Spark-事件及度量
事件总线
基本概念
Spark 定义了一个特质(trait) ListenerBus,可以接收事件并且将事件提交到对应事件的监听器
ListernerBus 是个带有泛型参数[L <: AnyRef,E] 的特质,其中 L 是代表监听器的泛型参数,ListernerBus 支持任何类型的监听器,E 是代表事件的泛型参数,在 ListernerBus 中的变量和方法的作用如下:
- listeners: 用于维护所有注册的监听器,其数据结构为 CopyOnWriteArrayList[L]
- addListener : 向 listeners 中添加监听器的方法,由于 listeners 采用 CopyOnWriteArrayList 来实现,所以 addListener 方法是线程安全的
- removeListener : 从 listeners 中移除监听器的方法,由于 listeners 采用 CopyOnWriteArrayList 来实现,所以 removeListener 方法是线程安全的
- postToAll : 此方法的作用是将事件投递给所有的监听器。虽然 CopyOnWriteArrayList 本身是线程安全的,但是由于 postToAII 方法内部引入了“先检查后执行” 的逻辑,因而 postToAlI 方法不是线程安全的,所以所有对 postToAII 方法的调用应当保证在同一个线程中
- doPostEvent : 用于将事件投递给指定的监听器,此方法只提供了接口定义,具体实现需要子类提供
- findListenersByClass : 查找与指定类型相同的监听器列表
ListenerBus的继承体系
ListenerBus 有三种具体的实现
- SparkListenerBus : 用于将 SparkListenerEvent 类型的事件投递到 SparkListenerInterface 类型的监听器,在其下也有两种实现
- LiveListenerBus : 采用异步线程将 SparkListenerEvent 类型的事件投递到 SparkListener 类型的监听器
- ReplayListenerBus : 用于从序列化的事件数据中重播事件
- StreamingQueryListenerBus : 用于将 StreamingQueryListener.Event 类型的事件投递到 StreamingQueryListener 类型的监听器,此外还会将 StreamingQueryListener. Event 类型的事件交给 SparkListenerBus
- StreamingListenerBus : 用于将 StreamingListenerEvent 类型的事件投递到 StrcamingListener 类型的监听器,此外还会将StreamingListenerEvent 类型的事件交给SparkListenerBus
SparkListenerBus
SparkListenerBus 的实现如下:
private[spark] trait SparkListenerBus
extends ListenerBus[SparkListenerInterface, SparkListenerEvent] {
/** 实现了 ListenerBus 的 doPostEvent 方法,通过对 SparkListenerEvent 事件的匹配,执行 SparkListenerInterface 监听器的相应方法*/
protected override def doPostEvent(
listener: SparkListenerInterface,
// 这里的 SparkListenerEvent 也是特质,下面的 SparkListenerStageSubmitted、SparkListenerStageCompleted等都是继承了 SparkListenerEvent 特质的样例类
event: SparkListenerEvent): Unit = {
event match {
case stageSubmitted: SparkListenerStageSubmitted =>
listener.onStageSubmitted(stageSubmitted)
case stageCompleted: SparkListenerStageCompleted =>
listener.onStageCompleted(stageCompleted)
case jobStart: SparkListenerJobStart =>
listener.onJobStart(jobStart)
case jobEnd: SparkListenerJobEnd =>
listener.onJobEnd(jobEnd)
case taskStart: SparkListenerTaskStart =>
listener.onTaskStart(taskStart)
case taskGettingResult: SparkListenerTaskGettingResult =>
listener.onTaskGettingResult(taskGettingResult)
case taskEnd: SparkListenerTaskEnd =>
listener.onTaskEnd(taskEnd)
case environmentUpdate: SparkListenerEnvironmentUpdate =>
listener.onEnvironmentUpdate(environmentUpdate)
case blockManagerAdded: SparkListenerBlockManagerAdded =>
listener.onBlockManagerAdded(blockManagerAdded)
case blockManagerRemoved: SparkListenerBlockManagerRemoved =>
listener.onBlockManagerRemoved(blockManagerRemoved)
case unpersistRDD: SparkListenerUnpersistRDD =>
