【红外目标检测实战】yolov11引入空洞卷积、人工特征,详细代码和过程
红外微小目标检测实验
红外微小目标检测,是我近期的实验主题,很多红外目标的像素非常少,基本是低于16x16的,甚至低于8x8的也不在少数。yolo系列原始网络训练出来的模型,对于此类检测召回率很低,因此本文对改进的Yolov11模型做了实验,记录了实验过程和结果。
【红外微小目标检测实验】是我后续会持续进行的工作,主要是根据看到的一些论文和一些方法,融入到自己的项目中,进行效果测试,旨在找到一个适合自己数据集的,快速、准确的一个模型。
后续也会分享边缘端C++推理代码和性能优化过程记录,包括nvidia和国产瑞芯微、算能平台。
也是给自己的查缺补漏和技术分享。
前言
此实验基于yolov11 进行,代码基于ultralytics仓库修改,训练数据采用自己收集的数据,训练集8000多张,验证集2000多张,训练集基本都是小目标,数据集详情如下
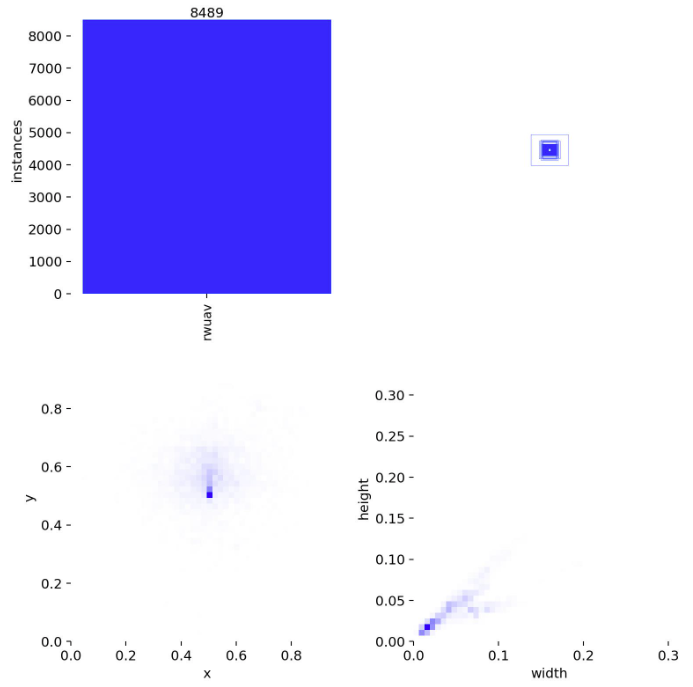
测试集使用了1000余张小目标数据,所有模型统一在此数据集上测试性能。
思路分析
yolov11的P5层特征图在640输入下是20x20的,相当于32倍下采样,用于检测大目标的,红外目标用不上,留着还有额外的计算量,因此把其删除掉。
目标过小,多层下采样会导致细节缺失,因此保留2倍下采样图和4倍下采样图,也就是P1和P2层
低层特征图噪声多,感受野小,因此考虑一些去噪层和增加感受野模块
红外目标可以考虑一些人工特征加入,低层特征图可以加入一些人工特征,融合进去
训练环境配置
ubuntu22.04
python == 3.10.18
cuda == 11.8
pytorch == 2.4.1
ultralytics == 8.3.207
模型结构分析
动手训练前,先画一下模型结构图,保证思路清晰
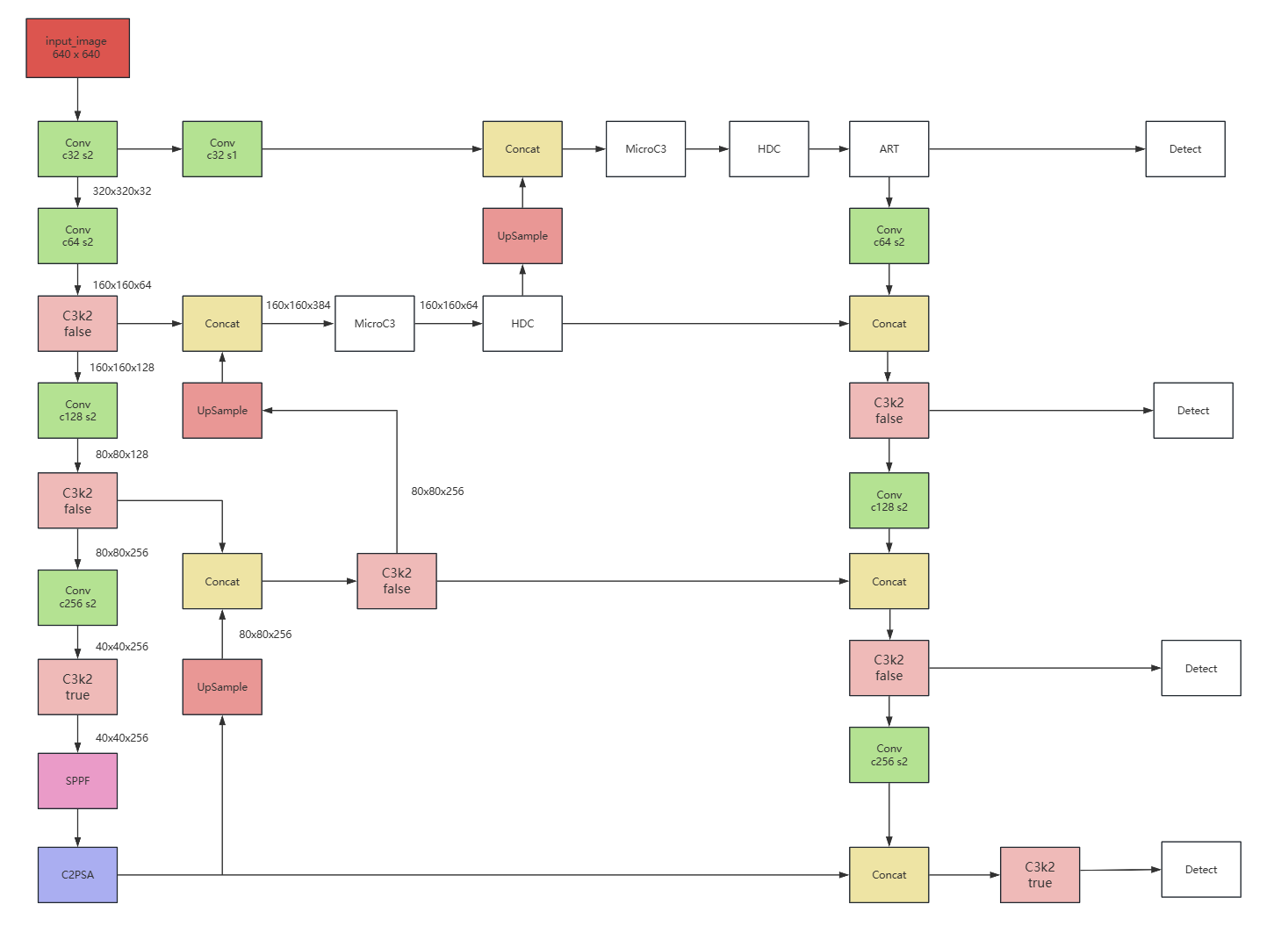
此网络删除了yolov11原始的P5层检测头,新增P1 P2层检测头,并且新增了MicroC3、HDC、ART模块在P1和P2层特征融合图中,相较于yolov11s,计算量有一定增加。
新增模块介绍
1.MicroC3
专门为微小目标设计的轻量模块,使用深度可分离卷积降低参数量,并使用通道注意力分配浅层特征图通道权重。在保持较好检测性能的同时,大幅降低了模型复杂度,适合小目标检测任务。
注意,此模块需要放在ultralytics/nn/modules/conv.py中。
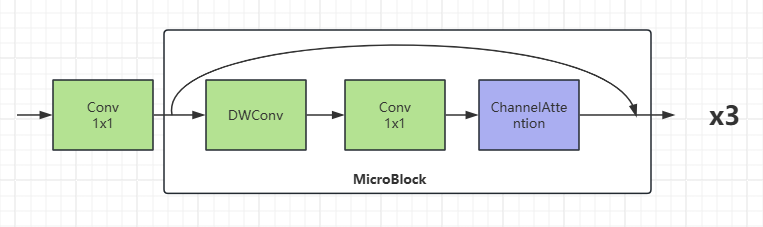
class MicroC3(nn.Module):
def __init__(self, c1, c2, n=3):
super().__init__()
self.conv1 = Conv(c1, c2, k=1)
self.micro_blocks = nn.Sequential(
*[MicroBlock(c2) for _ in range(n)]
)
def forward(self, x):
return self.micro_blocks(self.conv1(x))
class MicroBlock(nn.Module):
def __init__(self, c):
super().__init__()
self.dwconv = nn.Conv2d(c, c, 3, padding=1, groups=c) # 深度可分离卷积
self.conv1x1 = nn.Conv2d(c, c, 1)
self.attn = ChannelAttention(c) # 通道注意力
