仓颉的多线程
·
1.创建
spawn关键字
spawn {
//子线程代码
println("这是子线程: 1")
}// 执行
let fut = spawn {
println("这是子线程: 2")
}// 没访问不执行
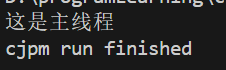
print("这是主线程")图一:子线程还没执行,主线程就执行完成,子线程生命周期随之结束。
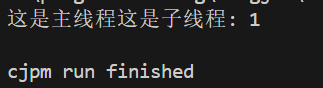
图二:大抵恰巧赶上了。总之子线程与主线程运行顺序不确定(虽然后续运行全是图一的情况)。
2.访问
目的就是等待其执行完成,避免图一
spawn表达式的返回类型是Future<T>
Future的方法:get()、tryGet()
let future:Future<Unit> = spawn {
for (i in 0..3) {
print("子线程i的值为:${i}\n")
}
sleep(Duration.second * 2)
}
for (j in 0..6) {
print("主线程j的值为:${j}\n")
}
future.get()调用get()时,程序阻塞主线程,等待该线程执行完成,同时获取其返回的值。
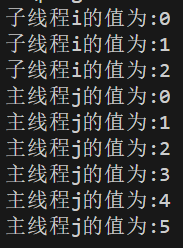
图三、图四:会等待子线程执行完成,但子、主线程运行顺序不定。
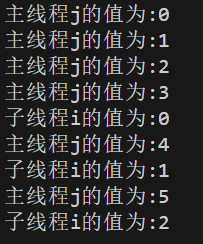
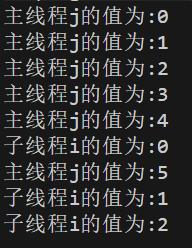
图五:先执行Future.get(),就会先等子线程执行完成,再执行主线程了。
let future:Future<Unit> = spawn {
for (i in 0..3) {
print("子线程i的值为:${i}\n")
}
sleep(Duration.second * 2)
}
future.get()
for (j in 0..6) {
print("主线程j的值为:${j}\n")
}
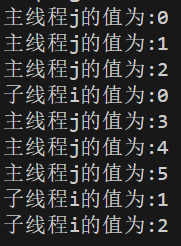
图六:调用tryGet()时,不会阻塞主线程。
let future:Future<Unit> = spawn {
for (i in 0..3) {
print("子线程i的值为:${i}\n")
}
sleep(Duration.second * 2)
}
future.tryGet()
for (j in 0..6) {
print("主线程j的值为:${j}\n")
}
3.终止
Future有个Thread成员,用于访问线程的属性,其中Thread.currentThread.hasPendingCancellation监测终止子线程执行的信号
let future = spawn {
for(i in 1..=3){
if(Thread.currentThread.hasPendingCancellation){
println("子线程被终止")
break
}
sleep(Duration.second*2)
println("子线程i的值为:${i}")
}
}
sleep(Duration.second*2)
future.cancel() // 发送终止子线程执行的信号
future.get()
4.原子操作
Atomic类型,执行过程中不会被其他线程打断,避免数据竞争
let count1 = AtomicInt64(0)
// var count = 0
public func exec2()
{
var lists:ArrayList<Future<Int64>> = ArrayList<Future<Int64>>()
for(i in 0..2000){
let future =spawn {
count1.fetchAdd(1)
// count++
}
lists.append(future)
}
for(item in lists){
item.get()
}
println("2000个线程的点击的次数为:${count1.load()}") // 2000
// println("2000个线程的点击的次数为:${count}") // count <= 2000
}

图八:未使用原子操作的情况,可能会出现线程对count的竞争,导致不同i的线程对相同的count进行自增,从而实际不足2000

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)