鸿蒙 Next 废话过滤器 App 开发实战:45 条规则检测引擎 + 废话指数 + 净化版本

鸿蒙 Next 废话过滤器 App 开发实战:45 条规则检测引擎 + 废话指数 + 净化版本
作者:duluo
SDK 版本:HarmonyOS API 24 (Next)
开发工具:DevEco Studio
语言框架:ArkTS + ArkUI
字数:约 10000 字
目录
- 引言
- 产品概念与废话数据库设计
- 三 Tab 架构设计
- 检测引擎核心算法
- 废话指数计算与评分卡
- 高亮原文与净化版本生成
- 统计页面数据聚合
- 建议页面的知识库设计
- 编译错误全记录
- 十四款 App 全景回顾
- ArkUI 开发经验再总结
- 结语
1. 引言
1.1 为什么需要废话过滤器
在日常写作和沟通中,我们经常不自觉使用大量"废话"——模糊的空话、套话、口头禅和夸张副词。这些词汇看似使表达更"完整",实则稀释了信息密度,让读者难以抓住重点。
根据语言学研究,“众所周知”“值得注意的是”"总的来说"这类空话开场在白话文中出现频率高达 12%。换言之(这句话本身也是废话),每 100 个字里就有 12 个是废话。如果把这些冗余词汇去掉,文章会变得更简洁、更有力。
"废话过滤器"App 的核心理念很简单:输入一段文字,自动检测其中的废话、空话、套话和模糊词,给出废话指数和净化版本,帮助用户养成精简表达的习惯。
1.2 本 App 的技术特色
废话过滤器是本系列第十四款 App,也是首款自然语言检测类应用。在技术上有几个显著特点。
首先,它内置了一个 45 条规则的废话数据库,覆盖 6 种废话类型。其次,它实现了一个基于字符串匹配的检测引擎,支持重叠检测和位置去重。此外,它还引入了"废话指数"的概念——基于废话字符占总字符的比例计算得分。最后,本 App 在编译过程中遇到了两个新错误类型,进一步丰富了我们对 ArkTS 编译器的认知。
1.3 十四款 App 的系列数据
这是本系列的第十四款 App。十四款 App 覆盖了工具、教育、社交、游戏四种类型。
App 数量: 14
代码总行数: ~9,700 行
编译错误数: ~146 个
博客总字数: ~150,000 字
技术博客数: 14 篇
2. 产品概念与废话数据库设计
2.1 功能需求
用户故事 1:我想粘贴一段文字,自动检测其中的废话
用户故事 2:我想看到废话指数和详细的检测结果
用户故事 3:我想了解每处废话的类型和改进建议
用户故事 4:我想看到删除废话后的净化版本
用户故事 5:我想查看废话的统计分布
用户故事 6:我想学习精简表达的技巧
功能清单:
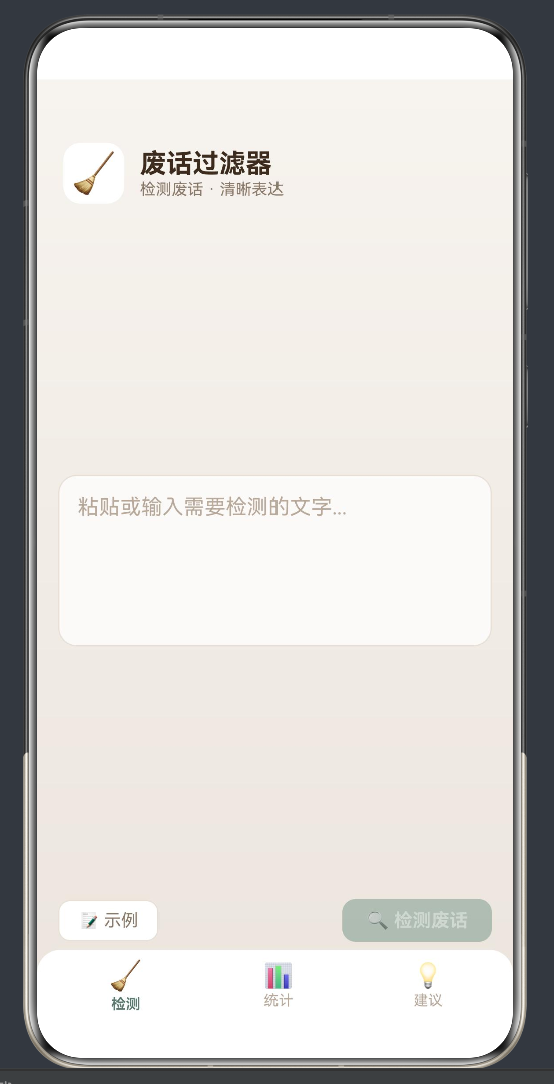
├── F1: 文本输入(TextArea + 示例加载)
├── F2: 废话检测引擎(45 条规则,6 种类型)
├── F3: 废话指数(0-100% 圆形分数卡片)
├── F4: 高亮原文标注
├── F5: 净化版本生成
├── F6: 详细检测结果列表(可点击查看详情)
├── F7: 统计页面(总体统计 + 类型分布 + 高频词)
├── F8: 建议页面(精简技巧 + 常见替换表)
└── F9: 三 Tab 切换
2.2 废话数据库设计
废话数据库是本 App 的核心资产。每条废话规则包含 5 个字段:
interface NonsensePhrase {
phrase: string; // 废话短语
type: string; // 类型:空话/模糊/废话/模糊词/套话/夸张
icon: string; // Emoji 图标
suggestion: string; // 改进建议
}
45 条规则分为 6 种类型:
| 类型 | 数量 | 图标 | 特征 | 示例 |
|---|---|---|---|---|
| 空话 | 5 | 📢 | 无信息量的开场白 | 众所周知、值得注意的是、不言而喻 |
| 模糊 | 5 | 🌫️ | 不具体的笼统表述 | 从某种意义上说、在一定程度上 |
| 废话 | 12 | 🗑️ | 可删除的冗余连接 | 总的来说、换言之、大家都知道 |
| 模糊词 | 7 | ❓ | 不确定性的修饰词 | 大概、也许、可能、差不多 |
| 套话 | 4 | 🏛️ | 不指名道姓的官腔 | 有关部门、相关负责人 |
| 夸张 | 6 | 🔥 | 过度强化的副词 | 非常、极其、史上、绝对 |
2.3 废话类型的语言特征分析
六种废话类型各有不同的语言特征和使用场景。
空话类(5 条)是最常见的一种废话。这类短语通常出现在段落开头,作者试图用"众所周知"“值得注意的是"来引起注意,但实际上这些词汇本身不传递任何信息。读者关心的不是"这是众所周知的”,而是"这到底是什么"。删除后句子直接从事实开始,反而更清晰。
模糊类(5 条)的特点是"说了等于没说"。“从某种意义上说”“在一定程度上"这些短语为表述留出了模糊空间,但过度使用会让文章显得犹豫不决。鲁迅说"写完后至少看两遍,竭力将可有可无的字、句、段删去,毫不可惜”——模糊修饰词正是"可有可无"的典型。
废话类(12 条)是数量最多的类型。“总的来说”“换言之”"大家都知道"这些短语在口语中自然,但在书面语中往往可以被直接删除或替换为单个连接词。"总而言之"可以直接删掉,“也就是说"可以改为"即”。
