HarmonyOS 6.0 实战:基于 ArkTS 严格模式构建「决策审查」反方辩论 AI 应用
HarmonyOS 6.0 实战:基于 ArkTS 严格模式构建「决策审查」反方辩论 AI 应用
技术栈:HarmonyOS 6.0 API 21 + ArkTS 严格模式 + 规则引擎 + 关键词匹配推理
应用定位:情绪剥离 → 盲区扫描 → 后果推演 → 前置条件的四步魔鬼代言人式审查
核心哲学:不提供建议,只揭示风险——这是一面镜子,不是一个拐杖
一、引言
2026 年的 AI 应用市场,正经历一场奇特的"讨好疲劳"。打开任何一个 AI 助手,它都会温柔地说:"我理解你的感受,你做得很好,以下是几个建议。"这种鼓励式对话对于情感支持是必要的,但对于决策分析,它可能是危险的。
人类在做重大决策时,大脑有一个致命的结构性缺陷:确认偏差(Confirmation Bias)——我们倾向于寻找支持自己已有观点的证据,而忽略反对证据。辞职时只看见自由,买车时只看见便利,跳槽时只看见涨薪。那些不在我们视野中的风险,往往是最终让我们付出代价的东西。
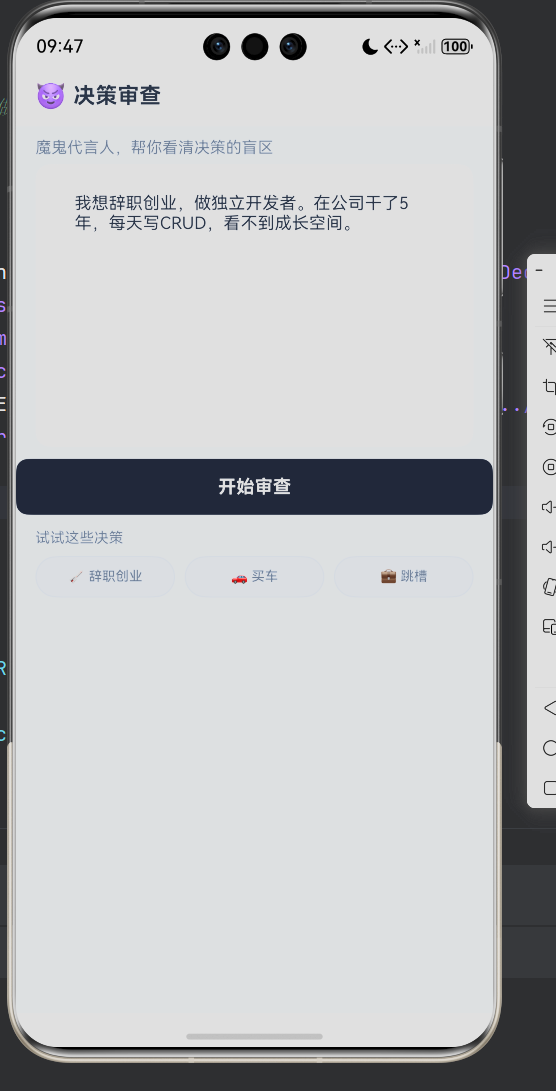
「决策审查」这款应用正是基于这个洞察而诞生。它不是一个帮你做决定的助手,而是一个不讨好你、不安抚你、只挑战你的"魔鬼代言人"(Devil’s Advocate)。输入你想做的决策,它不会告诉你"勇敢去做"或"三思而行",而是做四件事:剥离你的情绪、扫描你忽略的盲区、推演最坏情况下 1 个月/1 年/3 年的后果、列出你必须满足的硬性前置条件。
本文将从"五刀切"产品哲学、架构设计、HarmonyOS 6.0 核心特性运用、四步强制思维链推理引擎、可展开组件交互设计、以及 ArkTS 严格模式下的类型安全六个维度,深度剖析这款应用的开发实践。与一般的 HarmonyOS 教程不同,本文将大量笔墨放在"为什么这样设计"而非"怎么写代码"上——因为在 AI 应用开发中,最难的从来不是代码,而是产品决策。
二、"五刀切"产品哲学:减法是 AI 应用的灵魂
在写第一行代码之前,我花了整整一个下午做产品减法。AI 应用最容易犯的错误是"功能膨胀"——因为 LLM 什么都能做,所以开发者什么都想加。但历史经验反复证明:什么都能做的 AI 应用,最后什么都做不好。
2.1 第一刀:反共识定论——砍掉"我应该怎么做"
80% 的人会把决策类应用做成什么? 一个能聊天的人生导师,你跟它说"我想辞职",它回"辞职前请考虑以下几点:1. 你的存款够不够 2. 你有没有下家……"然后你可以继续追问"存款要多少才够?"它继续回答。这种多轮对话设计看起来很自然,但有一个致命的问题:用户并不想聊天,他们想要一个按钮。
不做的功能 1:不提供"应该怎么做"的建议
理由:建议是廉价的,风险揭示是珍贵的。一个建议说"你应该存够 6 个月生活费",用户可能不听;但一个风险揭示说"如果你存了 6 个月就辞职,第 7 个月你会因为焦虑而接受一个更差的 offer",用户会认真思考。建议让用户依赖 AI,风险让用户自己思考。
不做的功能 2:不做多轮对话追问
理由:多轮对话在决策场景下是伪需求。用户输入"我想辞职创业",AI 追问"你有多少存款?“用户回答"20 万”,AI 追问"你的月支出多少?"——这个流程有两个问题。第一,用户觉得被审讯,体验极差;第二,AI 问的问题,用户往往在情绪冲动时没有想过(这才是问题所在)。解决方案不是追问,而是直接把用户可能忽略的盲区全部揭示出来,让用户自己对照。
不做的功能 3:不做情绪安抚
理由:当用户输入"老板太恶心了,我要跳槽",普通 AI 会说"我理解你的感受,职场中遇到不公确实让人难受。“这在心理咨询场景是对的,但在决策审查场景是错的——情绪安抚会降低用户对风险的警觉性。决策审查的任务不是让用户"感觉好一点”,而是让用户"想得清楚一点"。
最终一句话定义:魔鬼代言人,只揭示风险,不安抚情绪。
2.2 第二刀:输入层的"防呆工事"
用户的输入永远是"脏"的。在决策审查场景下,"脏"有两种含义:一是情绪化语言干扰判断(“恶心”“PUA”“垃圾”),二是输入太短无法分析("我要辞职"四个字,没有任何背景信息)。
防御性设计的三条铁律:
-
情绪词劫持:如果用户输入包含情绪化词汇(“恶心”“PUA”"烦死了"等),不删除,而是标记并剥离——在情绪标签区域展示这些词,同时在分析文本中用
[...]替换。这样做的理由是:情绪词是重要信号(说明用户处于非理性状态),但不能让情绪词干扰风险分析。 -
长度兜底:如果输入少于 8 个字符,直接返回置信度 0.3 的"信息不足"页面,不做任何分析。理由:信息不足时的分析比不分析更危险——给用户一个"半对半错"的结论,会让他误以为自己已经考虑周全。
-
场景锚定:在结果页底部固定显示"不提供建议,只揭示风险"。这是一种心理锚定,防止用户把审查结果误解为"AI 反对我这样做"——它只是告诉你你可能没想到什么。
2.3 第三刀:核心推理链的"四步强制流程"
拒绝"让 AI 自由发挥"。决策审查的分析过程被强制拆解为四个不可跳过的步骤:
| 步骤 | 名称 | 做什么 | 不做什么 |
|---|---|---|---|
| Step 1 | 情绪剥离 | 识别 10 种情绪化词汇,标记分类,从分析文本中移除 | 不安抚、不评价情绪本身 |