def forward(self, x):
identity = x
x = self.dwconv(x)
x = self.conv1x1(x)
x = self.attn(x)
return x + identity
2.HDC
混合空洞卷积模块,通过组合不同膨胀率(dilation rate)的空洞卷积,在不降低特征图分辨率的前提下,显著扩大感受野并捕获多尺度上下文信息的卷积结构,适用于需要高分辨率输出 + 大感受野的任务。
- conv1: 感受野3x3
- conv2: 感受野5x5
- conv3: 感受野7x7
此模块代码也是插入ultralytics/nn/modules/conv.py中
class HDC(nn.Module):
"""混合空洞卷积 - 增强感受野同时保持分辨率"""
def __init__(self, c1, c2, k=3):
super().__init__()
self.conv1 = nn.Conv2d(c1, c2, 3, dilation=1, padding=1)
self.conv2 = nn.Conv2d(c1, c2, 3, dilation=2, padding=2)
self.conv3 = nn.Conv2d(c1, c2, 3, dilation=3, padding=3)
self.fuse = nn.Conv2d(c2*3, c2, 1)
def forward(self, x):
d1 = self.conv1(x)
d2 = self.conv2(x)
d3 = self.conv3(x)
fused = torch.cat([d1, d2, d3], dim=1)
return self.fuse(fused)
3.ART
人工特征融合模块,原始特征图维度下,加上一维人工特征,3部分特征意义如下:
| 分支 | 意义 | 场景 |
|---|---|---|
| ContrastEnhance | 局部异常强度 | 热点检测 |
| LBP | 微观结构不连续性 | 边缘/角点响应 |
| GradientMagnitude | 强度变化率 | 目标边界定位 |
def __init__(self, c1, c2, k=1):按理说不需要c2, k参数,但是构造时不加的话,parse_model会报错。
class ART(nn.Module):
"""人工特征融合层(适用于红外/遥感/雷达)"""
def __init__(self, c1, c2, k=1):
super().__init__()
# 特征增强路径
self.enhance_path = nn.Sequential(
ContrastEnhance(), # 对比度增强
LocalBinaryPattern(16), # LBP纹理特征
GradientMagnitude() # 梯度幅值
)
# 特征融合路径
self.fuse_conv = nn.Sequential(
nn.Conv2d(c1+1, c1, 1), # 融合人工特征
nn.ReLU()
)
def forward(self, x):
# 原始特征 [N, C, H, W]
orig_feat = x
# 生成人工特征 [N, 1, H, W]
with torch.no_grad():
art_feat = self.enhance_path(x)
# 特征融合
fused = torch.cat([orig_feat, art_feat], dim=1)
return self.fuse_conv(fused)
# 人工特征生成组件
class ContrastEnhance(nn.Module):
