频率/频域信息(小波、DCT、FFT) 与 图像细节处理
文章目录
- 小波变换与python
- 频域操作参考方法
-
- 傅里叶变换
-
- Global Modeling Matters: A Fast, Lightweight and Effective Baseline for Efficient Image Restoration(小波+傅里叶)
- Fourier Convolution Block with global receptive field for MRI reconstruction(傅里叶卷积模块)
- Frequency-Guided Spatial Adaptation for Camouflaged Object Detection
- DiffFNO: Diffusion Fourier Neural Operator(加权傅里叶神经算子)
- Efficient Frequency-Domain Image Deraining with Contrastive Regularization(FFT,频率域对比损失函数)
- Improving Representation of High-Frequency Components for Medical Visual Foundation Models(傅里叶变换构建高频掩码)
- Learning Frequency-Domain Fusion for Multimodal Remote Sensing Semantic Segmentation
- DCT
-
- Mesoscopic Insights: Orchestrating Multi-scale & Hybrid Architecture for Image Manipulation Localization
- HS-FPN: High Frequency and Spatial Perception FPN for Tiny Object Detection(双路DCT高通滤波+注意力)
- FSTA-SNN:Frequency-Based Spatial-Temporal Attention Module for Spiking Neural Networks(自适应频率选择+时间空间双注意力,既轻量又涨点)
- ADCD-Net: Robust Document Image Forgery Localization viaAdaptive DCT Feature and Hierarchical Content Disentanglement(自适应离散余弦变换进行伪造检测)
- M2TR: multi-modal multi-scale transformers for deepfake detection (多模多尺度)
- 小波变换
-
- mamba与小波变换参见“[超链接](https://editor.csdn.net/md?not_checkout=1&spm=1011.2124.3001.6217&articleId=156123219)”
- ASCNet: Asymmetric Sampling Correction Network for Infrared Image Destriping(RHDWT残差离散小波变换下采样模块)
- WaMaIR: Image Restoration via Multiscale Wavelet Convolutions and Mamba-based Channel Modeling with Texture Enhancement
- Global Modeling Matters: A Fast, Lightweight and Effective Baseline for Efficient Image Restoration(小波+傅里叶+傅里叶域 L1 损失)
- ERIENet: An Efficient RAW Image Enhancement Network under Low-Light Environment(小波损失)
- TIR-Diffusion: Diffusion-based Thermal Infrared Image Denoising via Latent and Wavelet Domain Optimization(小波损失)
- Lightweight Local–Global Dual-Path Feature Fusion Network for Infrared Small Target Image Super-Resolution and Enhancement(一路DCT,一路小波+DCT)
- CWNet: Causal Wavelet Network for Low-Light Image Enhancement(小波卷积+傅里叶卷积+mamba)
- 频域(DCT,小波变换)与CNN结合
- 超分-wavelet
- [Invertible Image Rescaling 可逆图像缩放:完美恢复降采样后的高清图片(ECCV 2020 Oral )](https://blog.csdn.net/nefetaria/article/details/108240985?utm_medium=distribute.pc_relevant.none-task-blog-title-1&spm=1001.2101.3001.4242)
- Wavelet Integrated CNNs for Noise-Robust Image Classification, CVPR2020
- [频域深度学习 Learning in the Frequency Domain](https://zhuanlan.zhihu.com/p/112751461)
- 图像细节处理
小波变换与python
【小波变换】小波变换python实现–PyWavelets
[Python]小波分析库Pywavelets的常用 API
[Python ]小波变化库——Pywavelets 学习笔记
多尺度几何分析(Ridgelet、Curvelet、Contourlet、Bandelet、Wedgelet、Beamlet)
小波包变换