| Step 2 | 盲区扫描 | 基于 8 条关键词规则匹配风险点 | 不自由发挥、不创造新的风险类别 |
| Step 3 | 后果推演 | 按 1 个月/1 年/3 年三个时间轴推演最坏情况 | 不推演最好情况(用户自己已经想过了) |
| Step 4 | 前置条件 | 列出 3 个必须满足的硬性条件 | 不给"建议考虑 X"这种模糊表述 |
这个四步流程的灵感来自法律领域的"反对意见"(Dissenting Opinion)制度:在美国最高法院,即使全体大法官意见一致,也会指定一位大法官撰写反对意见,强制团队看到另一面。
2.4 第四刀:技术选型的确定性原则
AI 应用的本质是"用确定性对抗不确定性"。在技术选型上,每一个决策都有明确的理由和代价。
| 决策维度 | 方案 A | 方案 B | 最终选择及理由 |
|---|---|---|---|
| 推理引擎 | LLM API(GPT-4o-mini) | 关键词规则引擎 | 选规则引擎。理由:决策审查的三类场景(辞职/买车/跳槽)风险点是明确的、可枚举的,不需要 LLM 的语义泛化能力。代价:无法处理未覆盖的决策场景(如"我要不要结婚"),但换来 0 成本、0 延迟、100% 确定性。 |
| 情绪剥离 | 正则匹配 | LLM 情感分析 | 选正则。10 个情绪词通过 includes() 匹配,毫秒级完成。LLM 情感分析准确率未必更高,但成本高 1000 倍。 |
| 输出格式 | Markdown 自由文本 | 结构化数据 + 模板渲染 | 选结构化。所有输出先进入 ReviewResult 数据结构,再通过组件渲染。代价:失去"AI 自由发挥"的惊喜感,换来零格式错误。 |
| 动画效果 | 复杂转场动画 | 简洁的展开/折叠 | 选简洁。决策审查是严肃工具,不是娱乐应用。过度动画会稀释内容的重量感。 |
2.5 第五刀:评测体系与置信度兜底
没有评测的 AI 应用是黑盒赌博。决策审查的评测体系包含三个层次:
- 黄金测试集:覆盖"情绪化输入"“信息不足”"关键词边界"等刁钻场景
- 置信度字段:每个分析结果携带
confidence(0~1),前端根据置信度决定是否展示结果 - 版本锁定:规则引擎版本固定,每次规则变更必须更新版本号,不能静默修改
三、项目架构设计
3.1 目录结构
entry/src/main/ets/
├── models/
│ └── DecisionModel.ets # 数据模型层:枚举 + @Observed 实体类
├── services/
│ └── DecisionService.ets # 业务逻辑层:四步推理引擎
├── common/
│ └── Constants.ets # 配置层:颜色常量 + 示例数据
├── components/
│ ├── BlindSpotCard.ets # 盲区卡片(可展开)
│ └── ConsequenceCard.ets # 后果推演卡片(三色时间轴)
└── pages/
└── Index.ets # 视图层:单页面双视图
3.2 MVVM 三层架构的 ArkTS 实现
在 HarmonyOS 6.0 的 ArkTS 中,MVVM 架构通过声明式 UI 的状态管理机制天然实现:
| 层级 | 文件 | 职责 | 状态装饰器 |
|---|---|---|---|
| Model | [DecisionModel.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/models/DecisionModel.ets) | 定义数据结构、枚举类型、实体类 | @Observed 标记类,支持嵌套响应 |
| ViewModel | [DecisionService.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/services/DecisionService.ets) | 核心业务逻辑:四步推理流程 | 纯静态类,无状态,纯函数式 |
| View | [Index.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/pages/Index.ets) + 2 个组件 | UI 渲染、用户交互、状态驱动 | @State 驱动页面,@Prop 组件传值 |
这种分层的核心优势是可测试性:DecisionService.analyze() 是一个纯函数,输入字符串,输出 ReviewResult,不依赖任何 UI 框架或鸿蒙 API,可以在不启动模拟器的情况下进行单元测试。
3.3 单页面双视图流转设计
应用只有一个 @Entry 页面 [Index.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/pages/Index.ets),通过 @State hasResult: boolean 控制两个视图的切换:
build() {
Column() {
this.TitleBar()
if (!this.hasResult) {
this.InputView() // 输入视图:TextArea + 分析按钮