def forward(self, x):
# 局部对比度增强 (CLAHE算法简化版)
return (x - x.mean(dim=[2,3], keepdim=True)) / (x.std(dim=[2,3], keepdim=True) + 1e-6)
class LocalBinaryPattern(nn.Module):
def __init__(self, radius=1):
super().__init__()
self.kernel = self._create_lbp_kernel(radius)
def _create_lbp_kernel(self, r):
# 简化版LBP算子
kernel = torch.tensor([[-1,-1,-1],[-1,8,-1],[-1,-1,-1]]).float().unsqueeze(0).unsqueeze(0)
# 注册为buffer,确保设备同步
self.register_buffer('lbp_kernel', kernel)
return kernel
def forward(self, x):
# 确保kernel与输入在同一设备和数据类型
kernel = self.lbp_kernel.to(x.device, dtype=x.dtype)
return F.conv2d(x.mean(dim=1, keepdim=True), kernel, padding=1)
class GradientMagnitude(nn.Module):
def __init__(self):
super().__init__()
# 预创建Sobel算子并注册为buffer
sobel_x = torch.tensor([[-1,0,1],[-2,0,2],[-1,0,1]]).float().view(1,1,3,3)
sobel_y = torch.tensor([[-1,-2,-1],[0,0,0],[1,2,1]]).float().view(1,1,3,3)
self.register_buffer('sobel_x', sobel_x)
self.register_buffer('sobel_y', sobel_y)
def forward(self, x):
# 确保Sobel算子与输入在同一设备和数据类型
sobel_x = self.sobel_x.to(x.device, dtype=x.dtype)
sobel_y = self.sobel_y.to(x.device, dtype=x.dtype)
x_mean = x.mean(dim=1, keepdim=True)
gx = F.conv2d(x_mean, sobel_x, padding=1)
gy = F.conv2d(x_mean, sobel_y, padding=1)
return torch.sqrt(gx**2 + gy**2 + 1e-6)
yaml配置
ultralytics/cfg/models/11/下新建yolo11-tiny.yaml文件,将下面内容写入
nc: 1 # number of classes (change as needed)
# Backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [32, 3, 2]] #
- [-1, 1, Conv, [32, 3, 1]] # 1 P1
- [ 0, 1, Conv, [64, 3, 2]] #
- [-1, 1, C3k2, [128, False, 0.25]] # 3 P2