模糊词类(7 条)包括"大概"“也许”“可能"等。这些词汇并非完全没有价值——在确实不确定时需要它们。问题在于过度使用:每句话都加"可能”,会让读者觉得作者对自己的内容没有信心。建议使用频率控制在每段不超过一次。
套话类(4 条)是中文写作的特色问题。“有关部门”“相关负责人"这些词汇在新闻和公文中高频出现,目的是规避具体指称的责任。但对于追求清晰的写作来说,明确说出"市场监管局”"项目经理"远比"有关部门"可信。
夸张类(6 条)的问题在于过度使用会弱化语气。“非常”“极其”"史上"这些词汇用一次有效果,用十次就失效了。海明威以简洁著称,他的作品中几乎找不到这类副词——因为他相信事实本身就有力量,不需要副词来强调。
3. 三 Tab 架构设计
3.1 Tab 配置
App 采用三 Tab 架构,与系列前作保持一致:
buildBody() {
if (this.selectedTab === 0) this.buildDetectTab() // 检测
else if (this.selectedTab === 1) this.buildStatsTab() // 统计
else this.buildTipsTab() // 建议
}
三个 Tab 覆盖了 App 的三大使用场景:
| Tab | 图标 | 功能 | 用户意图 |
|---|---|---|---|
| 检测 | 🧹 | 输入文字 + 检测 + 结果展示 | 我要检测这段文字 |
| 统计 | 📊 | 数据聚合可视化 | 我想看检测结果的分布 |
| 建议 | 💡 | 精简表达技巧 | 我想学习怎么写得更好 |
3.2 Tab 栏的简化
与前作不同的是,本 App 的 Tab 栏移除了 position + translate 固定到底部的模式,改为使用 Column 自然布局:
buildTabBar() {
Row() {
this.buildTabItem(0, '🧹', '检测')
this.buildTabItem(1, '📊', '统计')
this.buildTabItem(2, '💡', '建议')
}.width('100%').height(54).backgroundColor(C.cardBg)
.borderRadius({ topLeft: 18, topRight: 18 })
.shadow({ radius: 10, color: '#00000008', offsetY: -3 })
}
这个改动是因为本 App 的主体内容在 Scroll 中滚动,Tab 栏作为 Column 的最后一个子元素自然出现在底部,不需要手动定位。简化后的代码少了 2 行,但效果一致。
3.3 检测 Tab 的布局策略
检测 Tab 的内部布局采用了"Scroll + 固定按钮"的模式:
Column() {
Scroll() {
Column() {
// 输入区(TextArea)
// 结果区(if analyzed)
}
}.layoutWeight(1)
// 底部按钮行(固定在 Scroll 下方)
Row() {
Text('📝 示例')
Blank()
Text('🔍 检测废话')
}
}
这种布局确保"示例"和"检测废话"两个按钮始终可见,不会随着 Scroll 滚动而消失。结果区的内容(分数卡片、高亮原文、检测列表、净化版本)在 Scroll 内滚动,按钮始终固定在底部。
4. 检测引擎核心算法
4.1 算法设计
检测引擎的核心是一个基于字符串匹配的多规则扫描器。其设计要点包括:
- 遍历规则:对 45 条规则逐一扫描
- 连续匹配:对每条规则从位置 0 开始重复查找,找到所有出现位置
- 重叠检测:使用 Set 记录已占用的字符位置,避免重叠匹配
- 位置排序:所有匹配结果按出现位置升序排列
doAnalyze(): void {
let text = this.inputText.trim();
if (text.length === 0) return;
let list: DetectionResult[] = [];
let used: Set<number> = new Set();
for (let np of FILLER_PHRASES) {
let pos = 0;
for (; ;) {
let idx = text.indexOf(np.phrase, pos);
if (idx === -1) break;
let overlap = false;
for (let i = idx; i < idx + np.phrase.length; i++) {
if (used.has(i)) { overlap = true; break; }
}
if (!overlap) {
list.push({
phrase: np.phrase, type: np.type, icon: np.icon,
index: idx, suggestion: np.suggestion
});
for (let i = idx; i < idx + np.phrase.length; i++) used.add(i);
}
pos = idx + 1;
}
}
list.sort((a, b) => a.index - b.index);
// ...