于正交小波变换只对信号的低频(近似)信息做进一步分解,而对高频(细节)信息不再继续分解,使得它的频率分辨率随频率升高而降低。所以小波变换能够很好地表征一大类以低频信息为主要成分的信号,但它不能很好地分解和表示包含大量细节信息(细小边缘或纹理)的信号,如非平稳机械振动信号、遥感图象、地震信号和生物医学信号等。与之不同的是,小波包变换可以对高频部分提供更精细的分解,而且这种分解既无冗余,也无疏漏,所以对包含大量中、高频信息的信号能够进行更好的时频局部化分析。
频域操作参考方法
傅里叶变换
Global Modeling Matters: A Fast, Lightweight and Effective Baseline for Efficient Image Restoration(小波+傅里叶)
在小波部分已有阐述
Fourier Convolution Block with global receptive field for MRI reconstruction(傅里叶卷积模块)
论文题目: Fourier Convolution Block with global receptive field for MRI reconstruction
中文题目:《用于 MRI 重建的具有全局感受野的傅里叶卷积模块》
GitHub 项目地址链接:https://github.com/Haozhoong/FCB
在视觉建模领域,增强网络的全局表征能力已成为 CNN 与 Transformer 架构的共同追求。傅里叶变换在捕捉全局信息方面具有天然优势,但现有基于傅里叶的模型普遍存在结构复杂、训练不稳定或难以与局部建模有效协同的问题。
本研究的创新主要体现在以下几个方面:
(1)提出简洁高效的傅里叶卷积模块(Fourier Convolution Block, FCB)
设计了一种结构极为简洁的 FCB 模块,仅由一次快速傅里叶变换(FFT)、两层多层感知机(MLP)实现的频域加权、逆傅里叶变换(iFFT)以及输入残差相加构成。该模块无需复杂的通道划分、位置编码或额外的频域操作,训练稳定且易于集成。
(2)融合局部与全局表征能力
FCB 被嵌入到标准 CNN 框架中,与常规卷积层协同作用,使网络同时具备空域的精细局部建模能力与频域的全局建模能力。该模块具备较强的结构灵活性,可在网络的不同阶段插入,以增强模型对长程依赖关系的捕获能力。
Frequency-Guided Spatial Adaptation for Camouflaged Object Detection
源码:https://github.com/zugexiaodui/FGSA-Net
论文的主要工作为设计了一个频率引导的空间注意模块( frequency-guided spatial attention module),使预训练的基础模型由自适应调整的频率分量引导,更多地关注伪装区域。
整体框架: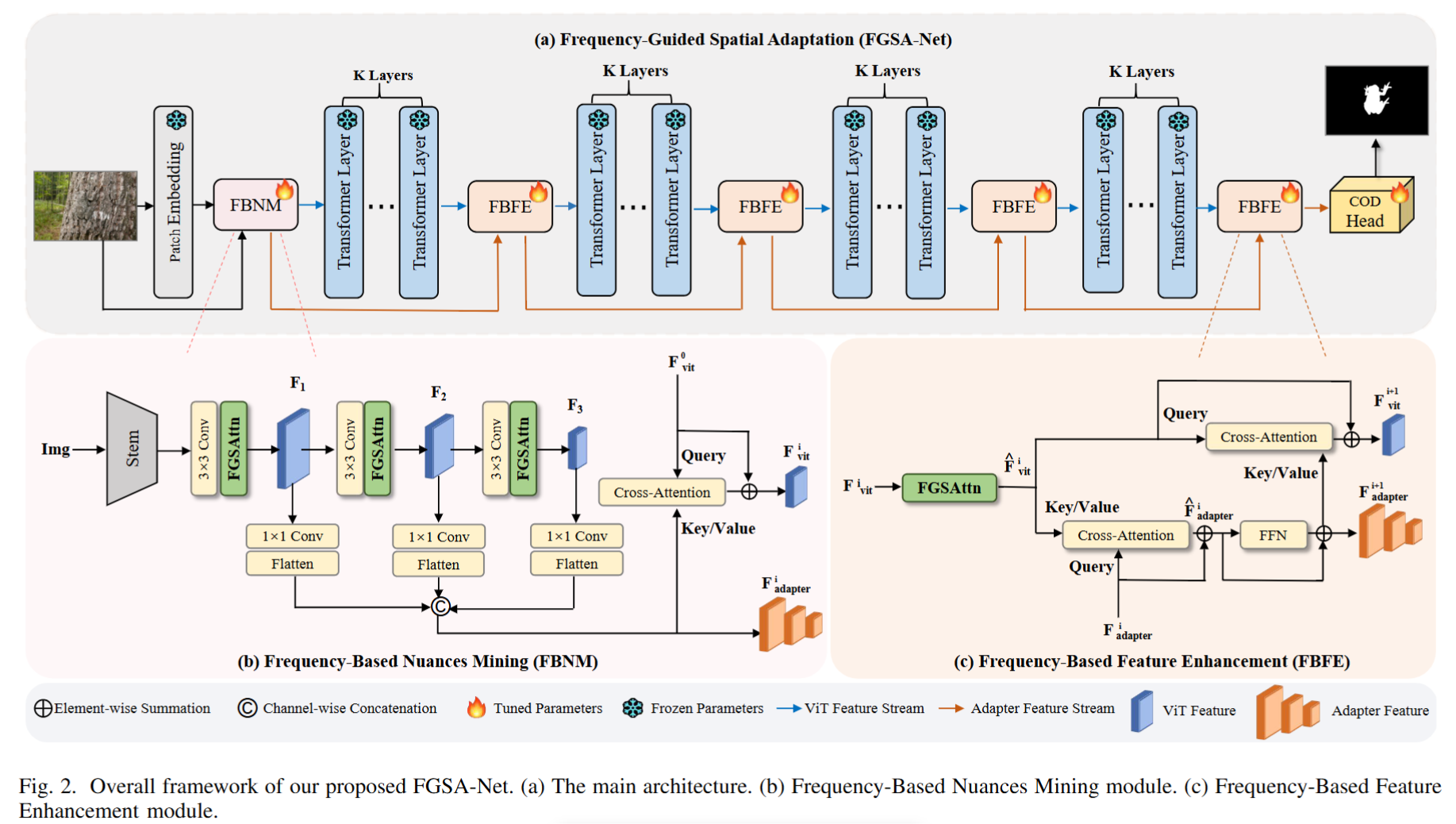
创新:频率引导的空间注意力(FGSAttn)
传统适配器仅关注空间域特征,而FGSA-Net的核心创新在于频域-空间域联合优化。具体流程如下:
- 频域分解:将空间特征通过FFT转换至频域,提取振幅谱(Amplitude Spectrum)和相位谱(Phase Spectrum)。
- 环形分组:在振幅谱上按半径划分非重叠圆环区域,每个区域代表不同频率成分(如低频轮廓、高频细节)。
- 动态增强:通过全局平均池化和全连接层生成权重,自适应增强关键频率成分,抑制噪声。
- 逆变换重构:将调整后的振幅谱与原始相位谱结合,经逆FFT生成空间注意力图,指导特征优化。
这一机制使模型能显式捕捉纹理差异,解决了空间域难以区分类似模式的问题。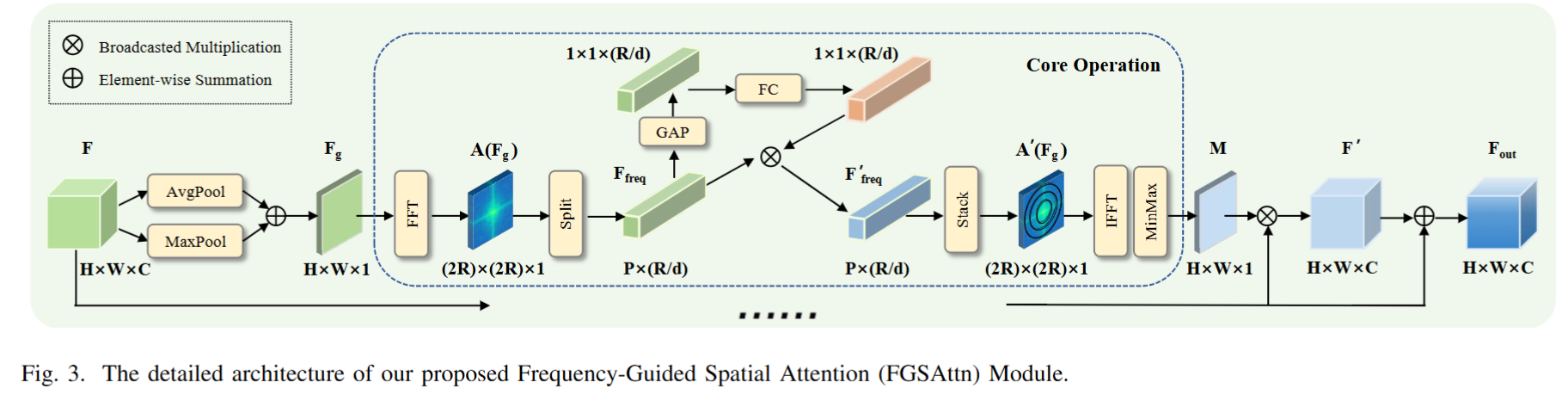
DiffFNO: Diffusion Fourier Neural Operator(加权傅里叶神经算子)
项目主页:https://jasonliu2024.github.io/difffno-diffusion-fourier-neural-operator/
网文:https://mp.weixin.qq.com/s/k5Q3IxyKia9AXZ0ohfzwIQ
DiffFNO 的核心思想是将加权傅里叶神经算子 (Weighted Fourier Neural Operator, WFNO) 强大的全局特征提取和分辨率无关性,与扩散模型 (Diffusion Model) 卓越的图像生成和细节迭代细化能力相结合 。它旨在解决现有方法在恢复图像高频细节方面的不足。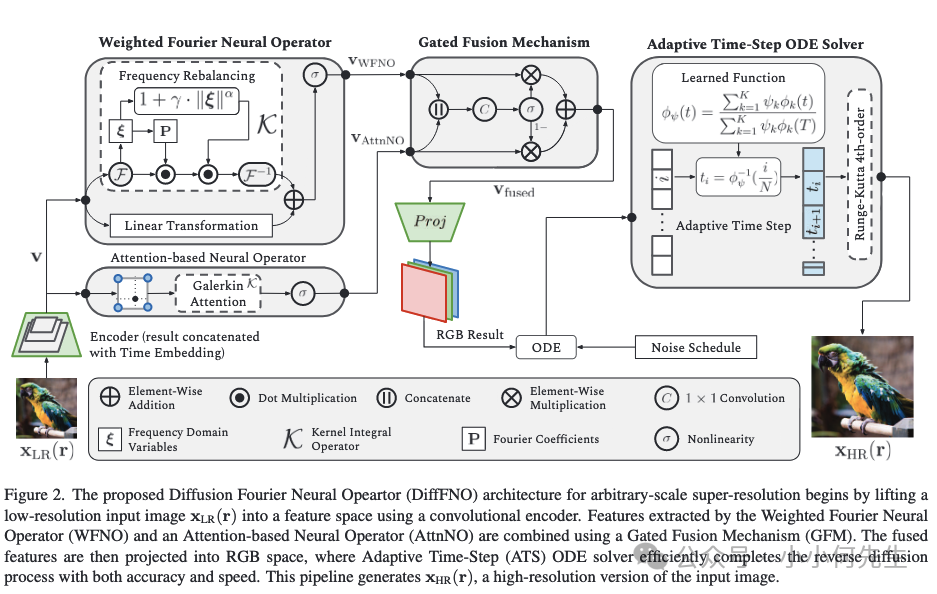
DiffFNO 采用了基于神经算子和扩散模型结合的混合架构。其实现细节可分为几个核心组件:
- A. 加权傅里叶神经算子 (WFNO) 与注意力神经算子 (AttnNO)
WFNO:WFNO 是标准傅里叶神经算子 (FNO) 的增强版。它引入了模式再平衡 (Mode Rebalancing, MR) 机制,通过一个可学习的加权函数来调制傅里叶模式的影响,尤其增强高频分量,从而克服了传统 FNO 模式截断导致的高频信息损失问题。
AttnNO:一个基于注意力机制的轻量级神经算子,与 WFNO 并行运行,用于在空间域捕捉互补的局部依赖关系和精细结构。 - B. 门控融合机制 (Gated Fusion Mechanism, GFM)
GFM 负责动态地融合来自 WFNO 的全局频谱特征和来自 AttnNO 的局部空间特征。
实现方式:它将两个特征图沿通道维度拼接,然后通过一个卷积层和 Sigmoid 激活函数生成一个门控图 。最终的融合特征图是两个特征图的加权和。
Efficient Frequency-Domain Image Deraining with Contrastive Regularization(FFT,频率域对比损失函数)
源码:https://github.com/deng-ai-lab/FADformer
论文:https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/05751.pdf
网文:https://blog.csdn.net/qq_43275608/article/details/144722662
文章提出了一个名为FADformer(Frequency-Aware Deraining Transformer Framework)的新框架,它通过在频域中捕捉特征来高效去除雨水。文章指出,现有的基于Transformer的方法在全局建模方面效率不高,并且在训练中要么忽视了负样本信息,要么没有充分利用负样本中的雨迹模式。
