Python 利用随机森林算法对缺失值填补
关注微信公共号:小程在线关注CSDN博客:程志伟的博客导入需要的库import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.datasets import load_bostonfrom sklearn.impute import SimpleImputerfrom s...
关注微信公共号:小程在线

关注CSDN博客:程志伟的博客
导入需要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
以波士顿数据集为例,导入完整的数据集并探索
dataset = load_boston()
dataset.data.shape
Out[21]: (506, 13)
dataset.target
Out[22]:
array([24. , 21.6, 34.7, 33.4, 36.2, 28.7, 22.9, 27.1, 16.5, 18.9, 15. ,
18.9, 21.7, 20.4, 18.2, 19.9, 23.1, 17.5, 20.2, 18.2, 13.6, 19.6,
......
29.8, 13.8, 13.3, 16.7, 12. , 14.6, 21.4, 23. , 23.7, 25. , 21.8,
20.6, 21.2, 19.1, 20.6, 15.2, 7. , 8.1, 13.6, 20.1, 21.8, 24.5,
23.1, 19.7, 18.3, 21.2, 17.5, 16.8, 22.4, 20.6, 23.9, 22. , 11.9])
X_full, y_full = dataset.data, dataset.target
n_samples = X_full.shape[0]
n_features = X_full.shape[1]
为完整数据集放入缺失值
#首先确定我们希望放入的缺失数据的比例,在这里我们假设是50%,那总共就要有3289个数据缺
rng = np.random.RandomState(0)
missing_rate = 0.5
n_missing_samples = int(np.floor(n_samples * n_features * missing_rate))
#np.floor向下取整,返回.0格式的浮点数
#所有数据要随机遍布在数据集的各行各列当中,而一个缺失的数据会需要一个行索引和一个列索引
#如果能够创造一个数组,包含3289个分布在0~506中间的行索引,和3289个分布在0~13之间的列索引,那我们就可
#以利用索引来为数据中的任意3289个位置赋空值
#然后我们用0,均值和随机森林来填写这些缺失值,然后查看回归的结果如何
missing_features = rng.randint(0,n_features,n_missing_samples)
missing_samples = rng.randint(0,n_samples,n_missing_samples)
#missing_samples = rng.choice(dataset.data.shape[0],n_missing_samples,replace=False)
#我们现在采样了3289个数据,远远超过我们的样本量506,所以我们使用随机抽取的函数randint。但如果我们需要
的数据量小于我们的样本量506,那我们可以采用np.random.choice来抽样,choice会随机抽取不重复的随机数,
因此可以帮助我们让数据更加分散,确保数据不会集中在一些行中
X_missing = X_full.copy()
y_missing = y_full.copy()
X_missing[missing_samples,missing_features] = np.nan
X_missing[missing_samples,missing_features] = np.nan
X_missing = pd.DataFrame(X_missing)
#使用均值进行填补
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean')
X_missing_mean = imp_mean.fit_transform(X_missing)
#查看缺失值填补之后每列的缺失值个数
pd.DataFrame(X_missing_mean).isnull().sum()
Out[33]:
0 0
1 0
2 0
3 0
4 0
5 0
6 0
7 0
8 0
9 0
10 0
11 0
12 0
dtype: int64
#使用0进行填补
imp_0 = SimpleImputer(missing_values=np.nan, strategy="constant",fill_value=0)
X_missing_0 = imp_0.fit_transform(X_missing)
################使用随机森林回归填补缺失值#################
任何回归都是从特征矩阵中学习,然后求解连续型标签y的过程,之所以能够实现这个过程,是因为回归算法认为,特征矩阵和标签之前存在着某种联系。实际上,标签和特征是可以相互转换的,比如说,在一个“用地区,环境,附近学校数量”预测“房价”的问题中,我们既可以用“地区”,“环境”,“附近学校数量”的数据来预测“房价”,也可以反过来,用“环境”,“附近学校数量”和“房价”来预测“地区”。而回归填补缺失值,正是利用了这种思想。
对于一个有n个特征的数据来说,其中特征T有缺失值,我们就把特征T当作标签,其他的n-1个特征和原本的标签组成新的特征矩阵。那对于T来说,它没有缺失的部分,就是我们的Y_train,这部分数据既有标签也有特征,而它缺失的部分,只有特征没有标签,就是我们需要预测的部分。
特征T不缺失的值对应的其他n-1个特征 + 本来的标签:X_train
特征T不缺失的值:Y_train
特征T缺失的值对应的其他n-1个特征 + 本来的标签:X_test
特征T缺失的值:未知,我们需要预测的Y_test
这种做法,对于某一个特征大量缺失,其他特征却很完整的情况,非常适用。
那如果数据中除了特征T之外,其他特征也有缺失值怎么办?