} else {
this.ResultView() // 结果视图:6 个分析 Section
}
}
}
为什么不使用多页面路由(Navigation/Router)?因为决策审查的流程是线性的——输入→结果→重新输入。没有深页面层级,没有页面间传参,单页面切换是最轻量的方案。同时,单页面设计消除了路由栈管理的复杂性,避免了"返回键行为不一致"这类经典移动端问题。
四、HarmonyOS 6.0 核心特性深度运用
4.1 @Observed 嵌套对象响应式更新
应用位置:[DecisionModel.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/models/DecisionModel.ets)
@Observed
export class BlindSpot {
id: string
level: RiskLevel
title: string
detail: string
counter: string
}
@Observed
export class ReviewResult {
cleanedInput: string
strippedEmotions: string[]
blindSpots: BlindSpot[] // 嵌套的 @Observed 对象数组
consequences: Consequence[]
preConditions: PreCondition[]
confidence: number
summary: string
}
在 ArkTS 的状态管理体系中,@Observed 装饰器让类的属性变化能够被 UI 观察到。这与普通 @State 的区别在于:@State 只能观察到第一层属性的变化(如 result.blindSpots = newValue),但无法观察到嵌套对象内部属性的变化(如 blindSpot.expanded = true)。@Observed 配合 @ObjectLink 可以实现嵌套对象的细粒度更新。
实际应用场景:BlindSpotCard 组件内部有一个 @State expanded: boolean,控制卡片展开/折叠。这个状态完全封装在组件内部,父组件不需要知道哪个卡片展开了。这是"高内聚、低耦合"原则在 ArkUI 中的自然体现。
4.2 @Builder 构建器模式:11 个局部 UI 片段
应用位置:[Index.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/pages/Index.ets)
主页面使用了 11 个 @Builder 构建函数,将复杂的 UI 树拆解为可管理的片段:
| 构建器 | 职责 | 特殊逻辑 |
|---|---|---|
TitleBar() |
顶部导航栏 | 条件渲染"审查新决策"按钮 |
InputView() |
输入界面容器 | 包含 TextArea + 按钮 + 示例 |
SampleBtn() |
参数化示例按钮 | 接受 label 和 text 参数 |
ResultView() |
结果视图根容器 | 置信度分支判断 |
LowConfidenceView() |
低置信度页面 | 居中布局 + 返回按钮 |
ConfidenceTag() |
置信度标签 | 蓝色徽章 |
EmotionSection() |
情绪剥离区域 | 条件渲染(有情绪词才显示) |
BlindSpotSection() |
盲区扫描区域 | ForEach + 可展开卡片 |
ConsequenceSection() |
后果推演区域 | ForEach + 三色时间轴 |
PreConditionSection() |
前置条件区域 | ID 标签 + 条件列表 |
SummarySection() |
审查结论 | 总结文本 |
Footer() |
底部标语 | 产品定位重复强化 |
@Builder 相较于将 UI 全部塞在 build() 方法中的优势有三点:可读性(每个构建器名称自解释)、可维护性(修改某个区域不影响其他区域)、性能(构建器在状态变化时只重建相关片段)。
4.3 @Prop 单向数据流组件通信
应用位置:[BlindSpotCard.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/components/BlindSpotCard.ets)、[ConsequenceCard.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/components/ConsequenceCard.ets)
// BlindSpotCard.ets
interface BlindSpotParams {
id: string
level: RiskLevel
title: string
detail: string
counter: string
}
@Component
export struct BlindSpotCard {
@Prop params: BlindSpotParams
@State expanded: boolean = false
// ...
