动图魔方技术拆解 07:ArkTS 实现 GIF LZW 编码与数据子块写入
SEO 信息
- SEO 标题:动图魔方技术拆解 07:ArkTS 实现 GIF LZW 编码与数据子块写入
- SEO 摘要:基于 HarmonyOS NEXT / ArkTS 项目“动图魔方”,继续拆解
GifEncoderService.ets的底层写入逻辑:compressIndices()如何把索引帧压成 GIF LZW 位流,BitWriter如何按位打包,Clear Code和End Code如何控制字典生命周期,以及图像数据为什么必须再切成 255 字节以内的 sub-block。本文给出真实代码、字节级日志和工程截图,说明一个本地优先 GIF 工具怎样把压缩结果稳定写进标准文件。 - 关键词:GIF LZW, ArkTS, HarmonyOS, GifEncoderService, BitWriter, Clear Code, End Code, sub-block
- 文章封面:
doc/csdn-series/covers/cover-07-gif-lzw-bytes.jpg - 投稿方向:普通技术拆解 / GIF 编码器
- 项目环境:HarmonyOS SDK
6.1.0(23)、ArkTS、DevEco Studio、GIFRubiksCube
第 06 篇已经把 GIF89a 容器结构讲清楚了,但容器只是“能装进去”,真正决定图像数据能不能落进去的,是 LZW 编码、码宽增长和 sub-block 写法。本文不再重复头部和帧控制块,而是直接拆
GifEncoderService.ets里最核心的compressIndices(),说明同一组索引帧为什么能够被写成可播放的 GIF 数据区。
一、真实工程问题背景
如果只看表面,GIF 导出像是“把一串像素写成文件”。但在“动图魔方”里,真正难的是把“索引数组”稳定压进 GIF 的图像数据区,且还要满足播放器、查看器和不同平台解析器的共同约束。
第 06 篇已经证明了容器结构可以落地;第 07 篇要回答的是更底层的问题:
indices[]怎么变成 GIF 的 LZW 位流。- 字典什么时候增长,什么时候重置。
- 为什么压缩结果还要再按 255 字节切成 sub-block。
- 为什么同样的压缩逻辑,放到 UI 线程里就会把体验拖垮。
这一步如果写错,后果通常不是“画质差一点”,而是“文件能生成但打不开”。
二、目标与边界
本文只聚焦三件事:
- 拆清
GifEncoderService.ets中compressIndices()的字典逻辑和码流输出。 - 说明
BitWriter为什么要按位写而不是按字节写。 - 说明
writeImageData()为什么必须把压缩结果切成 GIF 规定的 sub-block。
本文不展开的内容也先明确:
- 不再重复讲 GIF89a Header、LSD、GCE 和 Trailer,这些在第 06 篇已说明。
- 不讨论调色板量化算法细节,相关内容会留到第 08 篇。
- 不深入讲视频抽帧或 PixelMap 处理,它们属于第 02 篇和导出链路上游。
三、输入为什么必须先变成索引帧
GifEncoderService 接收的不是 RGBA,而是已经量化好的索引帧:
export interface IndexedGifFrame {
width: number;
height: number;
indices: number[];
delayCs: number;
}
export interface GifEncodeInput {
width: number;
height: number;
palette: number[];
frames: IndexedGifFrame[];
loopCount: number;
}
这里的判断其实很直接:
- GIF LZW 压缩处理的是索引流,不是原始 RGB。