listener.onUnpersistRDD(unpersistRDD)
case applicationStart: SparkListenerApplicationStart =>
listener.onApplicationStart(applicationStart)
case applicationEnd: SparkListenerApplicationEnd =>
listener.onApplicationEnd(applicationEnd)
case metricsUpdate: SparkListenerExecutorMetricsUpdate =>
listener.onExecutorMetricsUpdate(metricsUpdate)
case executorAdded: SparkListenerExecutorAdded =>
listener.onExecutorAdded(executorAdded)
case executorRemoved: SparkListenerExecutorRemoved =>
listener.onExecutorRemoved(executorRemoved)
case executorBlacklistedForStage: SparkListenerExecutorBlacklistedForStage =>
listener.onExecutorBlacklistedForStage(executorBlacklistedForStage)
case nodeBlacklistedForStage: SparkListenerNodeBlacklistedForStage =>
listener.onNodeBlacklistedForStage(nodeBlacklistedForStage)
case executorBlacklisted: SparkListenerExecutorBlacklisted =>
listener.onExecutorBlacklisted(executorBlacklisted)
case executorUnblacklisted: SparkListenerExecutorUnblacklisted =>
listener.onExecutorUnblacklisted(executorUnblacklisted)
case nodeBlacklisted: SparkListenerNodeBlacklisted =>
listener.onNodeBlacklisted(nodeBlacklisted)
case nodeUnblacklisted: SparkListenerNodeUnblacklisted =>
listener.onNodeUnblacklisted(nodeUnblacklisted)
case blockUpdated: SparkListenerBlockUpdated =>
listener.onBlockUpdated(blockUpdated)
case speculativeTaskSubmitted: SparkListenerSpeculativeTaskSubmitted =>
listener.onSpeculativeTaskSubmitted(speculativeTaskSubmitted)
case _ => listener.onOtherEvent(event)
}
}
}
以上代码片段中的 onStageCompleted 和 onStageSubmitted 方法将在 SparkListenerBus 的 doPostEvent 方法中分别匹配到SparkListenerStageCompleted 和 SparkListenerStageSubmitted 事件时执行,而对于 doPostEvent 中无法匹配的事件,都将执行onOtherEvent 方法
当有事件需要通知监听器的时候,可以调用 ListenerBus 的 postToAII 方法,postToAlI 方法遍历所有监听器并调用 SparkListenerBus 实现的 doPostEvent 方法,doPostEvent 方法对事件类型进行匹配后调用监听器的不同方法。整个投递事件的过程是通过方法调用实现的,所以这是一个同步调用。在监听器比较多的时候,这个过程会相对比较耗时,在 SparkUI 中为了达到页面的即时刷新,实现了SparkListenerBus 的子类 LiveListenerBus
度量系统
基本概念
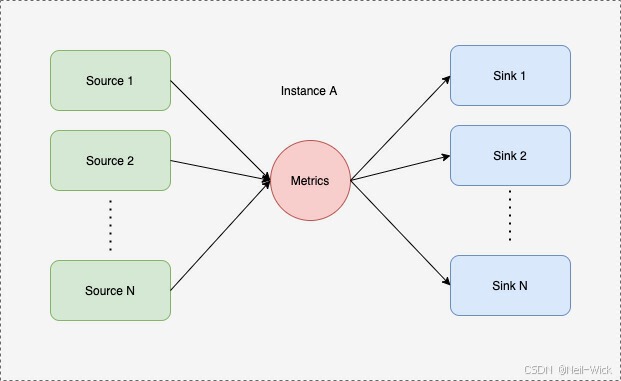
Spark的度量系统使用 codahale 提供的第三方度量仓库,Spark的度量系统有三个概念:
- Instance : 指定了度量系统的实例名。Spark 按照 Instance 的不同,区分为 Master、Worker、Application、 Driver 和 Executor
- Source : 指定了从哪里收集度量数据,即度量数据的来源。Spark 提供了应用的度量来源(ApplicationSource)、Worker 的度量来源(WorkerSource)、DAGScheduler 的度量来源(DAGSchedulerSource)、BlockManager 的度量来源(BlockManagerSource)等诸多实现,对各个服务或组件进行监控
- Sink:指定了往哪里输出度量数据,即度量数据的输出。Spark中使用Metrics-Servlet作为默认的Sink,此外还提供了ConsoleSink、CsvSink、JmxSink、MetricsServlet、GraphiteSink等实现
Source 继承体系
Spark 将度量来源抽象为 Source,Source 是一个特质,其中定义了两个方法
- sourceName : 度量源的名称
- metricRegistry : 当前度量源的注册表
Spark 中有很多 Source 的具体实现,以下以ApplicationSource作为例子
ApplicationSource
// 用于采集 Spark 应用程序相关的度量