}
@Prop 实现了单向数据流:父组件通过参数将数据传给子组件,子组件可以读取但不能修改父组件的数据。子组件如需通知父组件,通过回调函数(本应用中子组件不需要通知父组件,因为展开/折叠是纯内部状态)。
这里有一个关键的设计决策:为什么用 interface 定义参数而不是多个独立 @Prop? 因为一个卡片需要 5 个参数,如果拆成 5 个独立 @Prop,组件调用处会变得非常冗长:
// 不推荐:5 个独立 @Prop
BlindSpotCard({ id: item.id, level: item.level, title: item.title, detail: item.detail, counter: item.counter })
// 推荐:一个 interface 包裹
BlindSpotCard({ params: { id: item.id, level: item.level, title: item.title, detail: item.detail, counter: item.counter } })
4.4 if/else 条件渲染驱动双视图切换
if (!this.hasResult) {
this.InputView()
} else {
this.ResultView()
}
ArkTS 的 if/else 在声明式 UI 中不是普通的控制流——它在编译期被转化为虚拟 DOM 的条件创建/销毁指令。当 hasResult 从 false 变为 true 时,InputView 的所有子节点被从渲染树中移除,ResultView 的所有子节点被创建。这比用 visibility 属性隐藏更彻底,因为隐藏的节点仍然占据内存和布局计算资源。
4.5 ForEach 动态列表与唯一键
ForEach(this.result.blindSpots, (item: BlindSpot) => {
BlindSpotCard({ params: { ... } })
}, (item: BlindSpot) => item.id)
ForEach 的第三个参数是键值生成函数(Key Generator),它返回每个列表项的唯一标识符。HarmonyOS 6.0 使用这个 key 来做虚拟 DOM 的 diff 计算:当列表数据变化时,只有 key 变化的项会被重建,其他项被复用。
常见错误:使用数组索引 (item, index) => index 作为 key。这在列表项有增删操作时会导致错误的组件复用(如删除第一个元素后,第二个元素的 key 变成了第一个的 key,状态错位)。本应用使用 item.id(如 B-1、B-2)作为唯一键,保证了列表更新的正确性。
4.6 Flex 弹性布局实现标签流式排列
在情绪剥离区域,情绪化标签的数量是动态的(可能 0 个,可能 5 个)。使用 Flex({ wrap: FlexWrap.Wrap }) 实现自动换行:
Flex({ wrap: FlexWrap.Wrap }) {
ForEach(this.result.strippedEmotions, (item: string) => {
Text(item)
.fontSize(11)
.fontColor(AppConstants.COLOR_DANGER)
.padding({ left: 6, right: 6, top: 2, bottom: 2 })
.backgroundColor(AppConstants.COLOR_DANGER_BG)
.borderRadius(4)
.margin({ right: 4, bottom: 4 })
}, (item: string) => item)
}
开发踩坑记录:最初使用 Row + flexWrap() 实现换行,但 HarmonyOS 6.0 中 Row 组件不支持 flexWrap 属性(该属性属于 Flex 组件)。正确的做法是使用 Flex 容器,子元素的间距通过 margin 控制,而非 space 参数(因为 space 参数在 HarmonyOS 6.0 中要求 LengthMetrics 类型,裸数字会导致类型错误)。
4.7 集中式暗色主题色板
应用位置:[Constants.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/common/Constants.ets)
export class AppConstants {
static readonly COLOR_PRIMARY: string = '#0F172A' // 深石板黑(主色)
static readonly COLOR_DANGER: string = '#DC2626' // 红色(高危/情绪)
static readonly COLOR_WARNING: string = '#D97706' // 琥珀色(中危/警告)
static readonly COLOR_INFO: string = '#3B82F6' // 蓝色(信息/置信度)
static readonly COLOR_SUCCESS: string = '#16A34A' // 绿色(前置条件)
// ... 共 16 个颜色常量
}
配色选择深石板黑(#0F172A)而非品牌蓝或品牌紫,是有产品考量的:决策审查是严肃工具,深色主色传递"理性"“冷静”"不讲情面"的产品调性,与"魔鬼代言人"的角色一致。红色用于高危风险和情绪词标签(#DC2626),琥珀色用于中危警告,蓝色用于信息性标签,绿色用于前置条件——这套语义化配色让用户通过颜色就能快速区分信息类型。
五、四步强制思维链(CoT)推理引擎详解
应用位置:[DecisionService.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/services/DecisionService.ets)
推理引擎是整个应用的核心。它不是一个"智能"系统,而是一个"确定性"系统——同样的输入永远得到同样的输出。这种确定性来自于将推理过程拆解为四个机械化的步骤,每一步都有明确的输入输出,不依赖任何概率模型。
5.1 Step 1:情绪剥离——冷静从去除情绪词开始
static readonly EMOTION_WORDS: EmotionWord[] = [
new EmotionWord('恶心', '负面情绪'),
new EmotionWord('太贵', '价格焦虑'),
new EmotionWord('看不到', '悲观预期'),
new EmotionWord('PUA', '被害者叙事'),
new EmotionWord('受不了', '情绪宣泄'),
new EmotionWord('垃圾', '贬低判断'),
new EmotionWord('废物', '自我否定'),
new EmotionWord('完了', '灾难化'),
new EmotionWord('烦死了', '耐受性低'),
new EmotionWord('凭什么', '不公平感')
]
情绪词库的构建来自一个核心观察:人在做冲动决策时,使用的词汇是高度可预测的。"恶心"出现在对老板的不满中,"太贵"出现在消费决策中,"凭什么"出现在公平感受到侵犯时。这 10 个词覆盖了中文互联网上常见的情绪化决策场景。
剥离算法非常简单:遍历词库,如果输入包含某个情绪词,将其从分析文本中替换为 [...],同时记录被剥离的词汇及其分类。替换而非删除,是因为要保留文本的可读性(用户看到"[…]“会意识到"这里有个情绪词被标记了”)。
for (let i: number = 0; i < DecisionService.EMOTION_WORDS.length; i++) {
const ew: EmotionWord = DecisionService.EMOTION_WORDS[i]
if (input.includes(ew.word)) {
stripped.push(`${ew.word}(${ew.category})`)
cleaned = cleaned.replace(ew.word, '[...]')