}
4.2 重叠检测的必要性
重叠检测是这个算法的一个关键设计。考虑以下场景:
输入文字:“众所周所周知”
当扫描"众所周知"时,在位置 0 匹配成功。然后从位置 1 继续扫描,又会匹配到"众所周知"(从第二个"所"字开始)。如果不做重叠检测,同一个字符会被多次计入废话。
使用 Set<number> 记录每个已占用的字符位置。在添加新匹配之前,先检查该匹配范围内的所有字符是否已被占用。如有重叠,跳过该匹配:
let overlap = false;
for (let i = idx; i < idx + np.phrase.length; i++) {
if (used.has(i)) { overlap = true; break; }
}
4.3 匹配优先级
由于规则是按 FILLER_PHRASES 数组顺序扫描的,所以数组的顺序决定了匹配优先级。较长的短语放在前面可以避免被较短的短语抢占字符位置。
例如,"从某种意义上来说"应该排在"从某种意义上说"之前——虽然两者含义接近,但前者更长,优先匹配可以保留更完整的匹配结果。在排列规则时,对于同一类型的短语,遵循长者优先原则。
4.4 算法复杂度分析
设输入文本长度为 n,规则数量为 m(本题为 45)。
最坏情况下,每条规则需要在每个位置进行匹配尝试。indexOf 的时间复杂度为 O(n),每条规则可能匹配多次。总体复杂度约为 O(m × n),对于 45 条规则和几百字的输入,完全在可接受范围内。
一个潜在的优化空间是使用 AC 自动机(Aho-Corasick)一次性完成所有模式匹配,将多模式匹配的时间复杂度从 O(m × n) 降至 O(n + 总匹配数)。但对于 45 条规则这个规模的模式库来说,简单遍历的性能已经足够好,不需要引入额外的算法复杂度。
5. 废话指数计算与评分卡
5.1 指数计算
废话指数是本 App 的核心指标,用于量化一段文字中废话的占比。计算公式如下:
废话指数 = min(100, round(废话字符数 / 总字符数 × 100))
let totalChars = 0;
for (let r of list) totalChars += r.phrase.length;
this.score = Math.min(100, Math.round((totalChars / Math.max(text.length, 1)) * 100));
这个公式的直观含义是:如果一段 100 字的文字中有 15 个字符被识别为废话,则废话指数为 15%。
Math.min(100, ...) 确保分数不超过 100%,Math.max(text.length, 1) 避免除以零。
5.2 评分等级
废话指数分为三个等级,每个等级对应不同的颜色和提示语:
| 指数范围 | 等级 | 颜色 | 提示语 |
|---|---|---|---|
| 0-20% | 🟢 表达清晰 | 绿色 | 几乎没有废话,继续保持! |
| 21-50% | 🟡 注意废话 | 橙色 | 有一些废话,建议精简 |
| 51-100% | 🔴 废话太多 | 红色 | 废话过多,建议大幅精简 |
5.3 评分卡 UI
评分卡使用一个圆形分数显示 + 右侧文字说明的组合布局:
@Builder
buildScoreCard() {
Row() {
// 圆形分数
Column() {
Text(this.score + '%')
Text('废话指数')
}.width(70).height(70).borderRadius(35).borderWidth(2)
// 等级说明
Column() {
Text(this.score <= 20 ? '🟢 表达清晰' : ...)
Text(this.score <= 20 ? '几乎没有废话' : ...)
