.error(0x0000, 'testTag', `getEntity error: code: ${err.code}, message: ${err.message}`);
}
})
同样是一行核心代码:
textProcessing.getEntity(this.inputText)
传入文本,返回 Entity[] 数组。每个 Entity 对象比 WordSegment 丰富不少:
格式化实体抽取结果
private formatEntityResult(entities: textProcessing.Entity[]): string {
if (!entities || !entities.length) {
return 'No entities found.';
}
let output = 'Entities:\n';
for (let i = 0; i < entities.length; i++) {
let entity = entities[i];
output += `Entity[${i}]:\n`;
output += ` oriText: ${entity.text}\n`;
output += ` charOffset: ${entity.charOffset}\n`;
output += ` entityType: ${entity.type}\n`;
output += ` jsonObject: ${entity.jsonObject}\n\n`;
}
return output;
}
注意这里和分词结果格式化的区别:
-
先做空值判断:
if (!entities || !entities.length)—— 如果文本里没有识别到任何实体,直接返回 “No entities found.”。这是一个好习惯,分词那边其实也应该加上类似判断,因为理论上空文本也可能返回空数组。 -
每个实体有四个字段:
oriText:实体在原文中的原始文本,比如"张三"、“北京”charOffset:实体在原文中的字符偏移位置。这个很有用——如果你想在原文中高亮显示实体,就需要知道它从第几个字符开始。entityType:实体类型,比如人名(person)、地名(location)、机构名(organization)等jsonObject:额外的 JSON 格式详细信息。这个字段的内容取决于实体类型,比如一个人名实体可能包含更多信息
-
用了
for循环而不是forEach:虽然两种写法效果一样,但这里可能是原作者的个人习惯。在大多数场景下,forEach更简洁。
举个实际例子,如果你输入"马云在杭州创立了阿里巴巴":
Entities:
Entity[0]:
oriText: 马云
charOffset: 0
entityType: person
jsonObject: {"name": "马云"}
Entity[1]:
oriText: 杭州
charOffset: 3
entityType: location
jsonObject: {"name": "杭州"}
Entity[2]:
oriText: 阿里巴巴
charOffset: 7
entityType: organization
jsonObject: {"name": "阿里巴巴"}
有了 charOffset,你就可以精确地在原文中定位和标注这些实体,这对做搜索高亮、智能标注之类的功能非常关键。
两个功能的对比
| 维度 | 分词(getWordSegment) | 实体抽取(getEntity) |
|---|---|---|
| 输入 | 任意文本 | 任意文本 |
| 输出 | 词的数组 | 命名实体的数组 |
| 粒度 | 每个词都拆出来 | 只关注"有名字"的词 |
| 返回信息 | 词 + 词性 | 原文 + 偏移位置 + 类型 + 详情 |
| 典型用途 | 搜索分词、关键词提取 | 信息抽取、智能标注 |
分词是"细粒度"的——一句话里每个词都会拆出来。实体抽取是"粗粒度"的——只关注那些有特殊含义的词。
实际项目中这两个功能经常配合使用。比如你做一个搜索引擎,先用分词把用户输入拆成词,再用实体抽取识别出其中的地名、人名,这样就能更精确地理解用户的搜索意图。
和前面几个 Kit 的对比
写到这儿,我们已经聊了四个 Kit 了:SpeechKit(场景化语音)、CoreSpeechKit(基础语音)、CoreVisionKit(基础视觉)、VisionKit(场景化视觉),现在又加了一个 NaturalLanguageKit。做一个简单对比:
| Kit | 能力 | 需要初始化/释放? | 需要网络? |
|---|---|---|---|
| CoreVisionKit | OCR、人脸检测等 | 部分需要 init/release | 取决于模型 |
| VisionKit | 活体检测、卡证识别等 | 不需要(直接调用) | 取决于模式 |
| CoreSpeechKit | TTS、ASR | 需要 createEngine/shutdown | online 模式需要 |
| NaturalLanguageKit | 分词、实体抽取 | 不需要 | 不需要(离线) |
NaturalLanguageKit 是这几个 Kit 里最"省心"的——不需要初始化引擎,不需要释放资源,不需要网络。直接调接口,传文本,拿结果,完事。就像一个即插即用的计算器,按下按钮就能出结果。
这种简洁的 API 设计对开发者来说非常友好。你不用操心什么时候初始化、什么时候释放、会不会内存泄漏这些问题,专注于业务逻辑就好。
当然,简单也意味着灵活度相对较低。如果你需要更高级的 NLP 能力(比如自定义分词词典、训练专属的实体识别模型),那就得用更底层的 API 或者接入云端服务了。

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐

 68
68 0
0- 0



 已为社区贡献289条内容
已为社区贡献289条内容

所有评论(0)