答案是遍历所有的特征,从缺失最少的开始进行填补(因为填补缺失最少的特征所需要的准确信息最少)。填补一个特征时,先将其他特征的缺失值用0代替,每完成一次回归预测,就将预测值放到原本的特征矩阵中,再继续填补下一个特征。每一次填补完毕,有缺失值的特征会减少一个,所以每次循环后,需要用0来填补的特征就越来越少。当进行到最后一个特征时(这个特征应该是所有特征中缺失值最多的),已经没有任何的其他特征需要用0来进行填补了,而我们已经使用回归为其他特征填补了大量有效信息,可以用来填补缺失最多的特征。遍历所有的特征后,数据就完整,不再有缺失值了。
################以单列数据为例#####################
X_missing_reg = X_missing.copy()
#查看哪一列的缺失数据最少
np.argsort(X_missing_reg.isnull().sum(axis=0))
Out[36]:
0 6
1 12
2 8
3 7
4 9
5 0
6 2
7 1
8 5
9 4
10 3
11 10
12 11
dtype: int64
#找出缺失值从小到大的数据列
sortindex = np.argsort(X_missing_reg.isnull().sum(axis=0)).values
sortindex
Out[38]: array([ 6, 12, 8, 7, 9, 0, 2, 1, 5, 4, 3, 10, 11], dtype=int64)
#构建新的特征矩阵
df = X_missing_reg
fillc = df.iloc[:,6]
df = pd.concat([df.iloc[:,df.columns != 6],pd.DataFrame(y_full)],axis=1)
#在新特征矩阵中,对含有缺失值的列,进行0的填补
df_0 =SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(df)
#找出我们的训练集和测试集
#被选中的特征(现在是标签),存在的值,非空
Ytrain = fillc[fillc.notnull()]
#被选中的特征(现在是标签),存在的值,空值
#我们需要它的索引
Ytest = fillc[fillc.isnull()]
#非空值对应的记录
Xtrain = df_0[Ytrain.index,:]
#空值对应的记录
Xtest = df_0[Ytest.index,:]
#用随机森林回归来填补缺失值
rfc = RandomForestRegressor(n_estimators=100)
rfc = rfc.fit(Xtrain, Ytrain)
Ypredict = rfc.predict(Xtest)
#将填补好的特征返回到我们的原始的特征矩阵中
X_missing_reg.loc[X_missing_reg.iloc[:,6].isnull(),6] = Ypredict
#可以看出第6列的缺失值为0个
X_missing_reg.isnull().sum()
Out[49]:
0 200
1 201
2 200
3 203
4 202
5 201
6 0
7 197
8 196
9 197
10 204
11 214
12 189
dtype: int64
############以循环方式实现所有列的填补#############
X_missing_reg = X_missing.copy()
sortindex = np.argsort(X_missing_reg.isnull().sum(axis=0)).values
for i in sortindex:
#构建我们的新特征矩阵和新标签
df = X_missing_reg
fillc = df.iloc[:,i]
df = pd.concat([df.iloc[:,df.columns != i],pd.DataFrame(y_full)],axis=1)
#在新特征矩阵中,对含有缺失值的列,进行0的填补
df_0 =SimpleImputer(missing_values=np.nan,
strategy='constant',fill_value=0).fit_transform(df)
#找出我们的训练集和测试集
Ytrain = fillc[fillc.notnull()]
Ytest = fillc[fillc.isnull()]
Xtrain = df_0[Ytrain.index,:]
Xtest = df_0[Ytest.index,:]
#用随机森林回归来填补缺失值
rfc = RandomForestRegressor(n_estimators=100)
rfc = rfc.fit(Xtrain, Ytrain)
Ypredict = rfc.predict(Xtest)
#将填补好的特征返回到我们的原始的特征矩阵中
X_missing_reg.loc[X_missing_reg.iloc[:,i].isnull(),i] = Ypredict
#所有列的缺失值填补完整
X_missing_reg.isnull().sum()
Out[55]:
0 0
1 0
2 0
3 0
4 0
5 0
6 0
7 0
8 0
9 0
10 0
11 0
12 0
dtype: int64
#对所有数据进行建模,取得MSE结果
X = [X_full,X_missing_mean,X_missing_0,X_missing_reg]
mse = []
for x in X:
estimator = RandomForestRegressor(random_state=0, n_estimators=100)
scores = cross_val_score(estimator,x,y_full,scoring='neg_mean_squared_error',cv=5).mean()
mse.append(scores * -1)
mse
Out[57]: [21.62860460743544, 40.84405476955929, 49.50657028893417, 20.419623572956702]
#用所得结果画出条形图
x_labels = ['Full data',
'Mean Imputation',
'Zero Imputation',
'Regressor Imputation']
colors = ['r', 'g', 'b', 'orange']
plt.figure(figsize=(12, 6))
ax = plt.subplot(111) #添加子图
for i in np.arange(len(mse)):
ax.barh(i, mse[i],color=colors[i], alpha=0.6, align='center')
ax.set_title('Imputation Techniques with Boston Data')
ax.set_xlim(left=np.min(mse) * 0.9,right=np.max(mse) * 1.1)
ax.set_yticks(np.arange(len(mse)))
ax.set_xlabel('MSE')
ax.invert_yaxis()
ax.set_yticklabels(x_labels)
plt.show()
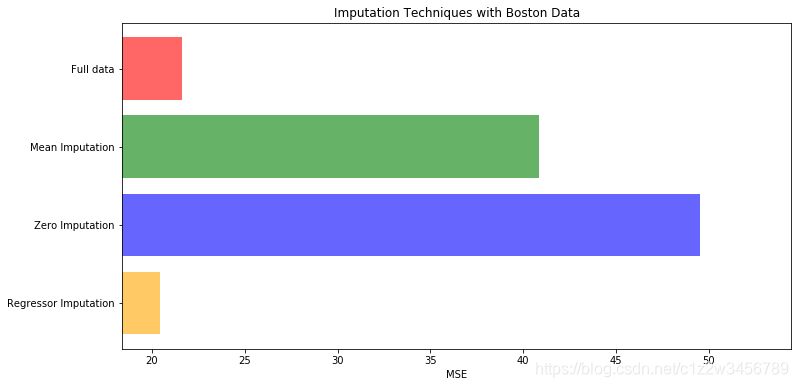
从上图可以看出使用随机森林对缺失值进行填补甚至优于原始数据集的结果

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)