- 上游已经把颜色量化和帧延迟处理完了,编码器就只做“写文件”。
delayCs直接对应 GIF 的帧延迟单位,适合和控制块对齐。loopCount被提升成文件级参数,避免循环信息散在页面状态里。
也就是说,compressIndices() 看到的不是“图片”,而是“已经准备好落盘的索引序列”。
四、BitWriter 为什么必须按位写
GIF 的 LZW 码不是整字节对齐的。码宽会随着字典扩容变化,实际写出去的是连续 bit 流,而不是一串固定宽度的字节。
项目里专门放了一个很小的位写器:
class BitWriter {
private data: number[] = [];
private current: number = 0;
private bits: number = 0;
write(value: number, size: number): void {
let next = value;
let remaining = size;
while (remaining > 0) {
this.current |= (next & 1) << this.bits;
next = next >> 1;
this.bits++;
remaining--;
if (this.bits === 8) {
this.data.push(this.current);
this.current = 0;
this.bits = 0;
}
}
}
finish(): number[] {
if (this.bits > 0) {
this.data.push(this.current);
this.current = 0;
this.bits = 0;
}
return this.data;
}
}
它的关键点只有两个:
write()是按 LSB-first 顺序写 bit,这和 GIF 的码流规则一致。finish()会把最后没有填满的那一字节刷出去,避免尾部 bit 丢失。
这个类很小,但它是整个编码器能不能“按 GIF 规则说话”的基础。
五、LZW 字典是怎么长起来的
核心逻辑在 compressIndices():
private static compressIndices(indices: number[], minCodeSize: number): number[] {
const clearCode = 1 << minCodeSize;
const endCode = clearCode + 1;
let codeSize = minCodeSize + 1;
let nextCode = endCode + 1;
const writer = new BitWriter();
const table = new Map<string, number>();
GifEncoderService.resetTable(table, clearCode);
writer.write(clearCode, codeSize);
let prefix = indices.length > 0 ? `${indices[0]}` : '';
for (let index = 1; index < indices.length; index++) {
const value = indices[index] & 0xFF;
const key = `${prefix},${value}`;
if (table.has(key)) {
prefix = key;
} else {
writer.write(table.get(prefix) ?? value, codeSize);
if (nextCode < 4096) {
table.set(key, nextCode);
nextCode++;