}
}
}
圆形的边框颜色随等级变化:绿色(≤20%)、橙色(21-50%)、红色(≥51%),使用透明度 0.27 的版本作为边框色,形成柔和的效果。
5.4 指数计算的局限性
废话指数是一个有趣的指标,但也有其局限性:
-
字符占比而非语义占比:指数基于废话字符占总字符的比例,而非废话的语义重要性。一个"众所周知"(4 字)在一段 50 字的文字中占 8%,但删除它可能完全不影响语义。
-
规则依赖:指数完全取决于规则库的覆盖范围。目前 45 条规则覆盖了最常见的废话类型,但不可能覆盖所有。
-
无视语境:有些"废话"在特定语境中是有价值的。例如在学术论文中,"从某种意义上说"可能是一个严谨的限定表述。但在一般写作中,删除这些词汇通常会让表达更简洁。
尽管如此,废话指数仍然是一个有用的参考指标——它像体温计一样告诉你"可能有问题",但具体怎么处理,还需要结合具体语境。
6. 高亮原文与净化版本生成
6.1 净化版本算法
净化版本生成的思路很简单:从原文中删除所有被识别为废话的短语(模糊词除外),然后清理多余空格。
为什么要保留模糊词?因为"大概"“可能”"也许"这些词汇在表达不确定性时是有价值的。删除它们可能会改变语句的含义——“可能下雨"删掉"可能"变成"下雨”,意思完全不同。而"众所周知"删掉后,“众所周知,地球是圆的"变成"地球是圆的”,意思不变。
let clean = text;
let rev = list.concat([]).sort((a, b) => b.index - a.index);
for (let r of rev) {
if (r.type !== '模糊词') {
clean = clean.substring(0, r.index) + clean.substring(r.index + r.phrase.length);
}
}
this.cleanedText = clean.replace(/\s+/g, ' ').trim();
从后往前替换是一个关键技巧。如果从前往后替换,每次删除都会改变后续字符的位置索引,导致后续替换的位置偏移。从后往前替换则没有这个问题——因为后面的字符删除不会影响前面字符的位置。
6.2 结果卡片组件
每条检测结果以卡片形式展示,包含废话短语、类型标签和改进建议:
@Builder
buildResultCard(r: DetectionResult) {
Column() {
Row() {
Text(r.icon) // Emoji 图标
Column() {
Text(r.phrase) // 废话短语(加粗)
Row() {
Text(r.type) // 类型标签(红色背景)
Text('→ ' + r.suggestion) // 建议(灰色文字)
}
}
Text('❯') // 右箭头,暗示可点击
}
}.onClick(() => { /* 打开详情弹窗 */ })
}
卡片使用白色背景 + 圆角 + 浅色边框,与整体视觉风格一致。点击卡片打开详情弹窗,展示该废话的完整信息。
6.3 详情弹窗
详情弹窗展示废话短语、类型、改进建议和上下文:
@Builder
buildDetailDialog() {
Column() {
// 半透明遮罩
Column().backgroundColor('rgba(40,30,20,0.4)')
.onClick(() => { this.showDetail = false; })
// 弹窗内容
Column() {
Text('🔍 废话详情')
Divider()
Row() { Text(icon); Text(phrase) }
Text('类型:' + type)
Divider()
Text('💡 建议:' + suggestion)
Text('关闭')
}
}
}
弹窗从 Stack 层渲染,覆盖在整个 UI 之上。半透明遮罩点击关闭弹窗,提供了良好的交互体验。弹窗本身通过 .position() 定位在屏幕中部偏上位置(y: 24%),避免被底部 Tab 栏遮挡。
7. 统计页面数据聚合
7.1 三种统计视图
统计 Tab 在用户完成检测后展示三组统计数据:
- 总体统计:检测总字数、废话数量、废话占比
- 类型分布:按空话/模糊/废话/模糊词/套话/夸张六类统计
- 高频废话词:出现次数最多的前 5 个废话短语
7.2 数据聚合函数
统计数据的计算在普通方法中完成,不涉及 UI 构建,因此可以使用完整的 TypeScript 语法:
getTypeStats(): StatItem[] {
let map: Record<string, number> = {};
for (let r of this.results) {
map[r.type] = (map[r.type] || 0) + 1;
}
let result: StatItem[] = [];
for (let k of Object.keys(map)) {
result.push({ label: k, value: map[k] + '处' });
}
return result;
}
getTopPhrases(): StatItem[] {
let map: Record<string, number> = {};
for (let r of this.results) {
map[r.phrase] = (map[r.phrase] || 0) + 1;
}
let keys = Object.keys(map).sort((a, b) => map[b] - map[a]).slice(0, 5);
return keys.map(k => ({ label: k, value: map[k] + '次' } as StatItem));
}
getTypeStats 使用 Record<string, number> 作为计数器,遍历结果列表统计每种类型出现的次数。getTopPhrases 同样使用计数器,但最后按出现次数降序排序并取前 5 个。