1 .提出 FADformer 框架
- 整体结构:为解决全局建模效率问题,构建了分层的 FADformer 框架,包含一系列不同尺度的 FADBlock,由融合傅里叶卷积混合器(FFCM)和先验门控前馈网络(PGFN)组成。
- FFCM:基于快速傅里叶卷积(FFC),通过空间 - 频率域的卷积操作融合多尺度空间特征,比 Transformer 中的自注意力机制更高效地提取全局信息。
- PGFN:引入残差通道先验(RCP)信息,以门控方式引导前馈网络增强局部细节和结构恢复能力。
- 频率域对比正则化(FCR):为解决对比样本利用不足的问题,提出 FCR,将图像编码到频率域,以地面真值为正样本、雨天图像为负样本、FADformer 输出的去雨图像为锚点,通过计算频率域特征的 L1 距离构建对比学习,有效提升去雨性能。(其训练目标通过损失函数实现:拉近锚点与正样本的频域特征距离,同时推远锚点与负样本的频域特征距离)
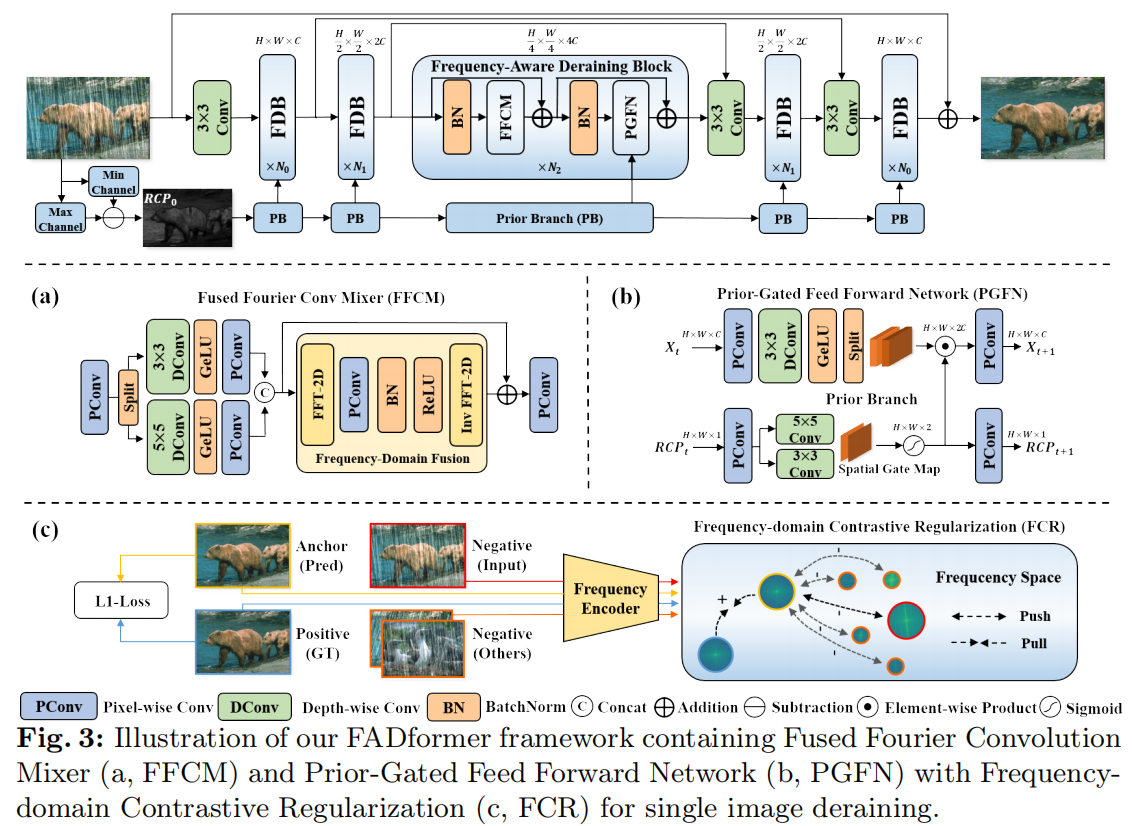
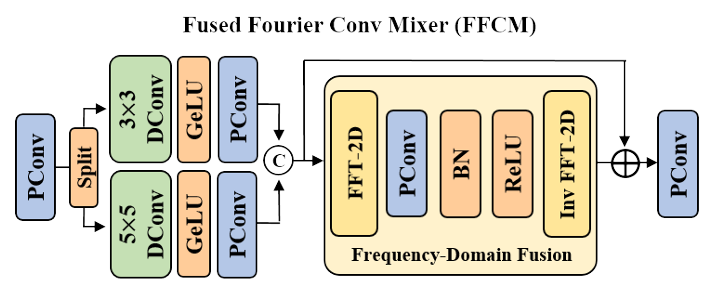
提出一种 融合傅里叶卷积混合器FFCM 通过融合空间域和频率域的特征,实现了高效的全局建模。此外,频率域特征能够自然地提取全局信息,而卷积操作则保证了局部信息的保留。
实现过程:
- 空间域操作:首先使用点卷积提升输入特征图的通道数,并将其分割为两组,分别进行不同尺寸的深度可分离卷积,提取多尺度局部特征。然后,将两组特征图进行拼接,得到空间域特征图。
- 频率域操作:对空间域特征图进行离散傅里叶变换,将其转换为频域。再对频域特征图进行卷积操作,并使用1x1卷积进行通道压缩。然后将压缩后的特征图进行拼接,并进行调制操作。最后将调制后的特征图进行反傅里叶变换,将其转换回空间域。
- 残差结构:将空间域特征图与频率域特征图进行残差连接,并使用点卷积进行通道压缩。最后得到输出特征图。
Improving Representation of High-Frequency Components for Medical Visual Foundation Models(傅里叶变换构建高频掩码)
源码:https://github.com/Arturia-Pendragon-Iris/Frepa
论文:https://arxiv.org/pdf/2407.14651
本论文旨在解决基础模型在医学图像处理中无法准确表示高频细节的问题,提出了一种新的自监督预训练策略Frepa,并在九种医学模态和32个下游任务中进行了验证。 Frepa通过高频掩蔽和低频扰动相结合的方法,利用对抗学习鼓励编码器有效地表示和保留图像嵌入中的高频细节,同时引入了直方图均衡化图像掩蔽策略。
- 高频域掩码在频率谱中随机掩码高频区域,迫使编码器利用剩余信息来重建被掩码的频率分量。
- 低频扰动对频谱的低频部分添加零均值噪声,防止编码器过度依赖容易学习的低频分量。
在技术实现上,Frepa首先将图像转换到频率域。这里用到了离散傅里叶变换。
掩码概率的计算采用了指数衰减函数,与频谱中心的欧几里得距离相关。这种设计确保了高频区域有更高的掩码概率,而低频区域的掩码概率较低,实现了对高频信息的针对性训练。
Learning Frequency-Domain Fusion for Multimodal Remote Sensing Semantic Segmentation
论文:https://ieeexplore.ieee.org/document/11206533
源码:https://github.com/fy-sun/FDMF-Net
网文:https://mp.weixin.qq.com/s/-FpC3UAeiaNOSaTzIaqumA
FDMFNet架构以及核心组件Amplitude Spectrum Decoupling (ASD):ASD位于Encoder开头。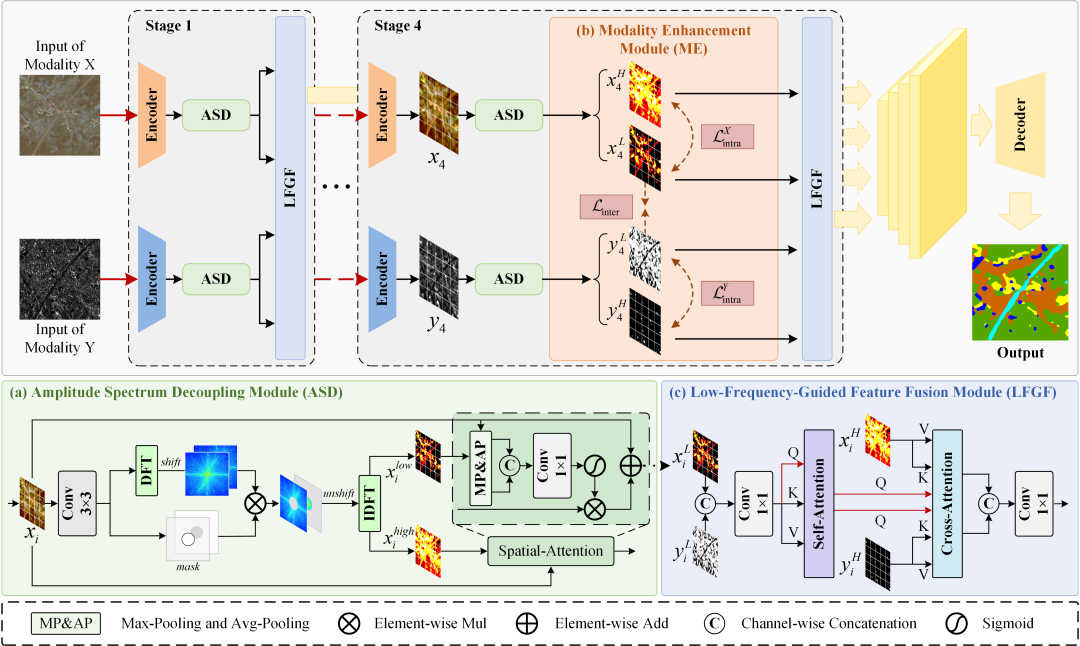
ASD核心创新点:
- 自适应频域拆分:通过 MLP 学习特征的频域分布特性,生成自适应阈值,动态调整高低频拆分比例,比固定掩码更能适配不同特征的频域差异。可学习融合系数平衡高度与宽度维度的阈值贡献,提升拆分灵活性,适配不同长宽比的特征。
- 频域 - 空域协同增强:先在频域拆分高低频特征,再通过空域注意力分别强化,既保留频域细节(高频)与结构(低频),又通过空域注意力定位关键区域,比单一频域或空域增强更全面。
ASD 模块的特征处理流程分为 “频域分解→空域增强→输出” 四步,核心聚焦高低频特征的解耦与增强:
- 频域分解:特征经 3×3 卷积预处理后,通过 FFT 转换至频域,频域移位将低频移至中心;基于特征全局统计生成自适应阈值,构建低频掩码,拆分高频(掩码取反)与低频(掩码保留)频域特征;经逆频域移位与 IFFT,恢复为实数域的高低频特征。
- 空域增强与融合:高低频特征分别经空间注意力增强(结合原始特征的统计信息),生成增强后的高低频特征;通过空间门控生成动态权重,平衡增强后的高低频特征贡献,完成频域 - 空域协同融合。
- 输出:输出增强后的高频特征(细节丰富)与低频特征(结构完整),可用于后续单独处理或进一步融合。
DCT
Mesoscopic Insights: Orchestrating Multi-scale & Hybrid Architecture for Image Manipulation Localization
Paper:https://arxiv.org/pdf/2412.13753
Code:https://github.com/scu-zjz/Mesorch
博客:https://mp.weixin.qq.com/s/EcfT68HSK5qHHeRIifb-Rw(代码解释)
这篇文档核心是解决 “图片造假定位” 的问题 —— 简单说就是找出图片哪里被篡改了(比如拼接、复制粘贴、修补),还得做得又准又高效。
它的核心思路很有意思:以前找图片造假,要么只盯着细节(比如像素噪声、边缘痕迹,像 “显微镜看细节”),要么只看整体(比如物体是不是合理,像 “望远镜看大局”),但这俩都不够全面。毕竟造假常是改物体语义(比如换人脸、加不该有的东西),既需要细节痕迹,也需要懂物体层面的逻辑。
所以研究人员提出了一个叫 “Mesorch” 的模型,相当于把 “显微镜” 和 “望远镜” 结合起来,还加了 “中间视角”(也就是文档说的 “介观视角”),同时抓细节和大局。具体怎么做的呢?