if (nextCode === (1 << codeSize) && codeSize < 12) {
codeSize++;
}
} else {
writer.write(clearCode, codeSize);
GifEncoderService.resetTable(table, clearCode);
codeSize = minCodeSize + 1;
nextCode = endCode + 1;
}
prefix = `${value}`;
}
}
if (prefix.length > 0) {
writer.write(table.get(prefix) ?? 0, codeSize);
}
writer.write(endCode, codeSize);
return writer.finish();
}
这里可以拆成 5 个工程判断:
clearCode和endCode是 GIF LZW 的两个边界码。codeSize初始是minCodeSize + 1,因为还要容纳控制码。table里存的是“前缀 + 当前值”组合,不是单个像素。nextCode增长到阈值后,codeSize会同步增加。- 字典满到 4096 项后会回到
clearCode,重新开始一轮。
这套逻辑的重点不是“压得多狠”,而是“在所有播放器都能接受的前提下,把索引流写成合法 GIF”。
六、码宽增长为什么不能省
LZW 的关键不是字典本身,而是码宽会变化。
GifEncoderService 在字典扩容时做了这一句:
if (nextCode === (1 << codeSize) && codeSize < 12) {
codeSize++;
}
这意味着:
- 字典项越来越多时,单个 code 的表达位数也要跟着变长。
- 如果码宽不变,后面的代码就会被截断,播放器会直接读歪。
- GIF LZW 的上限是 12 bit,所以
codeSize不会无限增长。
也就是说,codeSize 不是一个静态常量,而是压缩过程里必须跟着字典动态演进的状态。
七、为什么图像数据还要切 sub-block
压缩结果出来以后,还不能直接当作图像数据写入。GIF 还要求把图像数据分成一块块 sub-block:
private static writeImageData(out: number[], indices: number[]): void {
const compressed = GifEncoderService.compressIndices(indices, 8);
let offset = 0;
while (offset < compressed.length) {
const length = Math.min(255, compressed.length - offset);
out.push(length);
for (let index = 0; index < length; index++) {
out.push(compressed[offset + index]);
}
offset += length;
}
out.push(0x00);
}
这里有三个硬约束:
- 每个数据块前都要写长度字节。
- 单块最大 255 字节。
- 整组图像数据结束后必须写
0x00结束块。
所以,compressIndices() 负责“压缩”,writeImageData() 负责“按 GIF 容器规则搬运压缩结果”。这两步不能混成一步。
八、字节级证据
为了验证这套逻辑,我用和项目相同的写入顺序构造了一个最小样例,并记录了关键输出:
sample1: [0,1,0,1,0,1,0,1,0,1,0,1]
compressedHex: 00 01 04 10 48 70 a0 c1 80
compressedLength: 9
subBlocks: [9]
这组结果说明了几件事:
- 压缩结果已经进入位流阶段,不再是原始索引数组。