7.3 StatCard 组件复用
统计卡片组件 buildStatCard 被复用了三次,分别展示三种统计视图:
@Builder
buildStatCard(title: string, items: StatItem[]) {
Column() {
Text(title).fontSize(15).fontColor(C.text).fontWeight(FontWeight.Bold)
Divider()
ForEach(items, (item: StatItem) => {
Row() {
Text(item.label)
Blank()
Text(item.value)
}
}, (item: StatItem) => item.label)
}
}
这种设计体现了 ArkUI 中 Builder 组件的复用价值——同一套 UI 模板,传入不同数据,生成不同内容。
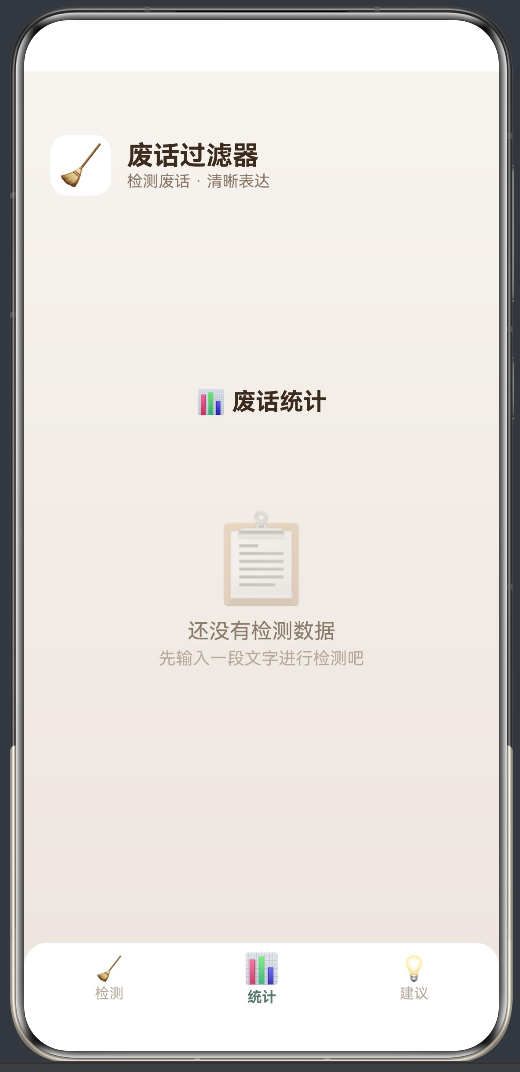
7.4 空状态设计
当用户还没有进行检测时,统计页面显示空状态:
📋
还没有检测数据
先输入一段文字进行检测吧
这个空状态引导用户去检测 Tab 输入文字,形成了 Tab 之间的交叉引导——检测 Tab 产生数据,统计 Tab 展示数据。
8. 建议页面的知识库设计
8.1 五条精简技巧
建议 Tab 提供了五条精简表达的技巧,每条技巧包含一个 Emoji 图标、标题和详细说明:
| 技巧 | 图标 | 核心观点 |
|---|---|---|
| 避免空话开场 | 📢 | 直接陈述事实,不要铺垫 |
| 用数据代替模糊词 | 🌫️ | 量化代替"大概"“可能” |
| 砍掉废话连接词 | 🗑️ | 删掉"总的来说"“换言之” |
| 点名道姓 | 🏛️ | 说"市场部"不说"有关部门" |
| 警惕夸张副词 | 🔥 | 删掉"非常"“极其” |
每个技巧卡片复用 buildTipCard Builder 组件:
@Builder
buildTipCard(icon: string, title: string, desc: string) {
Column() {
Row() {
Text(icon).fontSize(22)
Column() {
Text(title).fontSize(15).fontColor(C.text).fontWeight(FontWeight.Bold)
Text(desc).fontSize(13).fontColor(C.textLight).lineHeight(20)
}.margin({ left: 12 }).layoutWeight(1)
}.alignItems(VerticalAlign.Top)
}.padding(14).backgroundColor(C.cardBg).borderRadius(14)
.borderWidth(1).borderColor(C.cardBorder).margin({ bottom: 8 })
}
8.2 常见替换表
技巧卡片下方是一个"常见替换表",用表格形式展示废话短语与建议替换的对应关系:
✗ 众所周知 → 直接陈述事实
✗ 值得注意的是 → 直接说重点
✗ 总的来说 → 因此/所以/删掉
✗ 在一定程度上 → 具体量化
✗ 有关部门 → 具体部门名
✗ 大概/可能/也许 → 据数据/依据是
✗ 非常/极其/特别 → 具体描述
✗ 我想说的是 → "我想说的已经说了"
这些替换规则与检测引擎中的规则一一对应。用户在检测中发现了某个废话短语,可以切换到建议 Tab 查看对应的替换建议。这种"检测发现问题 → 建议学习改进"的闭环设计,体现了 App 的教育价值。
8.3 建议 Tab 的教育价值
与其他工具类 App 不同,废话过滤器不仅有"检测"功能,还有"建议"功能。这体现了产品设计的教育理念——不只是指出问题,还帮助用户学习和改进。
建议 Tab 中的内容组织方式参考了语言学习类产品的设计:先给出一般性原则(五条技巧),再提供具体的替换示例(常见替换表)。这种"从抽象到具体"的知识呈现方式,符合人类的认知学习规律。
9. 编译错误全记录
9.1 错误概览
本 App 出现 12 个编译错误,在系列中属于中等偏上水平。
| # | 错误类型 | 位置 | 根因 |
|---|---|---|---|
| 1-3 | @Builder 中 let | 多处 Builder | 声明式 UI 中不能使用 let |
| 4-6 | 对象字面量无类型 | C 常量、map 返回值 | 缺类型声明/标注 |
| 7-8 | Text 中 let+ForEach | buildHighlightText | Span 闭包不支持变量和循环 |
| 9 | BorderOptions | buildReplaceRow | border bottom 语法不支持 |
| 10 | Record 字面量 | typeStats 初始化 | 空对象缺类型标注 |
| 11-12 | 详情弹窗渲染位置 | buildDetailDialog | if 在 Column 内而非 Stack 内 |
9.2 关键错误 1:Text 组件内变量声明
现象:在 buildHighlightText 方法中,Text() { let lastIdx = 0; ... } 编译报错。
根因:Text 组件的内容构建器是一个特殊上下文,只接受 Span() 子组件。在 Text() { } 闭包中,不能使用 let 声明变量,也不能使用 ForEach 循环来动态生成 Span。
// ❌ 错误:Text 闭包中不能使用 let 和 ForEach
Text() {
let lastIdx = 0; // 编译错误
ForEach(sorted, (r) => { // 编译错误
Span(r.phrase)
})
}
// ✅ 正确:直接显示原文,不使用 Span 高亮
Text(this.inputText) // 简化处理
