CANN是什么?一文搞懂华为昇腾AI核心架构!
作为AI生态的关键组件,CANN(神经网络计算架构)发挥着连接上层AI框架与底层昇腾芯片的枢纽作用。CANN深度结合昇腾芯片的达芬奇架构(Da Vinci Architecture),充分利用其AI Core、Vector Core和Scalar Core的并行计算能力,在ResNet50、BERT等基准模型上实现接近理论峰值的利用率。无论是手机端的Ascend Lite芯片,还是数据中心的Asc
随着国产AI芯片的快速发展,软硬件协同已成为提升算力效率的核心策略。作为AI生态的关键组件,CANN(神经网络计算架构)发挥着连接上层AI框架与底层昇腾芯片的枢纽作用。虽然知名度不及MindSpore或TensorFlow等主流框架,但CANN在AI开发与部署全流程中扮演着不可或缺的角色。本文将从技术视角深入剖析CANN的定位、功能特点及其在昇腾全栈生态中的战略价值。
一、CANN概述与发展历程
CANN(Compute Architecture for Neural Networks)是华为专为其处理器打造的异构计算软件栈。这套架构并非单一工具,而是包含驱动、运行时库、编译器、算子库及开发工具在内的完整中间件体系。
其诞生源于AI领域的一个关键挑战:不同模型对算子类型、精度和并行度的需求存在显著差异,而通用GPU或CPU难以在能效比和性能上同时满足端、边、云等多场景需求。为此,华为通过CANN实现了对昇腾芯片计算资源的高效调度与优化利用。
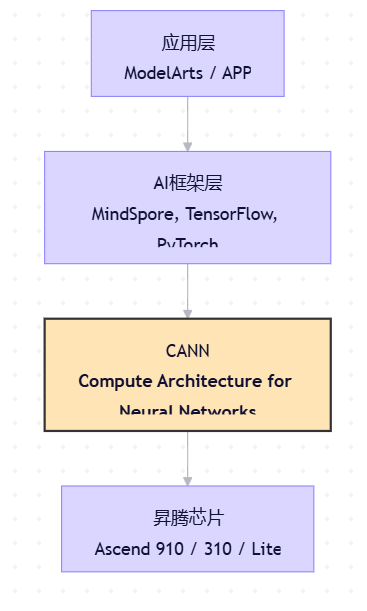
二、CANN在昇腾AI全栈中的位置
在华为昇腾AI全栈架构中,CANN位于“芯片使能层”,处于如下技术链路中:
应用层 → AI框架(如MindSpore、TensorFlow)→ CANN → 昇腾AI芯片(如Ascend 910/310)
这一位置决定了CANN的核心使命:向上屏蔽硬件差异,向下释放芯片性能。开发者无需关心底层寄存器或内存布局,只需通过标准接口调用算子,CANN会自动完成任务调度、内存分配、数据搬运与执行优化。
三、CANN的核心功能模块详解
高性能计算加速库
CANN内置了针对昇腾架构深度优化的基础计算库,涵盖线性代数(BLAS)、卷积神经网络(DNN)、图像处理(VPC)等常用操作。这些库支持多种数据精度(FP32、FP16、INT8、UINT8),并可根据模型需求动态切换,兼顾精度与推理速度。
全面的芯片算子库
截至目前,CANN已预置超过2000个标准AI算子,覆盖主流深度学习模型所需的全部基础操作。例如:
卷积类:Conv2D、DepthwiseConv
激活函数:ReLU、Sigmoid、GELU
归一化:BatchNorm、LayerNorm
控制流:If、While(用于动态图支持)
此外,CANN还支持用户通过TBE(Tensor Boost Engine)或AICPU方式自定义算子,满足特殊业务场景需求。
// ascend_inference.cpp
#include "acl/acl.h"
#include "acl/ops/acl_dvpp.h"
int main() {
// 1. 初始化 ACL 运行环境
aclInit(nullptr);
aclrtSetDevice(0); // 使用设备0
// 2. 加载离线模型(由ATC生成的 .om 文件)
aclmdlDesc *modelDesc;
aclmdlLoadFromFile("resnet50.om", &modelId);
// 3. 准备输入数据(假设已分配 device 内存 inputBuffer)
aclmdlDataset *input = aclmdlCreateDataset();
aclDataBuffer *inputData = aclCreateDataBuffer(inputBuffer, bufferSize);
aclmdlAddDatasetBuffer(input, inputData);
// 4. 执行推理
aclmdlDataset *output = aclmdlCreateDataset();
aclmdlExecute(modelId, input, output);
// 5. 释放资源
aclmdlDestroyDataset(input);
aclmdlDestroyDataset(output);
aclFinalize();
return 0;
}自动化算子开发与调优工具 为简化开发流程,CANN提供以下高效工具链:
- AutoTune:智能搜索最优算子参数配置(包括分块大小、并行策略等)
- AutoCodeGen:基于DSL自动生成高性能算子代码
- Profiling工具:直观展示算子性能数据(耗时、内存占用及流水线瓶颈)
经华为实测,在典型CV/NLP模型中,采用CANN自动化工具后:
- 开发周期:从数周缩短至数天
- 开发效率:提升3倍以上
# relu_tbe.py
from te import tik
from te.utils.op_utils import *
def custom_relu(shape, dtype):
tik_instance = tik.Tik()