private[master] class ApplicationSource(val application: ApplicationInfo) extends Source {
// 重载了 Source 的 metricRegistry
override val metricRegistry = new MetricRegistry()
// 重载了 Source 的sourceName
override val sourceName = "%s.%s.%s".format("application", application.desc.name,
System.currentTimeMillis())
/** 以下分别向自身的注册表注册了 state、runtime_ms、cores 等,分别多来自于 ApplicationInfo 的属性*/
metricRegistry.register(MetricRegistry.name("status"), new Gauge[String] {
override def getValue: String = application.state.toString
})
metricRegistry.register(MetricRegistry.name("runtime_ms"), new Gauge[Long] {
override def getValue: Long = application.duration
})
metricRegistry.register(MetricRegistry.name("cores"), new Gauge[Int] {
override def getValue: Int = application.coresGranted
})
}
Sink 继承体系
Spark 将度量输出抽象为 Sink,Sink 是一个特质,其中定义了两个方法
- start : 启动 Sink
- stop : 停止 Sink
- report : 输出到目的地
Spark 的 Sink 有6 种实现,分别为:
- ConsoleSink : 借助Metrics提供的 ConsoleReporter 的API,将度量输出到 System.out ,因此可以输出到控制台
- CsvSink : 借助 Metrics 提供的 CsvReporter 的API,将度量输出到CSV文件
- MetricsServlet : 在 Spark UI 的 jetty 服务中创建 ServletContextHandler,将度量数据通过 Spark UI 展示在浏览器中
- JmxSink : 借助 Metrics 提供的 JmxReporter 的API,将度量输出到 MBean 中,这样就可以打开 Java VisualVM,然后打开 Tomcat 进程监控,给 VisuaIVM 安装 MBeans 插件后,选择 MBeans 标签页可以对 JmxSink 所有注册到 JMX 中的对象进行管理
- Slf4jSink : 借助 Metrics 提供的 SIf4jReporter 的API,将度量输出到实现了SIf4j 规范的日志输出
- GraphiteSink : 借助 Metrics 提供的 GraphiteReporter 的API,将度量輸出到 Graphite (一个由 Python 实现的 Web 应用,采用 django框架,用來收集服务器状态的监控系统)
Slf4jSink
private[spark] class Slf4jSink(
val property: Properties,
val registry: MetricRegistry,
securityMgr: SecurityManager)
extends Sink {
val SLF4J_DEFAULT_PERIOD = 10
val SLF4J_DEFAULT_UNIT = "SECONDS"
val SLF4J_KEY_PERIOD = "period"
val SLF4J_KEY_UNIT = "unit"
val pollPeriod = Option(property.getProperty(SLF4J_KEY_PERIOD)) match {
case Some(s) => s.toInt
case None => SLF4J_DEFAULT_PERIOD
}
val pollUnit: TimeUnit = Option(property.getProperty(SLF4J_KEY_UNIT)) match {
case Some(s) => TimeUnit.valueOf(s.toUpperCase(Locale.ROOT))
case None => TimeUnit.valueOf(SLF4J_DEFAULT_UNIT)
}
MetricsSystem.checkMinimalPollingPeriod(pollUnit, pollPeriod)
val reporter: Slf4jReporter = Slf4jReporter.forRegistry(registry)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.convertRatesTo(TimeUnit.SECONDS)
.build()
/** 这里的三个方法都是代理了 Metrics 库中 Slf4jReporter 的方法,Slf4jReporter 的 start 方法实际是其父类 ScheduledReporter 的 start 实现。而传递的两个参数 pollPeriod 和 pollUnit,正是被 ScheduledReporter 使用作为定时器获取数据的周期和时间单位*/
override def start() {
reporter.start(pollPeriod, pollUnit)
}
override def stop() {
reporter.stop()
}
override def report() {
reporter.report()
}
}

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)