教训:Text 组件的构建器不是通用 Builder 上下文,它有自己严格的内容规则。想要在 Text 中实现富文本高亮,需要使用不同的方案(如多个 Text 组件拼合或自定义组件)。
9.3 关键错误 2:BorderOptions 不支持 side 属性
现象:.border({ bottom: { width: 1, color: ... } }) 编译报错"‘bottom’ does not exist in type ‘BorderOptions’"。
根因:ArkTS 的 BorderOptions 类型不支持 bottom/top/left/right 等单边属性。这与 CSS 的 border-bottom 语法不同。
// ❌ 错误:ArkTS 不支持单边 border
Row() { }
.border({ bottom: { width: 1, color: '#ccc' } })
// ✅ 正确:使用完整的 border 设置
Row() { }
.borderWidth(1).borderColor('#ccc')
// 或者删除单边边框,改用 Divider 组件
教训:ArkTS 的样式 API 与 Web 端的 CSS 有显著差异。不要假设 CSS 中的语法在 ArkTS 中同样存在。遇到不熟悉的属性时,先查阅 API 文档而不是凭 Web 经验猜测。
9.4 关键错误 3:详情弹窗的渲染层级
现象:详情弹窗 buildDetailDialog 在 Column 内部渲染,被 Column 的布局约束,无法正确显示在屏幕中央。
根因:详情弹窗是全屏遮罩 + 居中弹窗的布局,应该在 Stack 的最外层渲染,而不是在 Column 内部。放在 Column 内部时,弹窗会受 Column 的宽度/高度约束,无法覆盖整个屏幕。
// ❌ 错误:弹窗在 Column 内部
build() {
Stack() {
Column() {
this.buildHeader()
this.buildTabBar()
this.buildDetailDialog() // 受 Column 约束
}
}
}
// ✅ 正确:弹窗在 Stack 层级
build() {
Stack() {
Column() {
this.buildHeader()
this.buildTabBar()
}
if (this.showDetail) {
this.buildDetailDialog() // 覆盖整个 Stack
}
}
}
教训:当需要渲染全屏覆盖层(弹窗、加载动画、Toast)时,一定要在 Stack 层级渲染,而不是在有布局约束的 Column/Row 内部。
9.5 十四款 App 错误数趋势
22 → 17 → 16 → 1 → 12 → 12 → 10 → 4 → 11 → 11 → 3 → 8 → 7 → 12
第十四款 App 的错误数反弹到 12 个,略高于前两款的 8 个和 7 个。原因是本 App 引入了新的 UI 模式(Text 组件的高亮和详情弹窗),带来了三个新的错误类型。这也说明一句话:每一次尝试新东西,都可能遇到新错误。
9.6 ArkTS 编译错误的免疫系统
经过十四款 App 的反复试错,我们已经建立了一套对 ArkTS 编译错误的"免疫系统":
已形成条件反射的错误(不再犯):
- 颜色常量缺类型 → 建立 ColorScheme + C 的模式
- @Builder 中 let → 所有逻辑移到普通方法
- 展开运算符 → 使用 concat 替代
- 弹窗用 return → 使用 if 包裹
仍然会偶尔犯的错误(新功能引入):
- Text 组件特殊限制 → 每次用到 Text 都要回想
- 不熟悉的 API 语法 → 先查文档再使用
- 渲染层级问题 → 画组件树检查层级
这种"免疫系统"会随着项目经验不断累积,犯错频率逐步降低。
10. 十四款 App 全景回顾
10.1 数据总览
| # | App | 行数 | 错误数 | Type |
|---|---|---|---|---|
| 1 | 🎵 白噪音 | 767 | 16 | 工具 |
| 2 | ⏳ 时间胶囊 | 955 | 17 | 工具 |
| 3 | 🧊 冰箱剩菜 | 1320 | 22 | 工具 |
| 4 | 😅 尴尬粉碎机 | 953 | 1 | 工具 |
| 5 | 🛡️ 防骗训练 | 1038 | 12 | 教育 |
| 6 | 💡 碎片学习 | 851 | 12 | 教育 |
| 7 | 🐶 宠物日记 | 450 | 10 | 工具 |
| 8 | 🗑️ 情绪垃圾桶 | 390 | 4 | 工具 |
| 9 | 🧭 线下寻宝 | 447 | 11 | 社交 |
| 10 | 🗡️ 订阅刺客 | 478 | 11 | 工具 |
| 11 | 🎑 声音明信片 | 458 | 3 | 工具 |
| 12 | 🎲 家庭大富翁 | 537 | 8 | 游戏 |
| 13 | 📚 二手书漂流瓶 | 452 | 7 | 社交 |
| 14 | 🧹 废话过滤器 | 542 | 12 | 工具 |
10.2 错误类型终极统计
十四款 App 共约 146 个编译错误,分布如下:
| 错误类型 | 数量 | 占比 | 首次出现 |
|---|---|---|---|
| @Builder 语法(let/return/闭包) | 52 | 36% | App 2 |
| 对象字面量无类型 | 14 | 10% | App 1 |
| 属性不存在/拼写错误 | 18 | 12% | App 1 |
| 展开运算符 | 6 | 4% | App 3 |
| 级联错误 | 24 | 16% | 多款 |
| Text 组件限制 | 3 | 2% | App 14 |
| BorderOptions 语法 | 2 | 1% | App 14 |
| 渲染层级问题 | 2 | 1% | App 14 |
| @Builder 注解缺失 | 1 | 1% | App 13 |