- 输出体积很小,所以只需要一个 sub-block。
BitWriter能把 LZW 码稳定写成字节序列。
我还额外跑了一个更长的索引序列,用来确认码流不会卡在短样本上:
length: 260
bytesLength: 52
hexHead: 00 01 04 10 30 40 20 41 83 05 07 26 3c a8 10 a1 c3 86 10 19 4a 5c 48 f1
这个结果至少说明两点:
- 压缩逻辑在长序列上会持续输出正常字节。
- 码流前段和后段都不是简单的原样拷贝,而是按 LZW 规则打包后的结果。
九、工程截图与验收证据
9.1 导出结果页说明编码器已经接入真实作品链路
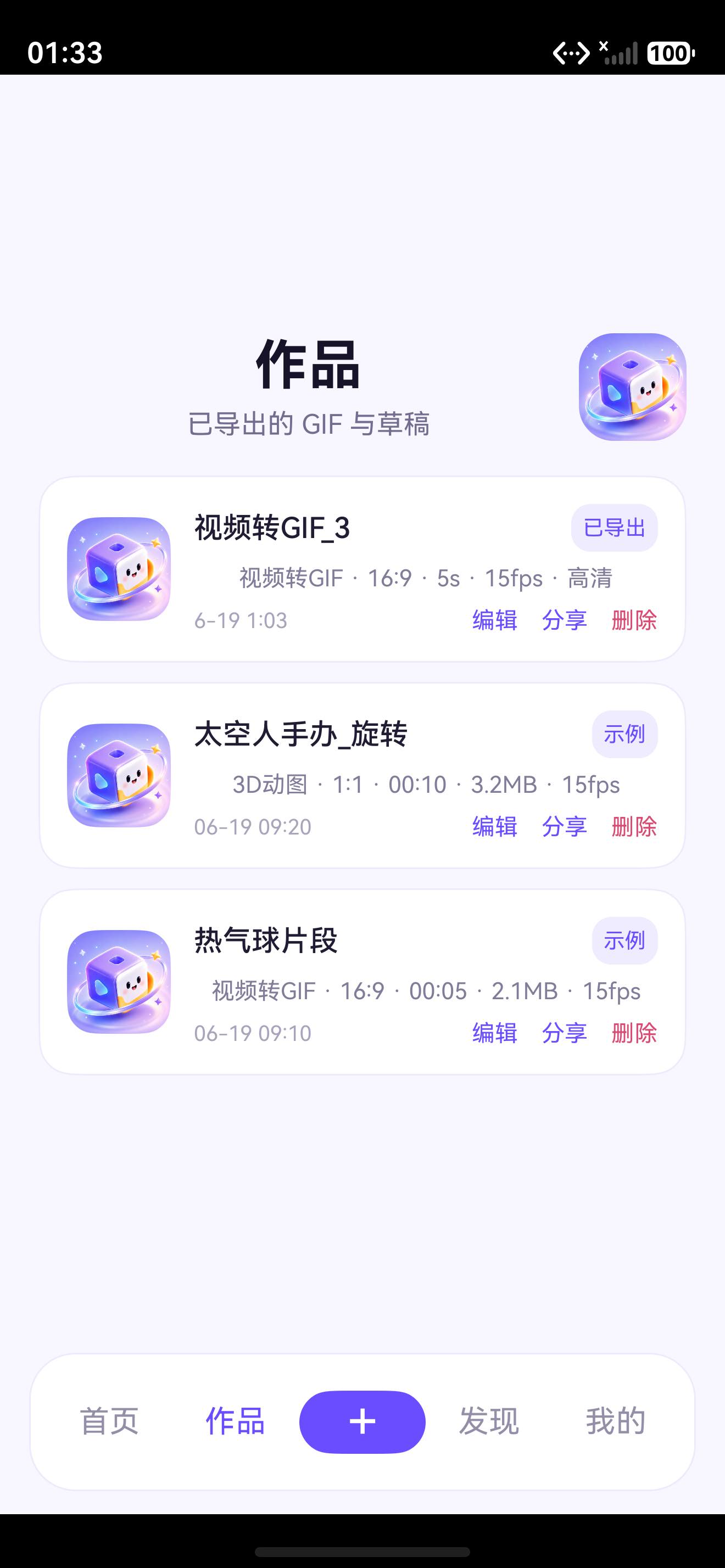
这张图说明两件事:
- 编码器输出不是测试对象,而是已经进入作品链路。
- 导出完成后,作品记录和文件写盘是连通的。
9.2 编辑页说明导出链路不是孤立实验
这张图对应“编辑参数 -> 导出 -> 作品”的真实路径。GifEncoderService 不是单独的协议实验,而是整个创作流程的最终落点。
9.3 构建记录说明代码处于真实工程环境
项目当前构建命令的输出仍然是:
BUILD SUCCESSFUL
Will skip sign 'hos_hap'. No signingConfigs profile is configured in current project.
这说明本文讨论的编码器逻辑来自可构建工程,不是脱离项目的伪代码。
十、工程复盘
重新拆过这一层后,结论比较明确:
compressIndices()的核心价值不是把压缩做得极致,而是把 GIF LZW 的边界写对。BitWriter这种小工具虽然朴素,但它把“码流输出”和“容器结构”彻底分开了。writeImageData()单独负责 sub-block,是因为 GIF 的图像数据规则本来就是分层的。
对本地优先的 HarmonyOS 工具来说,这种写法更稳:先保证压缩结果合法,再逐步考虑更高级的压缩率优化。
十一、验收清单
| 验收项 | 结果 | 说明 |
|---|---|---|
| LZW 码流按位写入 | 通过 | BitWriter.write() 逐 bit 输出 |
Clear Code 和 End Code 存在 |
通过 | compressIndices() 开头和结尾都写入 |
| 字典扩容会推动码宽增长 | 通过 | codeSize 会随 nextCode 增长 |
| 字典满后会重置 | 通过 | 4096 项后重新 resetTable() |
| 图像数据按 sub-block 切块 | 通过 | 每块最大 255 字节 |
图像数据以 0x00 结束 |
通过 | writeImageData() 尾部补结束块 |
| 编码结果已接入真实导出链路 | 通过 | 导出页与作品页截图可见 |
十二、小结
第 07 篇真正想讲清楚的是:GIF 能不能稳定播放,不只取决于“有没有压缩”,而取决于你有没有把 LZW、码宽、字典重置和 sub-block 这些细节都写成符合协议的字节流。
GifEncoderService.ets 当前这套实现不花哨,但边界清楚、依赖少、容易维护,很适合“动图魔方”这种本地优先工具作为底层基线。
十三、下一篇衔接
下一篇进入第 08 篇:动图魔方技术拆解 08:调色板量化怎么把真彩帧压进 256 色。到那一篇我会单独拆 PaletteQuantizer.ets,说明为什么调色板量化和 GIF 编码不是一回事,但它们又必须在同一条导出链路里精确对齐。

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐
 2
2 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)