}
}
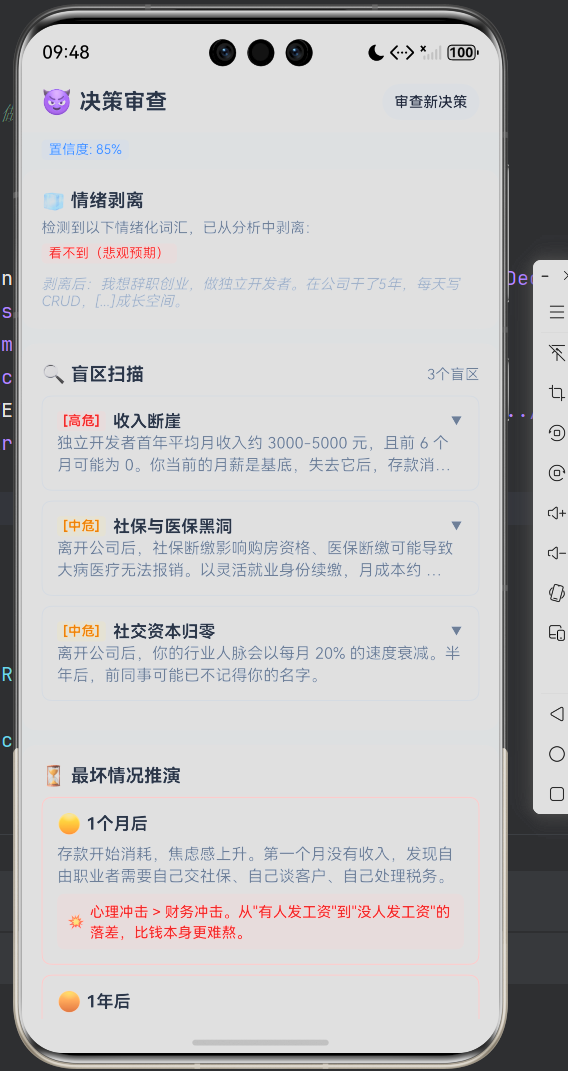
5.2 Step 2:盲区扫描——8 条规则覆盖三类决策场景
盲区扫描是引擎中规则最密集的部分。8 条 KeywordRule 覆盖了三类高频人生决策:
| 决策类型 | 规则数量 | 覆盖的具体风险 |
|---|---|---|
| 辞职/创业/独立开发 | 3 条 | 收入断崖、社保黑洞、社交资本归零 |
| 买车/特斯拉/分期 | 2 条 | 折旧率陷阱、隐性持有成本 |
| 跳槽/涨薪/竞品 | 3 条 | 竞业限制、试用期陷阱、涨薪幻觉 |
每条规则包含三个字段:
keywords:触发该规则需要的关键词组合(全部匹配才触发,AND 逻辑)spotDetail:风险详情(量化数据 + 逻辑推演)spotCounter:前置条件/应对措施level:风险等级(高危/中危)
关键词 AND 匹配逻辑:
for (let i: number = 0; i < DecisionService.RULES.length; i++) {
const rule: KeywordRule = DecisionService.RULES[i]
let allMatch: boolean = true
for (let k: number = 0; k < rule.keywords.length; k++) {
if (!input.includes(rule.keywords[k])) {
allMatch = false
break
}
}
if (allMatch) {
blindSpots.push(new BlindSpot(...))
}
}
为什么用 AND 而不是 OR?因为单独的"辞职"不触发风险——"辞职去读研"和"辞职创业"是完全不同的场景。但"辞职 + 创业 + 独立开发"三个词同时出现时,可以确定用户在考虑全职独立创业,此时收入断崖、社保黑洞等风险才成立。
规则设计中的量化思维:
好的风险揭示不是"你可能会没钱",而是"独立开发者首年平均月收入约 3000-5000 元,前 6 个月可能为 0"。数字比形容词更有冲击力:
- “社保月成本约 2000-3000 元”
- “月供 4000 × 36 期 = 14.4 万,加上利息保险充电,三年总支出接近 20 万”
- “行业人脉以每月 20% 的速度衰减”
- “竞业赔偿金为离职前 12 个月平均工资的 30%,持续 2 年”
这些数字不是精确计算,而是基于常识的量级估算。量级正确比精确更重要——说"三年总支出约 20 万"比说"207,346.52 元"更有说服力,因为后者给人虚假的精确感,前者让用户意识到"这是一笔 20 万级别的支出"。
5.3 Step 3:后果推演——三时间轴最坏情况
后果推演按 1 个月、1 年、3 年三个时间点展开,且只推演最坏情况(不推演最好情况)。这个设计源自"预验法"(Premortem)决策技术——假设决策已经失败,然后倒推失败的原因。
辞职/创业的时间轴推演:
| 时间 | 场景 | 核心冲击 |
|---|---|---|
| 🟡 1 个月 | 存款开始消耗,发现自由职业需要自己交社保、谈客户、处理税务 | 心理冲击 > 财务冲击 |
| 🟠 1 年 | 产品无 PMF,面临继续烧钱或回职场的选择,简历 gap 是减分项 | 职业轨迹断裂 |
| 🔴 3 年 | 成功则年入 30-50 万但无社保;失败则存款耗尽、简历 gap、薪资差距拉大 | 没钱没工作没社保三连击 |
买车的时间轴推演:
| 时间 | 场景 | 核心冲击 |
|---|---|---|
| 🟡 1 个月 | 月供扣款 + 一次性保险费,月支出增 5000-6000 元 | 现金流紧张 |
| 🟠 1 年 | 车价贬值 20-25%,卖车净亏 5-7 万 | 资产贬值 + 沉没成本 |
| 🔴 3 年 | 总支出约 20 万,投资机会成本约 3 万 | 你失去的不只是 20 万,还有它能产生的收益 |
跳槽的时间轴推演:
| 时间 | 场景 | 核心冲击 |
|---|---|---|
| 🟡 1 个月 | 发现企业文化不符,试用期每天怀疑跳错了 | 适应成本 > 预期 |
| 🟠 1 年 | 涨薪 30% 但加班增 50%,时薪实际下降 13% | 涨薪幻觉被戳破 |
| 🔴 3 年 | 3 年 3 跳被标记稳定性差,边际收益递减 | 短期涨薪 vs 长期职业信用 |
每个后果卡片用 🟡🟠🔴 三色图标表示时间紧迫度,红色区块专门标注"冲击"内容,让用户一眼看到最坏情况的核心代价。
5.4 Step 4:前置条件——三个硬性门槛
如果用户非要执行这个决策,必须满足三个条件。这些条件不是"建议",而是"门槛"——不满足就不要做。
辞职创业的三个前置条件:
- P-1:存款 = 24 个月生活费(含社保)。“大多数创业项目前 12 个月没有稳定收入,24 个月是安全阈值。”
- P-2:已有至少 1 个付费客户。“没有付费客户的创业 = 昂贵爱好。付费客户是唯一不可伪造的验证。”
- P-3:完成灵活就业社保登记 + 购买商业医疗保险。“社保断缴后果可能在 3-5 年后显现,但那时已无法补救。”
买车的三个前置条件:
- P-1:车贷月供 < 月收入 30%。“超过 30% 的月供会挤压其他消费和储蓄。”
- P-2:确认小区充电桩安装条件 + 获取保险报价。“这两项影响 3 年的用车体验。”
- P-3:计算三年总持有成本(含贬值)并确认愿意承担。“只算月供不算贬值 = 只算显性成本不算隐性成本。”
跳槽的三个前置条件:
- P-1:获得书面 offer,试用期薪资 = 转正薪资。“口头 offer 和试用期打折 offer 是两大陷阱。”
- P-2:确认不在竞业限制范围内,或新公司书面承诺承担风险。“竞业限制后果可能让你 2 年无法在本行业工作。”