- [-1, 1, Conv, [128, 3, 2]] #
- [-1, 1, C3k2, [256, False, 0.25]] # 5 P3
- [-1, 1, Conv, [256, 3, 2]] #
- [-1, 1, C3k2, [256, True]] #
- [-1, 1, SPPF, [256, 5]] #
- [-1, 1, C2PSA, [256]] # 9 P4
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 10 upsample P4 to P3
- [[-1, 5], 1, Concat, [1]] # 11 cat P3
- [-1, 1, C3k2, [256, False]] #
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 13 upsample P3 to P2
- [[-1, 3], 1, Concat, [1]] # 14 cat P2
- [-1, 1, MicroC3, [64]]
- [-1, 1, HDC, [64]] # 16
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 17 upsample P2 to P1
- [[-1, 1], 1, Concat, [1]] # 18 cat P1
- [-1, 1, MicroC3, [32]]
- [-1, 1, HDC, [32]]
- [-1, 1, ART, [32]] # 21 P1 head
- [-1, 1, Conv, [64, 3, 2]]
- [[-1, 16], 1, Concat, [1]] # 23 downsample p1 to p2
- [-1, 1, C3k2, [64, False]] # 24 P2 head
- [-1, 1, Conv, [128, 3, 2]]
- [[-1, 12], 1, Concat, [1]]
- [-1, 1, C3k2, [128, False]] # 27 P3 head
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 9], 1, Concat, [1]]
- [-1, 1, C3k2, [256, True]] # 30 P4 head
- [[21, 24, 27, 30], 1, Detect, [nc]]
先画结构图,再根据图写Yaml配置,避免出BUG
训练
新建train.py,训练打开了copy_paste,降低mosaic概率到0.8,训练300个epoch
由于是单微小目标,可以在default.yaml中增大分类损失和目标框损失权重。
from ultralytics import YOLO
if __name__ == '__main__':
v11 = YOLO('ultralytics/cfg/models/11/yolo11-tiny.yaml')
results = v11.train(
data = 'xxx.yaml',
epochs = 300,
batch = 16,
cache = True,
mosaic = 0.8,
close_mosaic= 20,
imgsz = 640,
copy_paste = 0.2,
device = "0",
workers = 16,
project = 'runs/train/TINY',
plots = True,
# resume = True,
)
准备好后开始训练,我的是单卡4090,预计训练10小时,明天检查下效果!