- 双模型并行干活:用 CNN(擅长抓细节)处理图片的 “高频信息”(比如边缘、纹理这些细枝末节的痕迹),用 Transformer(擅长抓全局)处理 “低频信息”(比如物体布局、整体语义),而且是同时运行,不会让一个模型 “抢风头”。
- 多尺度 + 智能调权重:模型会看图片的不同缩放尺度(比如正常大小、缩小一半等),还会自动判断哪个尺度的信息更重要,给重要的多加分,不重要的少管甚至删掉(剪枝),这样既保证准确,又减少计算量。
- 先增强再分析:先用一种叫 DCT 的技术,把图片拆成高频和低频两部分,再和原图结合,让造假痕迹更明显,方便后续识别。
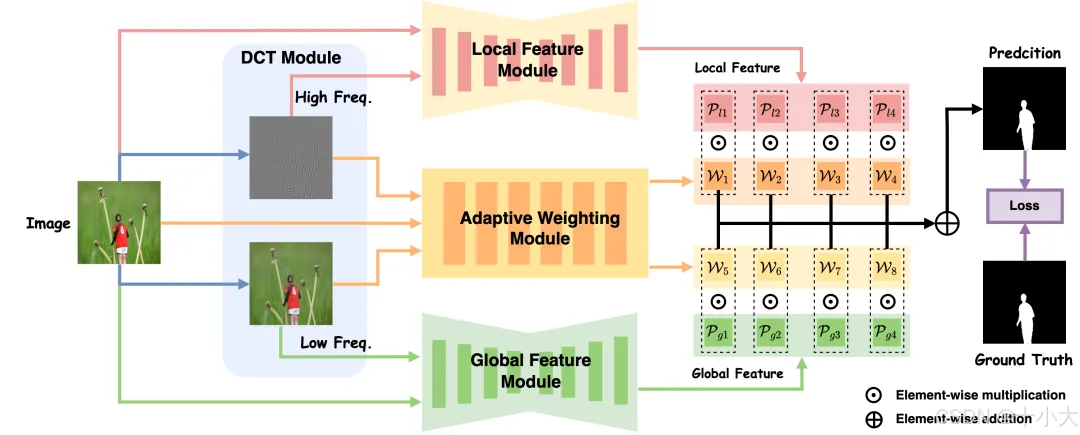
现有频率域方法(如直接 FFT/DCT 后丢弃高频)存在不足:
- 固定频率划分:手动选择频率阈值(如仅保留前 10% 低频),无法自适应不同任务需求(如分割需更多高频,分类需更多低频);
- 缺乏归一化:频率域特征数值范围波动大(从 - 1e3 到 1e3),直接输入后续模块易导致梯度爆炸;
- 无动态适配:DCT 矩阵固定为单一尺寸,无法适配不同输入分辨率(如 32×32、64×64 特征图)。
Mesorch 通过频率域三大创新解决上述问题:
- 自适应频率划分:通过alpha参数灵活控制高低频比例(如高频alpha=0.05保留 95% 高频,低频alpha=0.95保留 95% 低频),适配不同任务;
- 动态 DCT 矩阵:根据输入特征尺寸(H/W)实时生成对应大小的 DCT 矩阵,支持任意正方形特征图;
- 全局归一化:将逆 DCT 后的特征映射到 0~1,避免数值波动,提升后续模块稳定性。
HS-FPN: High Frequency and Spatial Perception FPN for Tiny Object Detection(双路DCT高通滤波+注意力)
Paper:https://arxiv.org/pdf/2412.10116
Code:https://github.com/ShiZican/HS-FPN
博客:https://mp.weixin.qq.com/s/WgAXiETVDKVojaG4L0Ozdw(代码解释)
特征金字塔网络(FPN)的引入显着提高了目标检测性能。然而,在检测微小物体方面仍然存在重大挑战,因为它们的特征只占特征图的一小部分。虽然 FPN 集成了多尺度特征,但它并没有直接增强或丰富微小物体的特征。此外,FPN缺乏空间感知能力。为了解决这些问题,提出HFP(即通过高频信息增强细节特征)。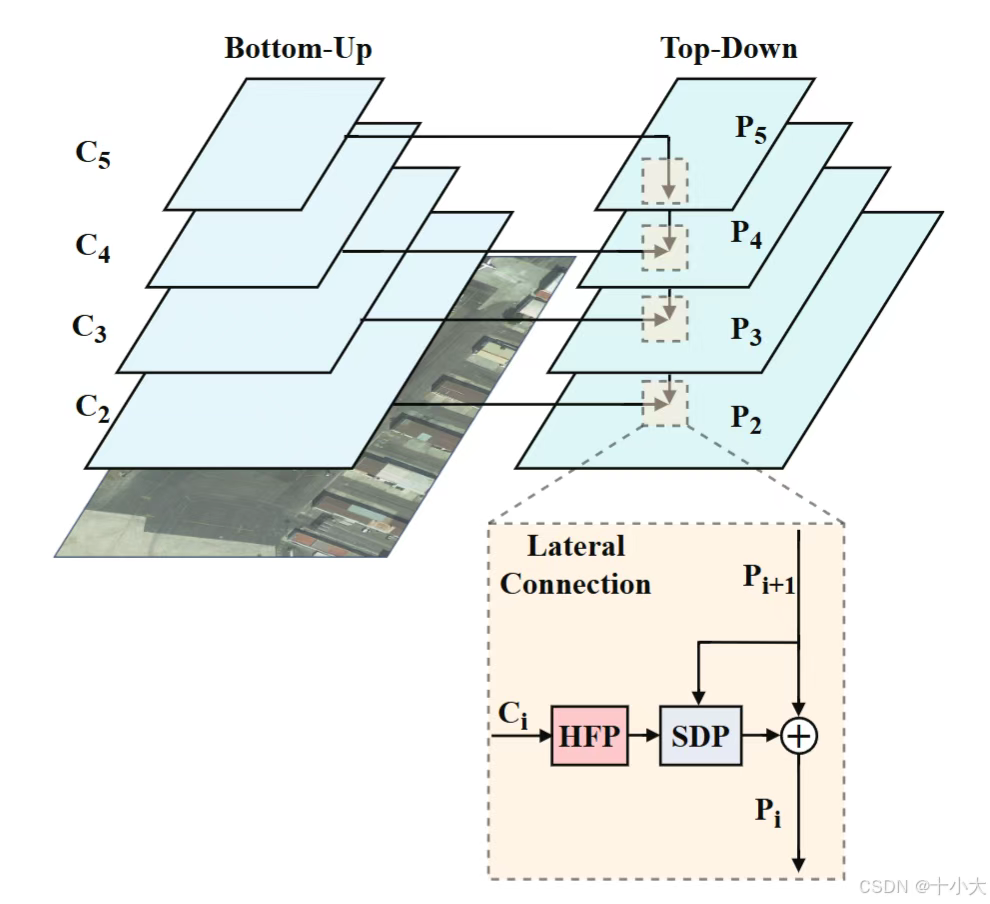
关键模块介绍
High Frequency Perception(HFP):通过高通滤波器生成高频响应。这些高频响应被用作空间和通道视角的掩码权重,以丰富和突出原始特征图中微小物体的特征。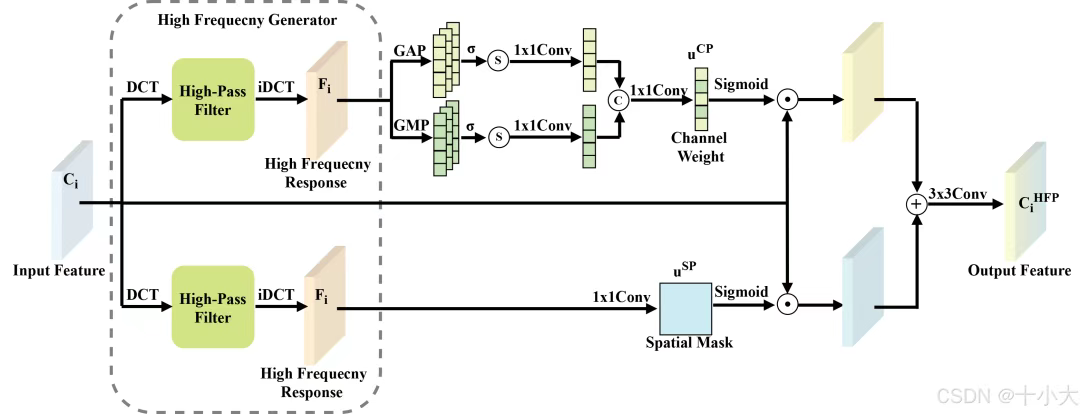
HFP设计思路:高频生成→双路径注意力→特征融合。
- 输入特征图先经过DCT 离散余弦变换转换到频率域,再通过高通滤波器(权重矩阵)屏蔽左上角低频区域(对应图像中均匀背景),保留高频区域(对应小目标的边缘、纹理等细节),最后通过逆 DCT 变换将高频信息转回空间域,得到高频响应图。
- 将高频响应图作为空间掩码,与原始特征图逐像素相乘,强化小目标所在空间区域的特征,抑制背景干扰。对高频响应图做自适应池化(最大 + 平均),提取通道级统计信息,通过分组卷积生成通道权重,与原始特征图逐通道相乘,放大包含小目标信息的通道特征。
- 空间路径与通道路径的输出特征相加,再经过 3×3 卷积和分组归一化,消除冗余信息并稳定特征分布,最终输出增强后的小目标特征图(维度与输入一致,确保可插入现有 FPN 结构)。
FSTA-SNN:Frequency-Based Spatial-Temporal Attention Module for Spiking Neural Networks(自适应频率选择+时间空间双注意力,既轻量又涨点)
Paper:https://arxiv.org/pdf/2501.14744
Code:https://github.com/yukairong/FSTA-SNN
博客:https://mp.weixin.qq.com/s/0odJaLl-lANNGmg7mjuWNQ(代码解释)
我们提出了一种基于频率的时空注意 (FSTA) 模块来增强 SNN(脉冲神经网络) 中的特征学习。
模块介绍
Discrete Cosine Transform (DCT)-based Spatial Attention(DCTSA,图(b)):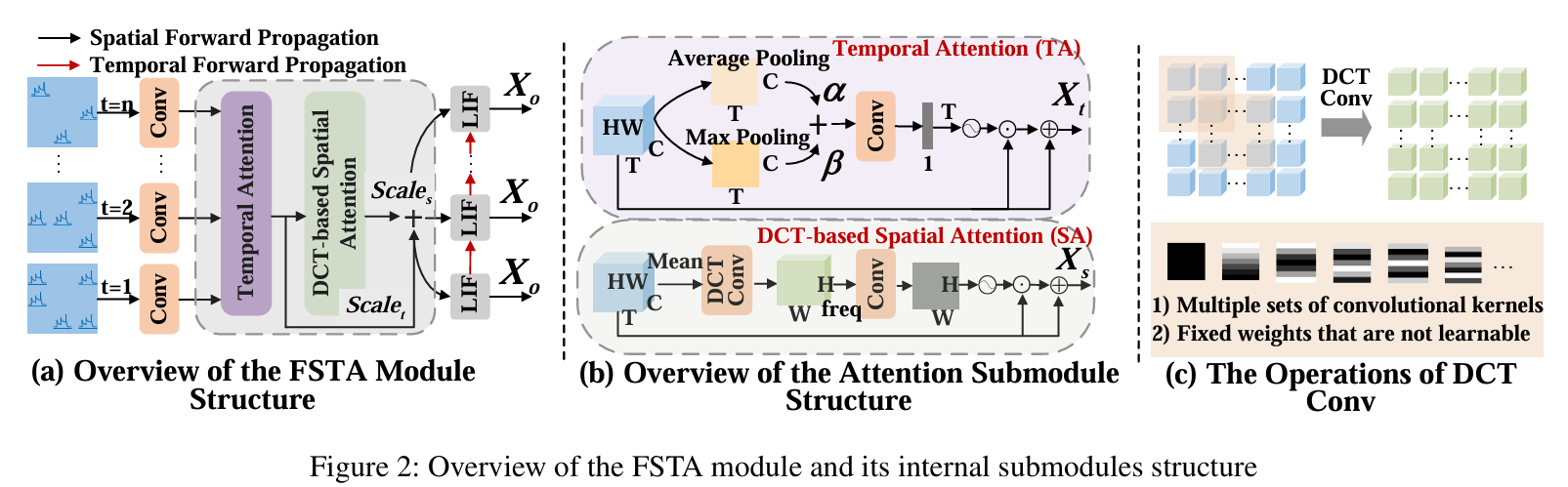
DCTSA包含DCT频率提取,自适应频率注意力,时空融合三个主要部分:
- DCT频率提取:DCT 将空间域特征转换为固定数量的频率分量(如 49=7×7),复杂度降为线性。
- 自适应频率注意力:通过FreConv模块学习频率权重,自动强化任务关键频率。
- 时空融合:时间注意力捕捉动态依赖,频率注意力捕捉空间细节,二者加权融合,适配时序视觉任务。
ADCD-Net: Robust Document Image Forgery Localization viaAdaptive DCT Feature and Hierarchical Content Disentanglement(自适应离散余弦变换进行伪造检测)
github:https://github.com/KAHIMWONG/ACDC-Net
论文:https://arxiv.org/pdf/2507.16397
问题:DCT在文档型篡改检测的能力已被证实。但是图片的平移、缩放、裁切很容易导致DCT失效,模型鲁棒性极速下滑。
ADCD-Net 通过自适应离散余弦变换(DCT)特征和分层内容解耦技术,解决了伪造检测中的关键问题。DCT 特征对块对齐的敏感性被自适应调节模块优化,从而增强了模型对图像缩放、裁剪等失真的鲁棒性。此外,分层内容解耦技术有效缓解了文本与背景之间的差异,提升了定位性能。
模型还利用了文档背景区域的“原始性”特征,通过构建未篡改区域的原型,进一步提高了伪造区域的定位精度和鲁棒性。
关键创新:根据对齐分数 s^aln,动态调整 DCT 特征的贡献
M2TR: multi-modal multi-scale transformers for deepfake detection (多模多尺度)