input_gm = tik_instance.Tensor(dtype, shape, name="input_gm", scope=tik.scope_gm)
output_gm = tik_instance.Tensor(dtype, shape, name="output_gm", scope=tik.scope_gm)
# 定义片内计算
ub_size = 64 * 1024 // (2 * get_dtype_size(dtype)) # 片上缓存大小
loop = shape[0] // ub_size
with tik_instance.for_range(0, loop) as i:
input_ub = tik_instance.Tensor(dtype, (ub_size,), name="input_ub", scope=tik.scope_ubuf)
output_ub = tik_instance.Tensor(dtype, (ub_size,), name="output_ub", scope=tik.scope_ubuf)
# 数据搬入
tik_instance.data_move(input_ub, input_gm[i*ub_size], 0, 1, ub_size//16, 0, 0)
# 计算:max(x, 0)
tik_instance.vec_max(64, output_ub, input_ub, tik_instance.Scalar(dtype, 0), ub_size//64, 8, 8, 8)
# 数据搬出
tik_instance.data_move(output_gm[i*ub_size], output_ub, 0, 1, ub_size//16, 0, 0)
tik_instance.BuildCCE(kernel_name="custom_relu", inputs=[input_gm], outputs=[output_gm])
return tik_instance四、CANN带来的核心价值
提升开发效率
通过封装底层复杂性,开发者可专注于模型逻辑而非硬件适配。尤其对于从GPU平台迁移的团队,CANN提供了兼容TensorFlow/PyTorch的插件机制,显著降低迁移成本。
# mindspore_ascend_infer.py
import mindspore as ms
from mindspore import Tensor
import numpy as np
# 设置后端为昇腾
ms.set_context(device_target="Ascend")
# 加载已训练模型(自动调用CANN执行)
network = ms.load("resnet50.ckpt")
input_data = Tensor(np.random.randn(1, 3, 224, 224).astype(np.float32))
# 推理(底层由CANN调度NPU执行)
output = network(input_data)
print("Prediction shape:", output.shape)
释放硬件性能
CANN深度结合昇腾芯片的达芬奇架构(Da Vinci Architecture),充分利用其AI Core、Vector Core和Scalar Core的并行计算能力,在ResNet50、BERT等基准模型上实现接近理论峰值的利用率。
支持全场景部署
无论是手机端的Ascend Lite芯片,还是数据中心的Ascend Max集群,CANN均提供统一的编程接口和运行时环境,真正实现“一次开发,多端部署”。
五、CANN与其他AI软件栈的对比
组件 华为CANN NVIDIA CUDA/cuDNN Google XLA/TPU Tools 定位 芯片使能层 GPU驱动与加速库 编译优化层 硬件绑定 昇腾AI芯片 NVIDIA GPU TPU 框架支持 MindSpore/TensorFlow/PyTorch 主要支持CUDA生态框架 TensorFlow/JAX 自主可控性 完全国产自研 依赖国外厂商 依赖Google生态 通过对比可见,CANN在国产化替代和全栈自主可控方面展现出显著的战略价值。
六、如何系统学习CANN?
对于希望深入昇腾AI开发的工程师,推荐以下学习路径:
-
基础认知:
- 掌握昇腾AI全栈架构
- 建议参考华为官方入门课程
-
环境搭建:
- 安装CANN SDK
- 配置AscendCL开发环境
-
接口实践:
- 使用AscendCL编写基础程序
- 重点练习内存管理与算子调用
-
框架集成:
- 在MindSpore/TensorFlow中集成CANN后端
- 实现框架与昇腾硬件的协同工作
-
高级开发:
- 学习TBE算子开发
- 参与实际模型性能优化项目
七、学习路径总结
生态的"中枢神经系统",标志着国产AI基础设施已步入成熟阶段。它不仅解决了AI应用"能否运行"的基础问题,更致力于优化"运行效率"和"开发便捷性"等核心痛点。随着大模型和边缘计算的快速发展,CANN的战略价值将日益凸显。
掌握技术,不仅意味着熟练使用AI芯片,更代表着参与构建自主可控、高效开放的中国AI技术体系。
下一篇文章将深入讲解 AscendCL 接口的设计原理与实战用法,敬请期待。
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)