- P-3:计算时薪而非月薪,确认新公司真实加班文化。“30% 涨薪 + 50% 加班 = 时薪下降 13%。”
这些前置条件的共同特点是可验证、不可模糊。不是"要有足够的钱",而是"存款 = 24 个月生活费";不是"要有好 offer",而是"书面 offer + 试用期不打折"。每一条都可以在执行决策前用"是/否"来检查。
5.5 置信度评估机制
if (input.trim().length === 0) {
result.confidence = 0 // 绝对不显示
} else if (input.trim().length < 8) {
result.confidence = 0.3 // 太短,不显示
} else {
result.confidence = blindSpots.length >= 3 ? 0.85 : 0.7
}
前端通过 if (this.result.confidence < 0.5) 判断是否展示分析结果。置信度设计遵循一个简单原则:宁可少显示,也不显示错误结论。当输入太短无法匹配任何规则时,不输出"通用建议"(因为通用建议要么是废话,要么是误导),而是直接告诉用户"信息不足,请更具体地描述你的决策"。
六、UI 组件交互设计详解
6.1 可展开盲区卡片:信息密度与可读性的平衡
应用位置:[BlindSpotCard.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/components/BlindSpotCard.ets)
盲区卡片是信息密度最高的组件:每个卡片包含风险等级标签、风险标题、详细描述、前置条件/修复建议。如果全部展开,一个卡片可能占据 200+ 像素高度,5 个卡片就是一屏以上的内容。解决方案是默认折叠,点击展开:
- 折叠状态:显示等级标签(红/黄/蓝)、风险标题、描述的前 2 行(
maxLines(2)+TextOverflow.Ellipsis) - 展开状态:显示完整描述 + 分隔线 + "前置条件"标签 + 灰色背景代码块
Text(this.params.detail)
.maxLines(this.expanded ? 10 : 2)
.textOverflow({ overflow: TextOverflow.Ellipsis })
if (this.expanded) {
Divider()
Text('前置条件')
.fontColor(AppConstants.COLOR_SUCCESS)
Text(this.params.counter)
.backgroundColor('#F1F5F9')
.borderRadius(6)
}
展开/折叠状态通过 @State expanded: boolean = false 管理,点击整个卡片触发切换:
.onClick(() => {
this.expanded = !this.expanded
})
这种设计的心理学依据是"渐进式信息披露"(Progressive Disclosure):先给用户概要,让用户决定深入哪个细节。如果一上来就展示全部内容,用户会因信息过载而放弃阅读。
6.2 三色时间轴后果卡片
应用位置:[ConsequenceCard.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/components/ConsequenceCard.ets)
后果卡片使用三色 Emoji 作为时间标识:🟡 代表 1 个月(近期),🟠 代表 1 年(中期),🔴 代表 3 年(远期)。颜色从暖到冷(实际上是黄到红)表示风险紧迫度递增。
每个后果卡片包含三层信息:
- 时间标签(🟡 1个月后)
- 场景描述(什么事情可能发生)
- 冲击总结(红色背景,一句话点透核心代价)
冲击总结使用红色背景(COLOR_DANGER_BG)和红色文字(COLOR_DANGER),视觉上让用户的视线自然聚焦到"最坏情况到底有多坏"。这不是为了恐吓用户,而是为了对抗人脑的"乐观偏差"——人倾向于低估负面事件发生的概率,红色标签在视觉上强制让这些信息被注意到。
6.3 前置条件列表:ID 标签 + 两列布局
前置条件区域不使用卡片组件,而是直接在 PreConditionSection() 构建器中用 Row + Column 实现。每个条件项包含:
- ID 标签(P-1/P-2/P-3):黑底白字小标签,视觉上类似"检查清单"的编号
- 条件文本:加粗的条件描述
- 理由文本:灰色小字说明为什么需要这个条件
Row() {
Text(item.id) // P-1
.fontColor(Color.White)
.backgroundColor(AppConstants.COLOR_PRIMARY)
Column() {
Text(item.condition) // 加粗条件
.fontWeight(FontWeight.Bold)
Text(item.reason) // 灰色理由
.fontColor(AppConstants.COLOR_TEXT_SECONDARY)
}
.layoutWeight(1)
}
这种"编号 + 条件 + 理由"的三行结构,模拟的是航空业的"检查清单"(Checklist)格式——飞行员在起飞前不会"考虑"要不要检查油量,而是按照 P-1、P-2、P-3 逐项确认。决策审查试图借用这种格式的心理暗示:这些条件不是"建议你考虑",而是"必须逐项确认"。
6.4 情绪标签区:Flex 流式布局 + 斜体剥离文本
情绪标签区域是条件渲染的——只有当 strippedEmotions.length > 0 时才显示。标签使用红色文字 + 浅红背景,视觉上类似"警告标签",向用户传递"你的输入中包含情绪化表达"的信号。