论文:https://arxiv.org/pdf/2104.09770.pdf
网文:
M2TR: 复旦提出首个多模态多尺度Transformer
我们首先利用EfficientNet作为backbone提取了网络的浅层特征,然后利用Multi-scale Transformer进行多尺度特征提取和Cross Modality Fusion进行双模态融合。
区别于ViT的地方有三点:
- 1.不是在图像取patch而是在feature map上
- 2.不同head里取的patch size不同
- 3.patch被flatten成一维经过了self-attention之后会被重新reassemble成二维得到3D feature map
Cross Modality Fusion
首先我们对图像做DCT变换,得到了频率分布图,DCT变换具有良好的性质:高频集中在左上角而低频在右下角,因此我们手动对其进行划分,得到了高、中、低三个频段的频率分量,但是频率图不具有RGB图像的视觉特征,也没有办法利用CNN进行特征提取,为此我们对三个分量进行逆DCT变换,重新得到了RGB域的表示,但是这个表示是frequency-aware的,然后利用卷积层进行特征提取。
双模态(本文指的是:RGB与频域)融合是一个长久的问题,如何良好的嵌入到transformer更是关键,一种最简单的做法、也是现在很多利用频率信息的做法就是对RGB和Frequency采用一种two-stream的双流结结构,平行操作然后在中间或者输出的地方进行融合,这种做法我不是非常赞同,因为并行结构的一个重要前提是两个模态的地位或者信息量是均衡的,但是对于Deepfake来说,频率的信息其实还是具有噪声的,比如人脸的一些部分如头发等在频率也可能集中在高频区域里,因此合适的做法是把频域作为一种辅助模态。
基于这种想法、同时受启发于transformer的query-key-value的设计,我们提出了一种QKV的方法来融合两个模态:把RGB模态作为query、frequency模态作为memory,这样的设计一方面能突出RGB的作用,另一方面能更好地发掘frequency分布里的异常区域。
小波变换
mamba与小波变换参见“超链接”
ASCNet: Asymmetric Sampling Correction Network for Infrared Image Destriping(RHDWT残差离散小波变换下采样模块)
论文:https://arxiv.org/pdf/2401.15578v2
源码:https://github.com/xdFai/ASCNet
博客:https://mp.weixin.qq.com/s/4iD1YKs1qJngv0AgIBgjvQ(残差离散小波变换下采样模块源码解释)
ASCNet的网络结构主要由三个核心模块组成:不对称采样(AS)、残差Haar离散小波变换(RHDWT)和列非均匀性校正模块(CNCM),这些模块共同作用,提升了红外图像去条纹的效果。简要描述如下: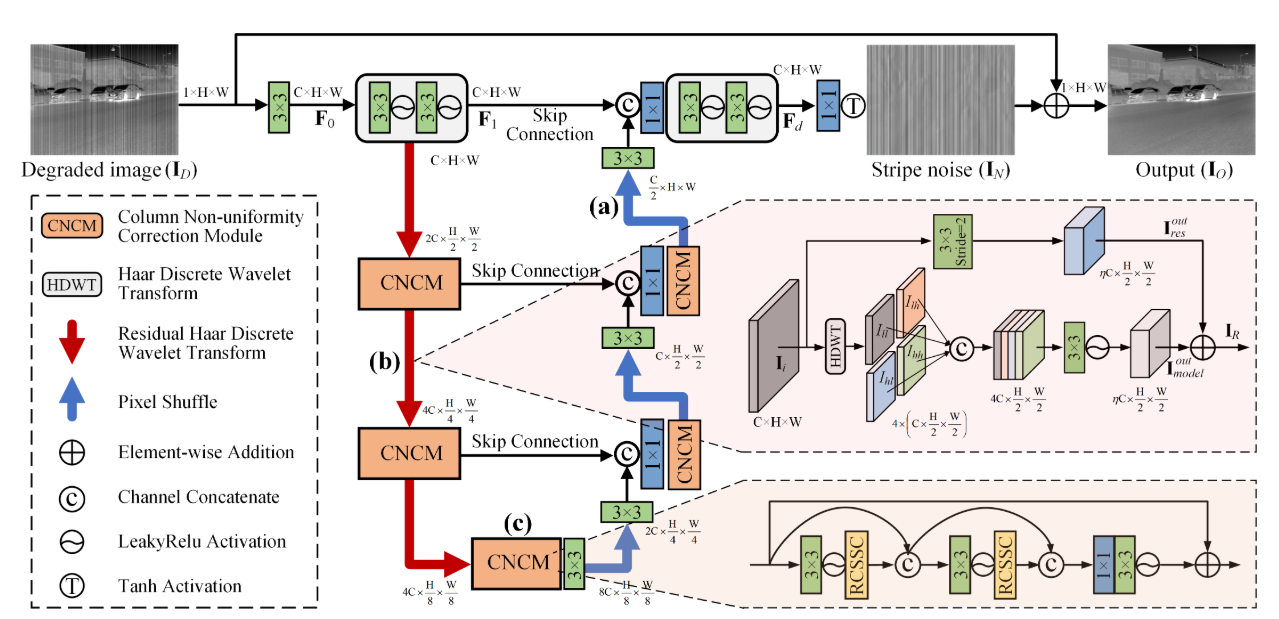
- 输入与初步处理:给定一张退化的红外图像,首先通过卷积层提取初步特征(F0)。然后,利用卷积和LeakyReLU激活函数进一步增强这些特征,生成浅层特征(F1)。
- 下采样与特征增强:ASCNet通过三个阶段的RHDWT和CNCM对图像进行下采样和特征增强。RHDWT模块结合了小波变换和残差分支,有助于融合条纹方向性先验知识与数据驱动的语义交互,从而丰富特征表示。
- 不对称采样(AS):在上采样阶段,ASCNet使用像素重排(PS)而非传统的小波逆变换(IDWT),这有助于减少语义偏差,并保证跨级别列语义的一致性。
- 特征融合与上采样:在解码阶段,网络通过长跳连接(skip
connections)将编码阶段的特征与解码阶段的特征融合。接着,使用卷积层进一步增强解码特征,得到高分辨率的输出特征(Fd)。 - 列非均匀性校正模块(CNCM):CNCM通过嵌套的RCSSC块进一步增强列的特征,捕捉空间相关性、自依赖性,并进行列特征的全局校正,从而有效去除条纹噪声。
- 最终,ASCNet输出去条纹后的图像,通过Tanh激活函数生成残差图像,并将其与退化图像相加,得到去条纹后的最终图像。
关键模块RHDWT:
RHDWT模块通过创新性地结合小波变换和残差学习,提升了图像特征的表示能力,特别是在处理条纹噪声时,能够有效地保留和增强条纹的方向性特征,同时避免丢失重要的背景信息,为ASCNet提供了强大的去条纹能力。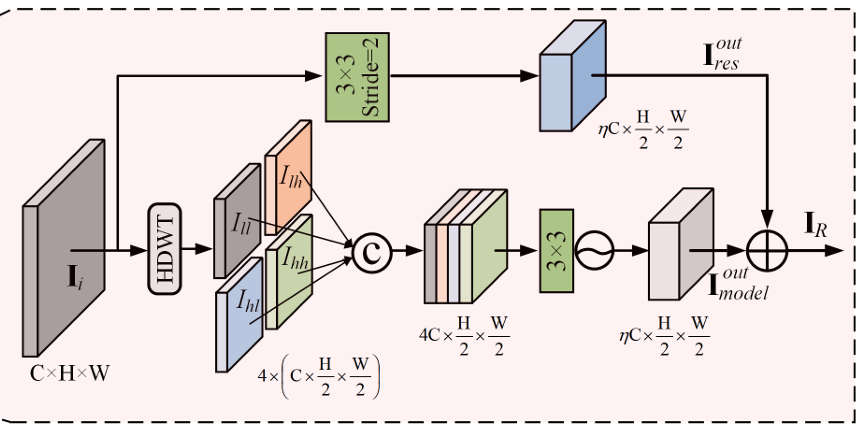
WaMaIR: Image Restoration via Multiscale Wavelet Convolutions and Mamba-based Channel Modeling with Texture Enhancement
论文地址:https://arxiv.org/pdf/2510.16765
本文的主要研究方法是提出了一种名为 WaMaIR 的图像恢复框架,它采用 U 形结构,输入降质图像后,先通过全局多尺度小波变换卷积(GMWTConvs)模块生成浅层纹理特征,该模块结合普通卷积和小波变换卷积,利用小波变换将图像分解为不同频率的子带,从而在不同尺度上提取图像特征,有效扩大感受野,为后续恢复提供丰富特征。接着特征进入多个 CNN 块提取高级特征,在此过程中采用多输入多输出策略,将多尺度预测图像送入多尺度纹理增强损失(MTELoss)计算损失,MTELoss 综合空间域、频率域和小波域的损失,全面指导模型精确重建和增强纹理细节。
创新点
- 提出了基于Mamba的通道感知模块,通过整合全局池化操作和Mamba序列模型,显式地编码特征通道之间的全局依赖关系,增强了模型对颜色、边缘和纹理属性的敏感性,从而提高了图像恢复的效果,尤其是在处理复杂的纹理和色彩信息时。
- 引入了全局多尺度小波变换卷积,利用小波变换来提取多尺度的高频和低频图像特征,有效地扩展了感受野,使模型能够捕捉到更广泛的图像特征,从而更好地保留和丰富纹理细节,提升了图像恢复的整体质量。
- 损失函数包括三个部分:空间域、频率域、小波域。
L spatial = ∑ i = 1 3 1 P i ∥ I ^ i − Y i ∥ 1 \mathcal{L}_{\text{spatial}} = \sum_{i=1}^3 \frac{1}{P_i} \left\|\hat{I}_i - Y_i\right\|_1 Lspatial=i=1∑3Pi1 I^i−Yi 1