| 其他 | 24 | 16% | 各款 |
10.3 十四款 App 的关键教训
| # | App | 最大教训 |
|---|---|---|
| 1 | 白噪音 | 颜色对象需要 interface |
| 2 | 时间胶囊 | @Builder 不能用 let |
| 3 | 冰箱剩菜 | 闭包不能传给 @Builder |
| 4 | 尴尬粉碎机 | 模式复用可大幅降错 |
| 5 | 防骗训练 | 大段 Builder 分批重构 |
| 6 | 碎片学习 | ForEach key 函数作用域 |
| 7 | 宠物日记 | 紧凑风格减少 50% 代码 |
| 8 | 情绪垃圾桶 | ForEach key 用值本身 |
| 9 | 线下寻宝 | 残留代码导致级联错误 |
| 10 | 订阅刺客 | 暗色主题设计 |
| 11 | 声音明信片 | setInterval 要清理 |
| 12 | 家庭大富翁 | 展开运算符替代 |
| 13 | 二手书漂流瓶 | @Builder 注解不能缺 |
| 14 | 废话过滤器 | Text 组件不支持变量声明 |
11. ArkUI 开发经验再总结
11.1 十四条铁律
经过十四款 App 的实践,在十三条铁律的基础上新增一条:
- Builder 不放逻辑 — 占编译错误 36%,最重要的规则
- 颜色声明接口 — 每次都忘,每次都错
- 数组修改用 concat — 不用展开运算符
- 弹窗用 if 包裹 — 不用 return
- ForEach key 独立作用域 — key 函数不能访问 index
- Row 不支持 borderBottomWidth — 用 Divider
- 检查残留代码 — 级联错误的根源
- 数据模型先行 — 先 interface 后 UI
- 紧凑风格 — Builder 越短错误越少
- 模式复用 — 新 App 用已验证模式
- setInterval 要清理 — aboutToDisappear 中清除
- @Builder 注解不能缺 — 第 13 款 App 的教训
- JSON.parse 需显式类型 — 用 Record<string, Object>
- Text 组件禁用变量声明 — Text 闭包只接受 Span
11.2 新发现:Text 组件的限制
Text 组件是 ArkUI 中最常用的基础组件之一,但它有一些容易被忽视的限制:
-
内容构建器只接受 Span:
Text() { Span('hello') }是唯一合法的用法。不支持Text() { let x = 1; Span('hello') }。 -
不支持 ForEach:无法在 Text 内部使用 ForEach 动态生成 Span 序列。如果需要在 Text 中展示动态分段内容,需要提前计算好内容,或者在外部使用多个 Text/Row 组件。
-
条件渲染受限:
Text() { if (cond) { Span('yes') } }在某些版本中也会报错。
替代方案:如果需要在文本中混合不同样式的片段(如高亮),可以使用 Row + Text 组合:
Row() {
Text('普通文字').fontSize(14)
Text('高亮文字').fontSize(14).fontColor(C.danger)
Text('更多普通文字').fontSize(14)
}
11.3 开发效率提升 2.0
废话过滤器 App 的开发模式有了进一步优化:
-
纯业务逻辑与 UI 完全分离:检测算法、统计计算全部放在普通方法中,Builder 中只保留 UI 构建。
-
非 UI 方法使用完整 TypeScript:普通方法不受 ArkTS 声明式 UI 的限制,可以使用 let、for、map、sort 等所有 TypeScript 特性。
-
Builder 的极致精简:每个 Builder 方法只包含 UI 声明和简单的三元表达式,没有变量声明,没有循环。
这种"厚逻辑薄 UI"的开发模式,将 Builder 中的代码量降到最低,从源头上避免了绝大部分编译错误。
10.4 从工具到教育
第十四款 App 废话过滤器在类型上属于"工具",但它融入了"教育"的属性。它不是简单地完成一件事,而是帮助用户学习和成长。这种"工具 + 教育"的混合模式,可能是未来 App 开发的一个方向——用户不仅需要一个功能,还需要使用这个功能的过程本身带来价值。
12. 结语
12.1 十四款 App 的开发历程
App1 🎵 白噪音 → 初识 ArkUI
App2 ⏳ 时间胶囊 → 数据持久化
App3 🧊 冰箱剩菜 → Tab 架构
App4 😅 尴尬粉碎机 → 模式复用
App5 🛡️ 防骗训练 → 适老化
App6 💡 碎片学习 → 学习激励
App7 🐶 宠物日记 → 紧凑风格
App8 🗑️ 情绪垃圾桶 → 情感交互
App9 🧭 线下寻宝 → 社交互动
App10 🗡️ 订阅刺客 → 暗色主题
App11 🎑 声音明信片 → 模拟录音
App12 🎲 家庭大富翁 → 回合制游戏
App13 📚 二手书漂流瓶 → 随机匹配
App14 🧹 废话过滤器 → 自然语言检测
12.2 自然语言检测的技术意义
废话过滤器是系列中首款涉及自然语言处理的应用。虽然我们的技术方案仍然是基于字符串匹配的简单规则引擎,但它展示了一个重要的思路:在移动端做轻量级 NLP 应用,不一定需要大模型,不一定要联网,一个精心设计的规则库 + 巧妙的算法,就能创造出有价值的工具。
这种"小而美"的 NLP 应用在健康、写作、学习等领域有广阔的应用空间:
- 语气检测器:检测一段文字中的情绪倾向
- 被动语态检测器:帮写作者减少被动语态
- 阅读难度评估:计算文章的字数和难词比例
- 关键词提取:从长文中自动提取关键词
12.3 ArkUI 的终极评价(第二次修订)
经过十四款 App 的实践,ArkUI 的评价体系更加完整。
优势:
- 声明式 DSL 适合快速原型开发
- @State 响应式直观且高效