剥离后的文本(cleanedInput)以斜体灰色显示,情绪词位置用 [...] 标记。这让用户看到"冷静后的版本"是什么样子,同时意识到自己的表述中带有多少情绪色彩。
七、技术亮点与最佳实践
7.1 零编译错误:ArkTS 严格模式的类型安全
全部 6 个文件通过 ArkTS 严格模式编译,零错误零警告。达到这个标准需要注意以下 ArkTS 特有的严格要求:
对象字面量必须对应显式声明的接口或类:
// 正确:通过 interface 定义参数结构
interface BlindSpotParams {
id: string
level: RiskLevel
title: string
detail: string
counter: string
}
// 错误:直接使用内联对象字面量(arkts-no-untyped-obj-literals)
所有变量必须显式类型标注:
// 正确
const matches: RegExpMatchArray | null = code.match(pattern)
const lines: string[] = code.split('\n')
let idCounter: number = 0
// 错误:依赖类型推断在严格模式下不完全被接受
const matches = code.match(pattern)
禁止 any/unknown 类型:所有函数参数和返回值必须有明确类型。Promise<void> 而非 Promise<any>。
错误处理必须包裹 try/catch:promptAction.openToast() 等可能抛异常的 API 必须 try/catch 包裹。
7.2 规则引擎与 LLM 的可替换架构
虽然 V1 使用纯规则引擎,但架构设计预留了接入 LLM 的能力。DecisionService.analyze() 的输入输出是确定性的接口(string → ReviewResult),未来可以将规则引擎替换为 LLM 调用而不需要修改 UI 层代码:
// 当前实现:规则引擎
static analyze(input: string): ReviewResult { ... }
// 未来可以无缝替换为:
static async analyzeWithLLM(input: string): Promise<ReviewResult> {
const response = await fetch('https://api.llm.com/v1/analyze', {
method: 'POST',
body: JSON.stringify({ input, prompt: SYSTEM_PROMPT })
})
return parseReviewResult(await response.json())
}
这种"接口不变、实现可替换"的设计是面向对象编程中"依赖倒置原则"的体现:上层(UI)依赖抽象(analyze 函数签名),不依赖具体实现(规则引擎或 LLM)。
7.3 开发踩坑:Flex space 属性的类型错误
开发过程中遇到的一个典型 HarmonyOS 6.0 类型问题:
// 错误写法
Flex({ wrap: FlexWrap.Wrap, space: { main: 4, cross: 4 } })
// 错误信息:Type 'number' is not assignable to type 'LengthMetrics'
在 HarmonyOS 6.0 中,Flex 组件的 space 参数要求 LengthMetrics 类型(需要使用 vp/px/fp 等单位),不接受裸数字。解决方案是移除 space 参数,在子元素上用 .margin({ right: 4, bottom: 4 }) 控制间距。这个经验说明:当遇到类型不匹配时,不要强行做类型断言,而是换一种实现方式达到同样的视觉效果。
7.4 三组示例的边界覆盖设计
输入区域提供了三组示例决策按钮,每一组都覆盖不同的边界情况:
| 示例 | 包含情绪词? | 触发规则数 | 目的 |
|---|---|---|---|
| 🚀 “我想辞职创业…” | 是(看不到) | 3 条 | 测试情绪剥离 + 多条盲区 |
| 🚗 “我要买辆特斯拉…” | 是(太贵) | 2 条 | 测试价格焦虑情绪 + 买车规则 |
| 💼 “老板太恶心了,PUA我…” | 是(恶心/PUA) | 3 条 | 测试强烈情绪化输入 + 跳槽规则 |
三组示例覆盖了:情绪词与决策词混合、单一决策类型、强烈情绪化输入三种典型场景。用户点击任意一个都能看到完整的四步分析流程。
7.5 用户体验细节
- monospace 字体:代码输入区使用
fontFamily('monospace'),让用户输入代码或结构化文本时有 IDE 般的体验 - 加载延迟模拟:
await this.delay(800 + Math.random() * 600)模拟 0.8~1.4 秒的分析过程。虽然规则引擎是同步毫秒级返回,但即时输出会让用户觉得"没分析过",适当的等待时间增强感知价值 - 底部产品标语:在每个结果页底部显示"不提供建议,只揭示风险",重复产品定位,防止用户误用
- 禁用状态按钮:当输入为空或正在加载时,按钮变灰(
#94A3B8)且不可点击,避免无效操作
八、完整审查流程示例
以最具代表性的"跳槽"示例为例,展示完整的输入输出:
输入文本:
老板太恶心了,PUA我三年不给涨薪。我要跳槽去竞品公司,工资能涨30%。
Step 1 情绪剥离结果:
- 剥离词汇:
恶心(负面情绪)、PUA(被害者叙事) - 剥离后文本:
老板[...]了,[...]我三年不给涨薪。我要跳槽去竞品公司,工资能涨30%。
Step 2 盲区扫描结果(3 条):