L frequency = ∑ i = 1 3 1 S i ∥ [ R ( F ( I ^ i ) ) , S ( F ( I ^ i ) ) ] − [ R ( F ( Y i ) ) , S ( F ( Y i ) ) ] ∥ 1 \mathcal{L}_{\text{frequency}} = \sum_{i=1}^3 \frac{1}{S_i} \left\|\left[R(\mathcal{F}(\hat{I}_i)), S(\mathcal{F}(\hat{I}_i))\right] - \left[R(\mathcal{F}(Y_i)), S(\mathcal{F}(Y_i))\right]\right\|_1 Lfrequency=i=1∑3Si1 [R(F(I^i)),S(F(I^i))]−[R(F(Yi)),S(F(Yi))] 1
L wavelet = ∑ i = 1 3 ∑ b ∈ { LL , LH , HL , HH } SSIM ( W b ( I ^ i ) , W b ( Y i ) ) \mathcal{L}_{\text{wavelet}} = \sum_{i=1}^3 \sum_{b \in \{\text{LL}, \text{LH}, \text{HL}, \text{HH}\}} \text{SSIM}(\mathcal{W}_b(\hat{I}_i), \mathcal{W}_b(Y_i)) Lwavelet=i=1∑3b∈{LL,LH,HL,HH}∑SSIM(Wb(I^i),Wb(Yi))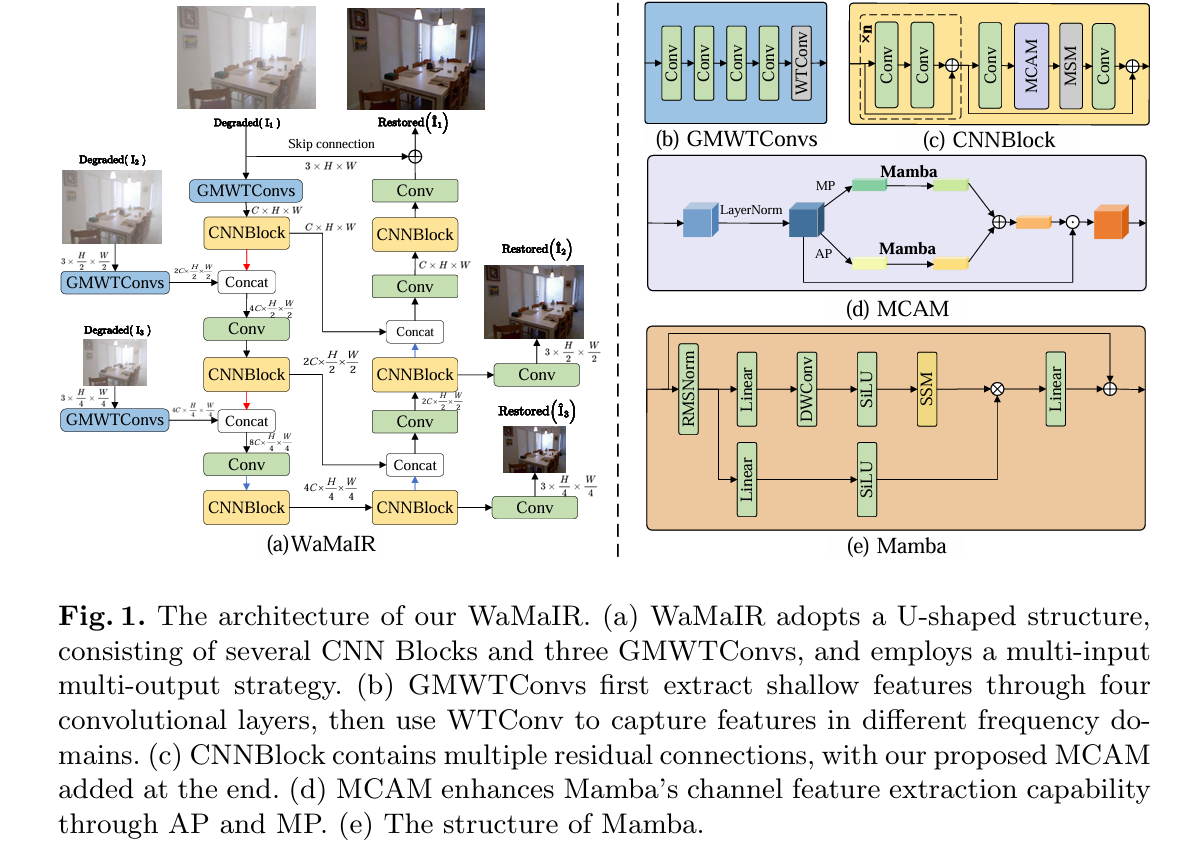
Global Modeling Matters: A Fast, Lightweight and Effective Baseline for Efficient Image Restoration(小波+傅里叶+傅里叶域 L1 损失)
paper: https://arxiv.org/pdf/2507.13663
code: https://github.com/deng-ai-lab/PW-FNet
论文提出金字塔小波-傅里叶网络(PW-FNet),通过块间金字塔小波多输入多输出结构实现多尺度多频带分解、块内用傅里叶变换替代自注意力机制,高效完成图像恢复任务。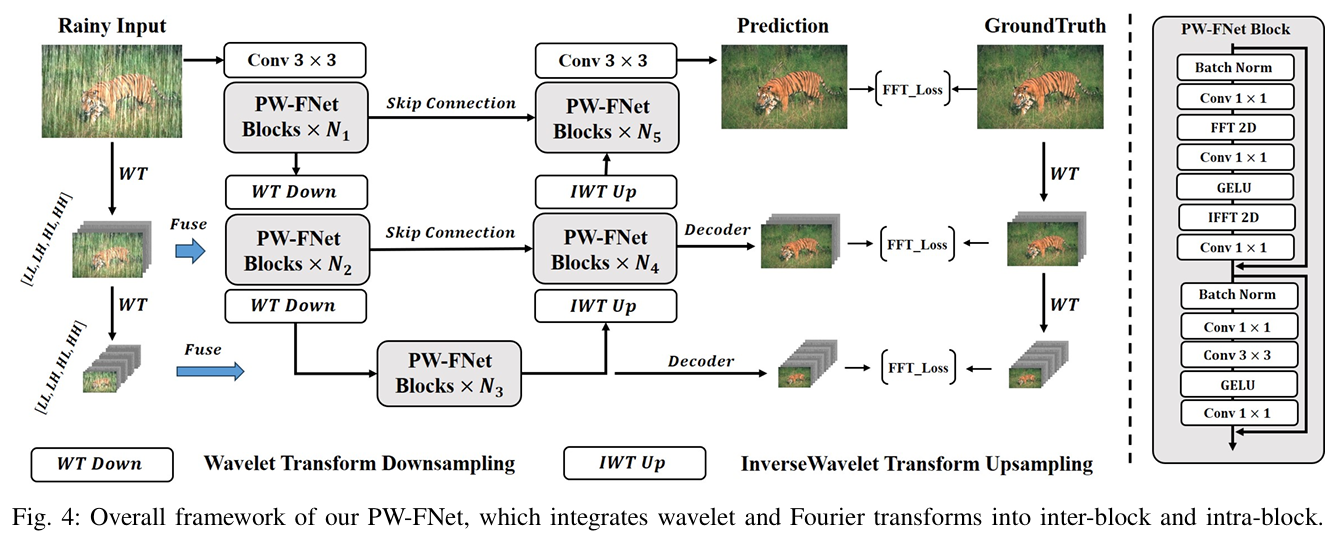
创新点:
- 提出金字塔小波-傅里叶迭代流水线,高效分离图像退化成分与清晰成分。
- 设计PW-FNet,块间多尺度多频带分解,块内用傅里叶变换替代自注意力,兼顾性能与效率。
- 引入傅里叶域损失函数,契合模型在频域的特征处理设计,通过对不同分支输出分配等权求和,提升图像恢复质量。
小波变换擅长多尺度、多频带分解,傅里叶变换擅长全局频率特征建模,二者在 PW-FNet 中通过 “先分解、后聚焦” 的逻辑深度协同,具体分为两个核心阶段:
- 小波变换:多尺度频带分解,隔离退化特征
对输入退化图像(如带雨、模糊图像)逐层应用小波变换,将上一层的 LL 子带作为下一层的输入,重复小波分解,直到 LL 子带分辨率足够小。
核心作用:通过小波分解将 “退化特征” 与 “正常图像特征” 分离到不同子带,缩小后续特征处理的范围,降低模型复杂度。 - 傅里叶变换:全局频率聚焦,强化退化抑制
在小波分解的基础上,傅里叶变换进一步实现退化特征的 “全局精准定位”,具体逻辑:
高频区域聚焦:对小波分解后的每个子带(尤其是 LL 和 HL 子带)应用快速傅里叶变换(FFT),将空间域特征映射到频率域;论文发现,退化特征在频率域中会集中在紧凑的高频区域(如 HL 子带的高频区域),而正常特征分布更均匀。
全局建模:傅里叶变换的 “全局性”(覆盖整个子带的频率计算)可避免传统 CNN 的局部感知局限,同时替代 Transformer 计算复杂的自注意力机制 。
损失函数设计:
论文摒弃传统的空间域损失(如 MSE、空间 L1),设计傅里叶域 L1 损失,核心原因是:模型的核心特征处理(小波 - 傅里叶协同)在频率域完成,频率域损失能更直接地优化退化特征的抑制效果。
仅用傅里叶域 L1 损失的模型,比 “空间域损失” PSNR 高 0.95dB,比 “空间 + 小波损失” 高 0.85dB
ERIENet: An Efficient RAW Image Enhancement Network under Low-Light Environment(小波损失)
论文:https://arxiv.org/pdf/2512.15186v1
网文:https://mp.weixin.qq.com/s/B64REJCuBiOf3TPzau4j0Q
ERIENet使用了一种“小波SSIM损失”。SSIM本身是一种衡量图像结构相似性的指标,比单纯比像素值更符合人眼感知。现在,它被应用在小波分解后的各个子带上。这意味着,网络不仅在全局上要和目标图像像,在每一个尺度、每一个方向(水平、垂直、对角)的细节上也要像。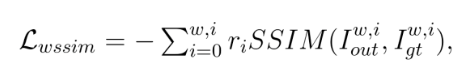
同时,ERIENet还采用了“小波MSE损失”,在像素值和小波系数上都进行约束。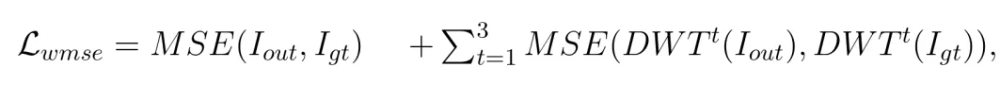
最终的损失函数是L1损失和这两个小波损失的加权和: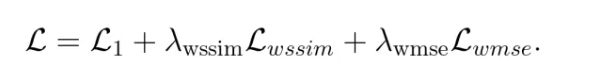
TIR-Diffusion: Diffusion-based Thermal Infrared Image Denoising via Latent and Wavelet Domain Optimization(小波损失)
论文地址:https://arxiv.org/pdf/2508.03727
网文:https://mp.weixin.qq.com/s/Fb4CnYOfBrAwnSFkO3T3qA
提出“潜空间 + 小波域”的双域联合优化损失,这是针对热红外噪声特性量身定制的优化策略。
不同于仅在像素域或 latent 域监督的方法,作者设计了:
- Latent Loss(MSE + SSIM):保证全局结构与语义一致
- Wavelet Loss(DWT / DTCWT):专门约束 TIR 固定模式噪声(FPN)与条纹噪声的高频特征
小波损失的设计:
为了在小波域中计算损失,我们通过两级二维离散小波变换(DWT)/ 双树复小波变换(DTCWT)对预测重建结果 x̂和真实值 x 进行分解。从分解结果中,我们利用水平、垂直和对角线子带 s∈{h, v, d}。我们计算 x̂和 x 各自的小波系数之间的均方误差,从而直接惩罚这些高频分量中的不一致性。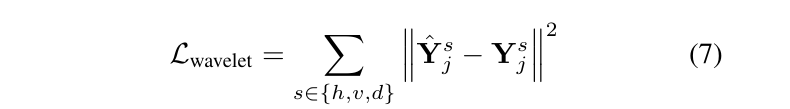
其中,Ŷₛⱼ和 Yₛⱼ分别表示 x̂和 x 的子带小波系数。
Lightweight Local–Global Dual-Path Feature Fusion Network for Infrared Small Target Image Super-Resolution and Enhancement(一路DCT,一路小波+DCT)
论文:https://ieeexplore.ieee.org/document/11271448
源码:https://github.com/98Hao/LDFF-Net
网文:https://mp.weixin.qq.com/s/qA3KUKyAfhDCOxMnBgsUnQ
Enhanced High Frequency Perception Module (EHFPM):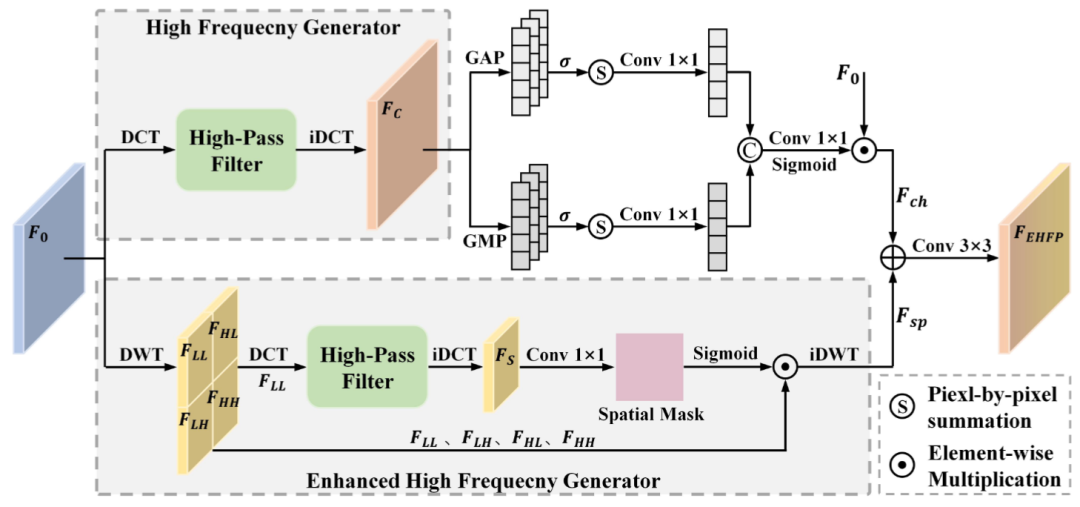
EHFPM创新点:DWT+DCT双频域协同 + 双路径高频增强
- 频域分离与预处理:输入特征经 DWT 分解为低频分量(LL,结构信息)和三个高频分量(HL/LH/HH,细节信息);低频分量进入 DCT 变换,转换为频域特征,通过可学习权重过滤低频区域,保留高频信息。
- 双路径高频增强:空间路径频域高频特征经 iDCT 转回空间域,生成空间掩码;掩码与原始 4 个小波分量加权后,经 iDWT 重构为完整空间特征,强化高频空间细节。通道路径输入特征经 DCT + 低频过滤后,通过补丁池化(max/avg)聚合特征,经通道 MLP 生成通道权重;原始特征与权重加权,强化高频通道特征。
- 融合优化输出:空间路径与通道路径特征元素相加,经 3×3 卷积融合与 GroupNorm 归一化,输出高频增强后的特征。
适用范围:适用于通用视觉领域,特别是超分、增强、小目标检测/分割等对高频敏感或需要细节保留的任务。
缝合位置:需要特征提取/特征增强的位置,基本块内部靠前放置。
模块效果:EHFPM的消融研究说明EHFPM中空间分支、通道分支、多尺度滤波的有效性。其中在空间分支中效果最好。
CWNet: Causal Wavelet Network for Low-Light Image Enhancement(小波卷积+傅里叶卷积+mamba)
论文链接:https://arxiv.org/pdf/2507.10689
源码:https://github.com/bywlzts/CWNet-Causal-Wavelet-Network
详情请参考网文
频域(DCT,小波变换)与CNN结合
超分-wavelet
Invertible Image Rescaling 可逆图像缩放:完美恢复降采样后的高清图片(ECCV 2020 Oral )
论文地址:arXiv
代码和预训练模型:github (已放出)
网文
Wavelet Integrated CNNs for Noise-Robust Image Classification, CVPR2020
- 源码:https://github.com/LiQiufu/WaveCNet
- 网文:
Wavelet Integrated CNNs提高图像分类的噪声鲁棒性
频域深度学习 Learning in the Frequency Domain
- 源码:https://github.com/calmevtime/DCTNet
- 网文:
频域深度学习 Learning in the Frequency Domain
图像细节处理
区分细节与噪声
IVHC (Fast image noise estimation)—对应论文:Estimation of Gaussian, signal-dependent, and processed noise in Image and Video Signals
高动态范围中的细节增强(红外)
【红外图像增强算法】数字细节增强算法的缘由与效果(我对FLIR文档详解)
FLIR数字图像细节增强 (DDE)
高动态范围红外图像压缩的细节增强算法研究
FlyAI小课堂:小白学PyTorch(6) CLAHE 限制对比度自适应直方图均衡化 (一般用作对基础层的处理方法)
多尺度细节增强
- 多尺度的图像细节提升(有python代码,论文:DARK IMAGE ENHANCEMENT BASED ON PAIRWISE TARGET CONTRAST AND MULTI-SCALE DETAIL BOOSTING)
- 多尺度图像细节提升(multi-scale detail boosting)Python版(算法简单清晰)
- OPENCV-高反差保留算法
高反差保留算法,先使用高斯滤波器对图像进行平滑,高斯滤波器对边缘的平滑作用更加明显,使用原图减去高斯平滑之后的图,就得到强化边缘值。通过调节高斯模糊的半径可以控制得到的边缘的强度。
高反差保留 = 原图 - 高斯模糊图
然后将原图和高反差保留图进行叠加,可以得到锐化的图像。
- 提取图像细节的两种方法(加性分解/乘性分解)
- 图像细节增强。具体四种方法:
L0平滑:L0梯度最小化,前处理后图像与原图的相似性+平滑的程度(梯度非零个数)。【迭代求解,隐式】
引导滤波:局部线性假设+L2正则约束(表示输入输出的差异)【得到滤波核,显式】
双边滤波:空间邻近度+像素值相似度(和0阶各向异性相统一,分段线性近似+FFT加速)
加权最小二乘:在保持边缘和平滑滤波之间做平衡,输出输出相似性+惩罚项(梯度大则约束小)
低照度图像处理
低光照图像增强算法汇总(retinex/LIME算法,以及神经网络)
- 图像色彩增强之python实现——MSR,MSRCR,MSRCP,autoMSRCR(对低照度图像效果好,缺点是速度太慢)
保边滤波(双边滤波与快速双边滤波)
双边滤波
- 基本原理:图像去噪的方法很多,如中值滤波,高斯滤波,维纳滤波等等。但这些降噪方法容易模糊图片的边缘细节,对于高频细节的保护效果并不明显。相比较而言,bilateral filter双边滤波器可以很好的边缘保护,即可以在去噪的同时,保护图像的边缘特性。双边滤波(Bilateral filter)是一种非线性的滤波方法,是结合图像的空间邻近度和像素值相似度的一种折衷处理,同时考虑空域信息和灰度相似性,达到保边去噪的目的
- 缺点:速度太慢,时间是中值滤波、高斯滤波的几十倍,难以做到实时处理。