预计训练10小时,结果中途训练断了没发现,导致比预估多了一天才看到结果。
训练结果
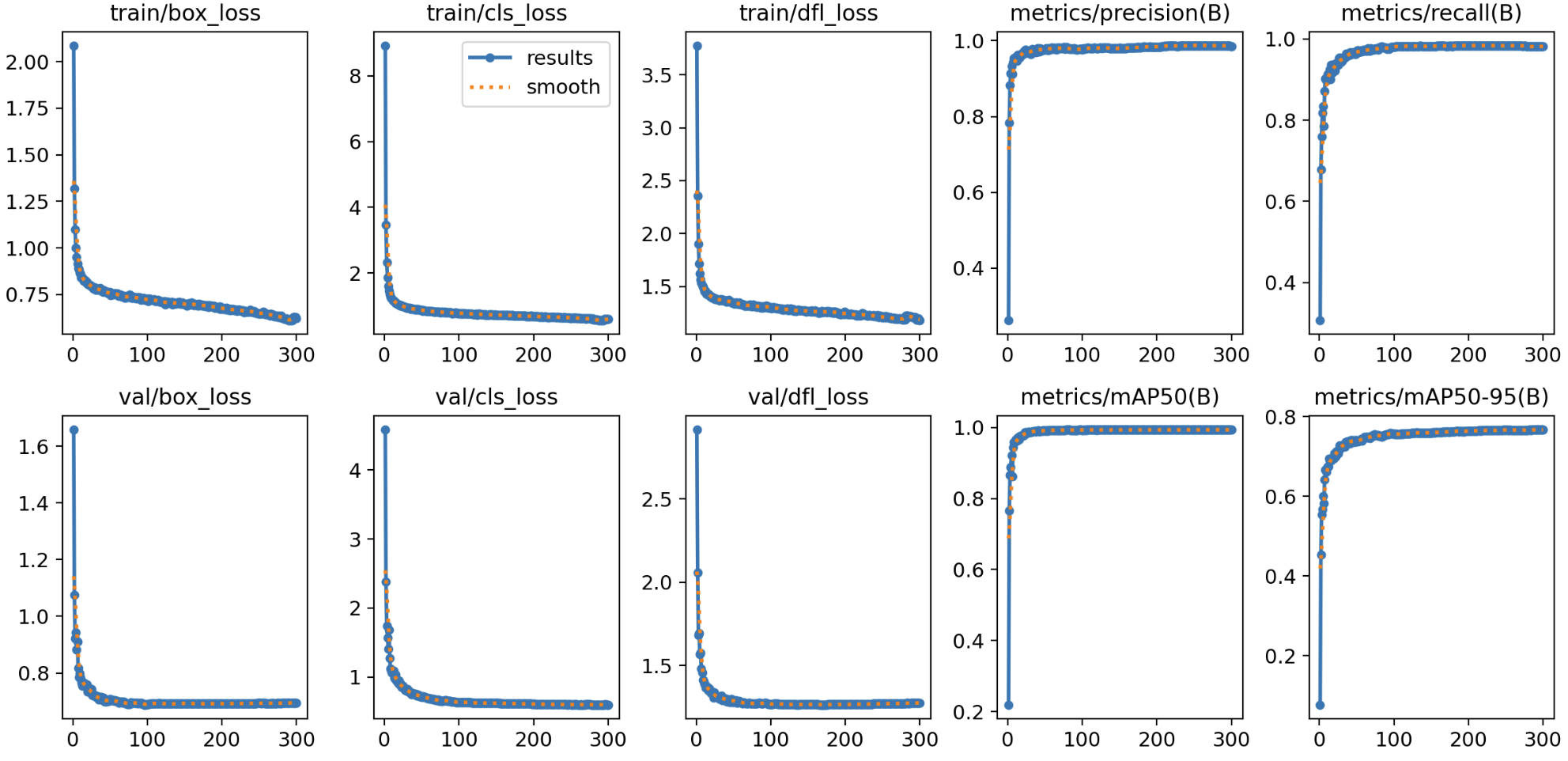
从result.png来看,训练的还不错,收敛很正常,在验证集上P R都趋近于100%,但box loss, cls loss都还有下降空间,可以考虑后续再迁移训练100+epoch。
测试集上表现