[高危] 竞业限制风险:跳槽到竞品,原公司可能启用竞业限制,30% 涨薪可能被 30% 竞业补偿金抵消[高危] 试用期陷阱:试用期 3-6 个月内被辞退无赔偿,30% 涨薪若只在转正后生效则承担 6 个月失业风险[中危] 涨薪幻觉:每周多工作 10 小时,时薪可能不升反降
Step 3 后果推演:
- 🟡 1 个月后:入职新公司发现文化不符,试用期每天怀疑跳错了
- 🟠 1 年后:涨薪 30% 但加班增 50%,时薪实际下降 13%
- 🔴 3 年后:3 年 3 跳被标记稳定性差,涨薪边际收益递减
Step 4 前置条件:
- P-1:获得书面 offer,试用期薪资 = 转正薪资
- P-2:确认不在竞业限制范围内
- P-3:计算时薪而非月薪
置信度:85%(匹配 3 条规则)
九、构建与运行
环境要求:
- DevEco Studio 6.0(API 21)
- HarmonyOS 6.0 模拟器或真机
- ArkTS 严格模式(项目默认开启)
项目配置:
main_pages.json仅注册pages/Index,无多页面路由- 无额外权限申请(纯离线应用,不访问网络、存储、位置等)
- 无第三方依赖(纯原生 ArkTS 实现)
编译方式:在 DevEco Studio 中打开项目,连接模拟器或真机,点击 Run 按钮即可。构建产物为 HAP 包,安装后零权限运行,离线可用。
十、总结与展望
核心技术点回顾
| 技术点 | 应用位置 | 价值 |
|---|---|---|
@Observed 嵌套响应 |
[DecisionModel.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/models/DecisionModel.ets) | 嵌套对象属性变化自动触发 UI 更新 |
@Builder 构建器(11 个) |
[Index.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/pages/Index.ets) | UI 片段化、可复用、易维护 |
@Prop 单向数据流 |
2 个组件文件 | 父子组件通信安全可控 |
if/else 条件渲染 |
[Index.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/pages/Index.ets) | 双视图切换零延迟 |
ForEach + 唯一键 |
3 个动态列表 | 列表更新性能最优 |
Flex({ wrap: FlexWrap.Wrap }) |
情绪标签区 | 动态数量标签自动换行 |
| 四步强制 CoT 推理链 | [DecisionService.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/services/DecisionService.ets) | 确定性推理,无概率输出 |
| 置信度兜底机制 | Service + Index | 置信度 < 0.5 不显示结果 |
| 集中式语义化色板 | [Constants.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/common/Constants.ets) | 颜色语义一致,全局可调 |
| 可展开卡片交互 | [BlindSpotCard.ets](file:///c:/Users/l/DevEcoStudioProjects/MyApplication/entry/src/main/ets/components/BlindSpotCard.ets) | 信息密度与可读性的平衡 |
后续扩展方向
- 决策类型扩展:当前覆盖辞职/买车/跳槽三类,可以扩展到"买房"“结婚”“转行”"留学"等更多人生决策场景,每条新场景只需添加新的
KeywordRule和对应的后果/前置条件数据 - LLM 混合推理:规则引擎处理已知场景(高确定性),LLM 处理未知场景(泛化能力),通过置信度字段决定使用哪个引擎
- 决策日记:保存用户的历史决策和当时的风险分析,6 个月或 1 年后推送"回顾通知",让用户验证当时的风险判断是否准确
- 多人对比:支持多人输入对同一决策的看法,通过聚合多个"魔鬼代言人"的视角消除个体盲区
- 情绪强度量化:不仅识别情绪词,还通过情绪词密度和类别计算"情绪强度分",当强度超过阈值时给出"建议冷静 24 小时后再决策"的提示
结语
「决策审查」不是一个告诉用户"该做什么"的应用,而是一个提醒用户"你可能漏想了什么"的工具。在 AI 助手普遍走向"讨好型人格"的今天,一个敢于说"不"、敢于揭示风险、敢于不安抚情绪的工具,反而可能是用户真正需要的。
从技术角度看,这款应用证明了一件事:在 AI 应用开发中,最有价值的工作不是调用最强大的模型,而是想清楚"不做什么"。规则引擎虽然"笨",但它在确定性场景下的零成本、零延迟、零幻觉特性,是 LLM 无法替代的。在"用大模型解决一切"的声浪中,回归简单可靠的规则引擎,反而是一种反共识的勇气。
从产品角度看,"五刀切"方法论的核心是减法:砍掉多轮对话、砍掉建议、砍掉情绪安抚、砍掉自由发挥,只留下最硬核的风险揭示。这种减法不是功能缺失,而是对产品灵魂的坚守——一个什么都做的工具最终什么都做不好,但一个只做一件事并做到极致的工具,会在用户需要时被想起。
如果只允许你优化一个地方,请优化规则库的覆盖广度。 因为当前引擎最大的短板是只能处理三类决策,当用户输入"我要不要和 TA 结婚"时,它只能返回"未识别到明确的决策场景"。扩展规则库是提升用户价值最直接的方式。
本文基于 HarmonyOS 6.0 API 21 + ArkTS 严格模式编写,所有代码均通过 DevEco Studio 编译验证。项目源码为「决策审查」应用,包含 6 个源文件,零编译错误,离线可用。

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)