OpenCV-Python学习—图像平滑(多种滤波算法函数,包括双边滤波与联合双边滤波)
opencv自带的快速的边缘保留滤波算法
高斯双边模糊与mean shift均值模糊两种边缘保留滤波算法,都因为计算量比较大,无法实时实现图像边缘保留滤波,限制了它们的使用场景,OpenCV中还实现了一种快速的边缘保留滤波算法cv2.edgePreservingFilter(…)。
高斯双边与mean shift均值在计算时候使用五维向量是其计算量大速度慢的根本原因,该算法通过等价变换到低纬维度空间,实现了数据降维与快速计算。
经测试,处理单张图像的时间与中值滤波、高斯滤波等相似。
其它快速双边滤波
图像处理:从 bilateral filter 到 HDRnet—(包括Bilateral Grid(2013)、Bilateral Guided Upsample(2016))
https://hub.fastgit.org/search?l=Python&q=fast+Bilateral+filtering&type=Repositories
fast approximate 算法(2006)
论文: A Fast Approximation of the Bilateral Filter using a Signal Processing Approach
bilateral Grid (2013)
论文:https://groups.csail.mit.edu/graphics/bilagrid/bilagrid_web.pdf
源码:https://hub.fastgit.org/qq491577803/ImageFilter/blob/main/BilateraFilter/BilateralGrid.py
将空间域和像素值域都离散化、网格化,提出了 bilateral grid 数据结构,进一步加速了计算过程.
Bilateral Guided Upsample
https://people.csail.mit.edu/hasinoff/pubs/ChenEtAl16-bgu.pdf
由于很多复杂的滤镜处理速度比较慢,一个很常用的解决思路是对原图 downsample 之后做处理,然后用 upsample 得到处理结果。这里 Kaiming He 的 guide filter 就是一个这种思路的很好的应用。而在 BGU 这个例子里,利用 bilateral grid 来做 downsample - upsample 的工作,使得效果更为出色。(xys:BGU可能比guild filter更出色)
导向/引导滤波(Guided Fliter)(2010,2013,2015)
论文:何凯明出品
[1] K. He, J. Sun, and X. Tang. Guided image filtering. In ECCV, pages 1–14. 2010.
[2] K. He, J. Sun, and X. Tang. Guided image filtering. TPAMI, 35(6):1397–1409, 2013
[3] He K, Sun J. Fast Guided Filter[J]. Computer Science, 2015.
源码:
python源码 https://github.com/swehrwein/python-guided-filter
https://hub.fastgit.org/bravotty/GuidedFilter
pytorch版源码 https://hub.fastgit.org/perrying/guided-filter-pytorch/blob/master/guided_filter.py
此外,cv2的扩展版直接有实现。
Guide filter从命名的方法就可以看出除了需要输入图片外,还需要一个guide image(导向图)。导向图 可以是一副单独的图像,也可以是需要处理的输入图像.当引导图像就是输入图像本身的时候,导向滤波就变成了一个Edge-perserving的滤波器。
- 导向滤波比起双边滤波来说在边界附近效果较好(导向滤波的一个很好的性能就是可以保持梯度,这是bilateral可以保留便于但做不到保持梯度,因为会有梯度翻转现象。);
- 另外,它还具有 O(N) 的线性时间的速度优势。(双边滤波是O(N^2))
何凯明在2015又发表了一篇《Fast Guided Filter》的文章,阐述了一种很实用的更快速的导向滤波流程。如下所示。其本质是通过下采样减少像素点,计算mean_a & mean_b后进行上采样恢复到原有的尺寸大小。假设缩放比例为s,那么缩小后像素点的个数为 N / s 2 N/s^2 N/s2, 那么时间复杂度变为 O ( N / s 2 ) O(N/s^2) O(N/s2)(只是需要注意的是上采样和下采样本身也是有时间消化的)。
可应用在图像增强、HDR压缩、图像抠图及图像去雾等场景。
引导滤波与细节增强
基于引导滤波的高动态红外图像增强处理算法
基于非锐化掩模引导滤波的水下图像细节增强算法研究
Fast End-to-End Trainable Guided Filter
深度学习【49】Fast End-to-End Trainable Guided Filter
在这篇文章里,作者将引导图片作为神经网络的学习的一部分,根据不同的任务会自动学习出该引导矩阵。
在利用神经网络生成图片中,特别是高分辨率图片,一般其速度非常慢,比如pix2pix。该论文在引入引导滤波后只需要先生产低分辨率图片,然后将引导矩阵上采样,接着利用引导滤波公式就能够生产高分辨率的图片。这样一来主要计算都集中在低分辨率的图片上,高分辨图片生成的计算量就变得很少。
边缘损失
CVPR2020 | 高低频分离超分方案
作者希望训练过程可以聚焦于图像的边缘细节,进而有效的增强视觉质量。在这里,作者采用Canny操作提取图像的边缘,边缘损失定义如下:
CVPR2020丨SPSR:基于梯度指导的结构保留超分辨率方法
论文使用了图像的梯度信息去指导图像复原。如何通过梯度信息指导图像复原?
主要有两点:
1.SPSR 采用了一个额外的梯度分支网络,生成高分辨率梯度图,作为额外的结构先验。
2.SPSR 引入了新的梯度损失,对超分辨率图像施加了二次约束。
因此,梯度信息以及梯度 Loss 能够进一步帮助生成网络更多的关注图像的几何结构。

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)