yolov11原始模型混淆矩阵,漏检409张微小目标图片,召回率为0.51
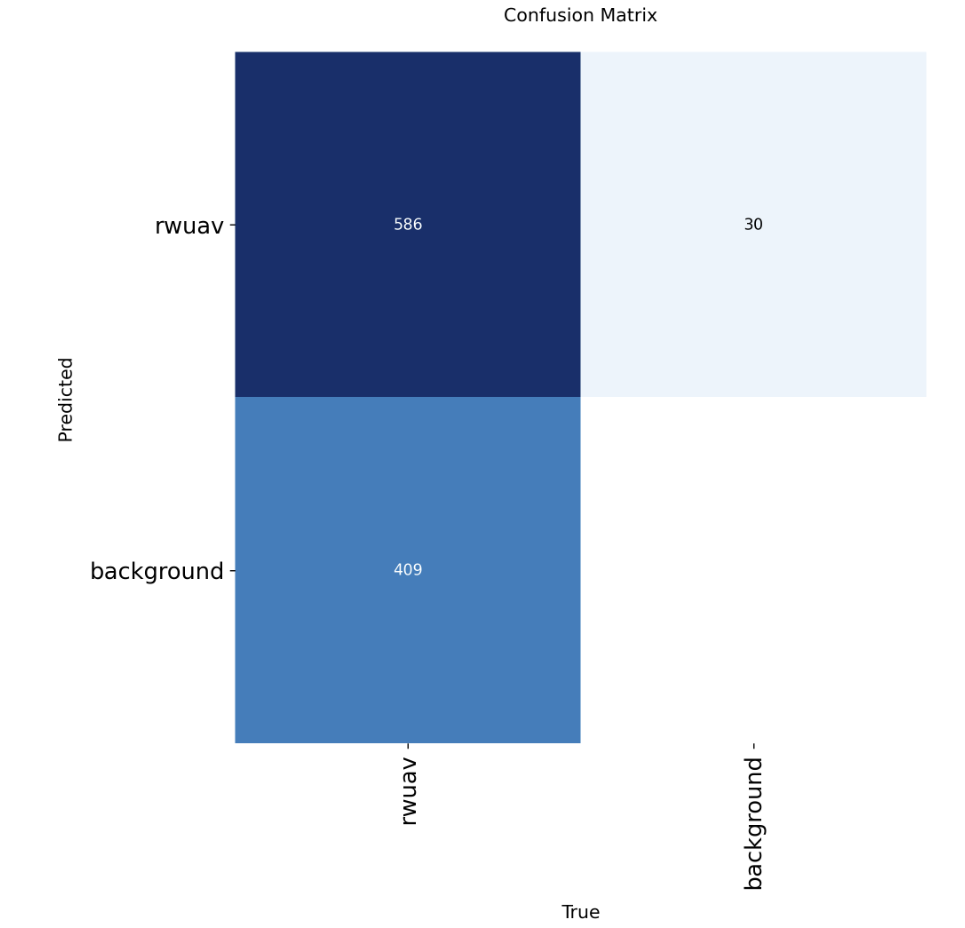
改进模型混淆矩阵:
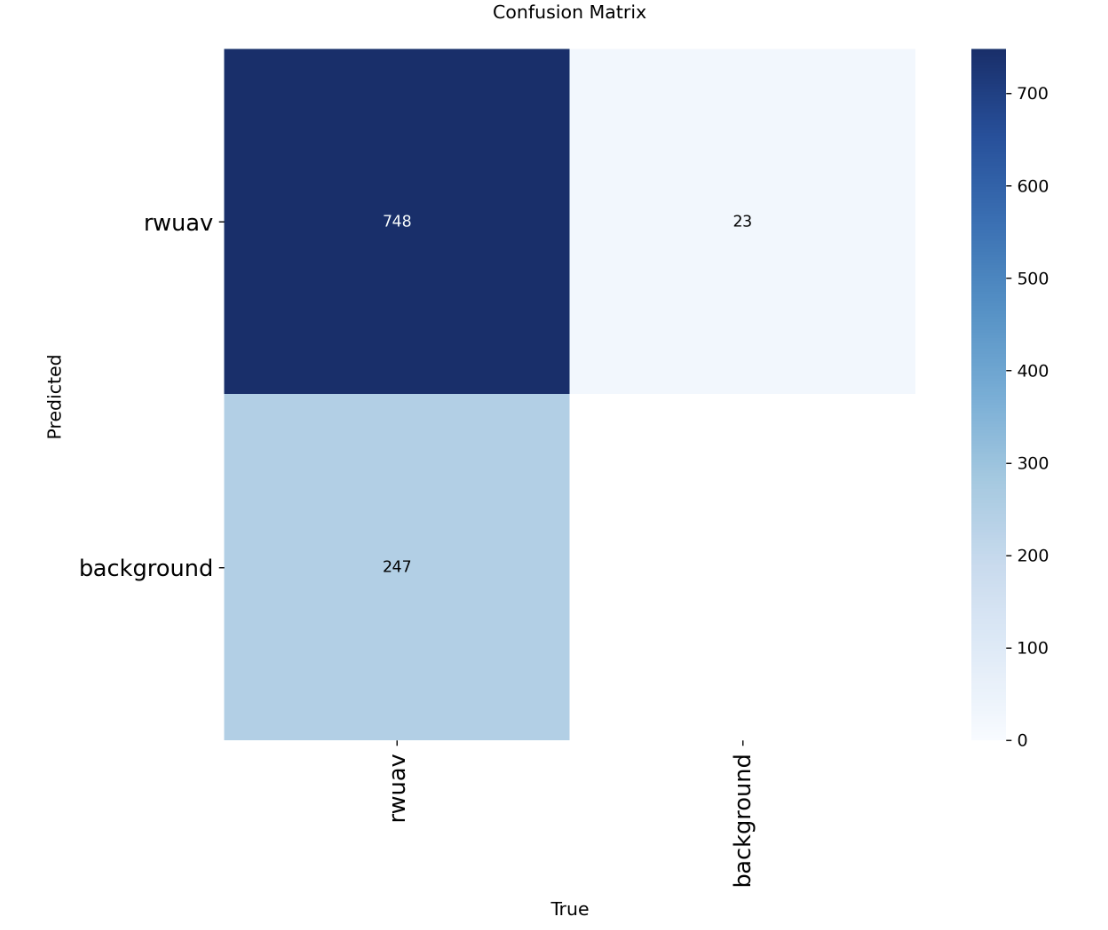
漏检图片下降近一半,召回率为0.75,上升24%,改进有一定作用!
模型漏检分析
通过可视化发现,还是有很多微小目标漏检了,比如这种

但是对于轮廓明显一点的微小目标,可以正常检出:

总体对比
| 模型 | 大小 | P | R |
|---|---|---|---|
| 优化前 | 19M | 0.95 | 0.59 |
| 优化后 | 8.1M | 0.97 | 0.71 |
后续工作
将优化后的模型转为RKNN,并在相应平台上使用C++部署

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)