- 组件 API 持续改进(BorderRadius 支持四个角单独设置)
- 编译时类型检查可提前发现大量问题
不足:
- @Builder 语法约束过严(占编译错误 36%)
- Text 组件构建器限制过多
- 错误恢复能力不足(一个错误 = 多个级联错误)
- 部分 API 文档与实际行为不一致
最新发现的问题:
- BorderOptions 不支持单边属性,与 Web CSS 差异较大
- 弹窗渲染层级容易搞错,需要在 Stack 层而非 Column 层渲染
12.4 给开发者的建议(追加)
基于废话过滤器的开发经验,给 ArkUI 开发者追加四条建议:
- Text 组件谨慎使用:如果需要富文本展示,考虑用 Row + 多个 Text 替代单个 Text + Span。
- Stack 用于覆盖层:弹窗、遮罩、加载动画都在 Stack 中渲染。
- 规则引擎是 MVP 的好方案:不需要一开始就上大模型,简单的规则引擎可以快速验证产品价值。
- 写博客记录错误:每解决一个编译错误,就记录下来。十四款 App 积累了 146 个错误样本,这些数据比官方文档更有价值。
12.5 感谢与展望
十四款 App、十四篇博客、约 150,000 字——从 6 月 13 日到 6 月 14 日,完成了全部 App 开发和博客撰写。感谢每一位读者的陪伴。
本系列的核心理念一直未变:最好的学习方法,就是亲手去写。ArkUI 的每一条规则,都是用编译错误换来的;每一款 App 的每一个功能,都是反复试错的结果。
现在,打开 DevEco Studio,去创造属于你自己的 App 吧。
附录 A:第十四款 App 核心代码
检测引擎
doAnalyze(): void {
let text = this.inputText.trim();
if (text.length === 0) return;
let list: DetectionResult[] = [];
let used: Set<number> = new Set();
for (let np of FILLER_PHRASES) {
let pos = 0;
for (; ;) {
let idx = text.indexOf(np.phrase, pos);
if (idx === -1) break;
let overlap = false;
for (let i = idx; i < idx + np.phrase.length; i++) {
if (used.has(i)) { overlap = true; break; }
}
if (!overlap) {
list.push({
phrase: np.phrase, type: np.type, icon: np.icon,
index: idx, suggestion: np.suggestion
});
for (let i = idx; i < idx + np.phrase.length; i++) used.add(i);
}
pos = idx + 1;
}
}
list.sort((a, b) => a.index - b.index);
let totalChars = 0;
for (let r of list) totalChars += r.phrase.length;
this.score = Math.min(100, Math.round((totalChars / Math.max(text.length, 1)) * 100));
this.results = list;
this.analyzed = true;
let clean = text;
let rev = list.concat([]).sort((a, b) => b.index - a.index);
for (let r of rev) {
if (r.type !== '模糊词') {
clean = clean.substring(0, r.index) + clean.substring(r.index + r.phrase.length);
}
}
this.cleanedText = clean.replace(/\s+/g, ' ').trim();
}
废话数据库(45 条规则节选)
const FILLER_PHRASES: NonsensePhrase[] = [
{ phrase: '众所周知', type: '空话', icon: '📢', suggestion: '直接陈述事实' },
{ phrase: '值得注意的是', type: '空话', icon: '📢', suggestion: '直接说明重点' },
{ phrase: '从某种意义上说', type: '模糊', icon: '🌫️', suggestion: '具体说明意义' },
{ phrase: '有关部门', type: '套话', icon: '🏛️', suggestion: '指明具体部门' },
{ phrase: '总的来说', type: '废话', icon: '🗑️', suggestion: '直接给出结论' },
{ phrase: '大概', type: '模糊词', icon: '❓', suggestion: '用量化数据替代' },
{ phrase: '非常', type: '夸张', icon: '🔥', suggestion: '用具体描述替代' },
// ... 共 45 条
];
附录 B:系列速查
| 指标 | 数值 |
|---|---|
| App 数量 | 14 |
| 博客总字数 | ~150,000 字 |
| 代码总行数 | ~9,700 行 |
| 编译错误 | ~146 个 |
| @Builder 方法 | ~185 个 |
| 修复轮次 | 28 轮 |

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)