仓颉白皮书——仓颉语言的轻量化线程模型与无锁并发对象
·
目录
一、轻量化线程模型:让并发编程更简单高效
在编程中,并发指同时处理多个任务(如同时下载多个文件)。传统线程模型(如操作系统线程)开销大,而仓颉的轻量化线程模型像 “轻量级工人”,能高效处理大量并发任务。
1. 什么是用户态线程?
- 用户态线程:由编程语言 runtime(运行时)管理的线程,无需操作系统介入。
- 对比传统线程(内核线程):
- 操作系统线程:由内核管理,创建慢(耗时百微秒)、内存占用大(MB 级)。
- 仓颉线程:由语言 runtime 管理,创建快(700ns)、内存占用小(8KB)。
- 对比传统线程(内核线程):
2. 开发态:无需复杂语法的并发编程
- 传统用户态线程的问题:
需要async/await标记异步函数,导致 “函数染色”(一个await会 “传染” 整个函数链)。// 传统语言(如 Python)的异步代码 async def fetch_data(url): // 必须用 async 标记 response = await http_get(url) // 必须用 await 等待 return process(response) - 仓颉的优势:
用spawn关键字直接创建线程,无需标记函数,像写单线程代码一样简单。func fetch_data(url: String) { let response = http_get(url) // 普通函数,无需 async process(response) } main() { let urls = ["url1", "url2"] let futures = ArrayList<Future<Unit>>() for url in urls { let fut = spawn { fetch_data(url) } // 直接创建线程 futures.append(fut) } for fut in futures { fut.get() // 等待所有线程完成 } }
3. 运行态:高性能的线程管理
- 创建速度:
仓颉线程创建平均耗时 700 纳秒(1 秒 = 10 亿纳秒),比操作系统线程快数百倍。 - 内存占用:
每个仓颉线程仅占 8KB 内存,可同时创建 十万级线程(传统线程仅能创建数千个)。 - 上下文切换:
线程切换在用户空间完成,避免内核态与用户态的切换开销(传统线程切换需经过内核,耗时高)。
4. 适用场景
- I/O 密集型任务:如网络请求、文件读写(线程大部分时间在等待 I/O,需大量线程并发处理)。
- 高并发服务:如 Web 服务器同时处理 thousands 请求。
- 计算密集型任务:配合多核 CPU,充分利用硬件资源。
二、无锁并发对象:安全高效的共享内存访问
在多线程场景下,多个线程访问同一内存可能引发 “数据竞争”(类似多人同时修改同一文档导致内容混乱)。仓颉通过无锁并发对象解决该问题,让开发者像写单线程代码一样安全。
1. 传统锁的问题
- 粗粒度锁:用一把锁保护整个数据结构,导致线程竞争激烈(如多个线程访问哈希表不同键时仍需排队)。
- 复杂度高:手动管理锁易遗漏(如忘记释放锁),导致死锁或性能低下。
2. 仓颉的解决方案:无锁并发对象
-
核心思想:
- 用细粒度锁(如为哈希表每个桶加锁)或无锁算法(如 CAS)实现并发安全。
- 开发者通过接口操作数据,无需手动加锁,由语言保证线程安全。
-
原子类型:
对整数、布尔、引用的操作具有原子性(操作不可被打断)。let counter = AtomicInt32(0) spawn { counter.increment() } // 原子自增 spawn { counter.decrement() } // 原子自减 -
并发数据结构:
类型 作用 示例方法 ConcurrentHashMap线程安全的哈希表 put(key, value),get(key)BlockingQueue线程安全的阻塞队列 enqueue(),dequeue()AtomicReference原子引用(可存储对象引用) compareAndSet(old, new)
3. 并发安全与性能优势
-
3. 并发安全与性能优势
安全保障:
所有并发对象的核心方法都是原子性的,避免数据竞争。
// 并发场景下安全的计数器
let counter = AtomicInt32(0)
for _ in 0..<1000 {
spawn { counter.increment() } // 无论多少线程,最终结果一定是 1000
}
性能对比:
-
并发哈希表:细粒度锁 vs. 粗粒度锁(黄色:仓颉
ConcurrentHashMap,蓝色:粗粒度锁哈希表,线程数越多优势越明显)
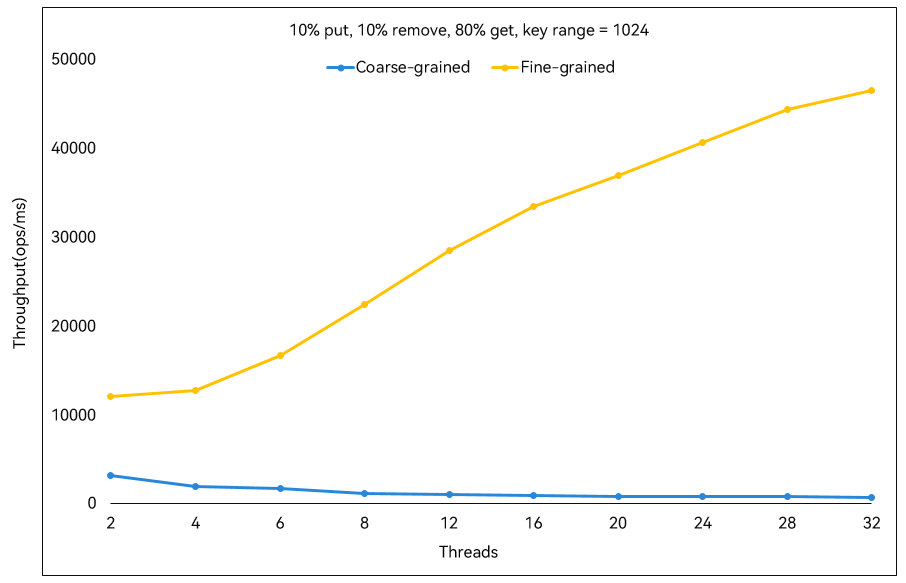
-
并发队列:在单生产者 - 单消费者场景下,性能是粗粒度锁队列的数倍。
4. 如何使用并发对象?
// 示例:多线程安全的日志队列
let logQueue = BlockingQueue<String>()
// 生产者线程:添加日志
spawn {
for i in 0..<100 {
logQueue.enqueue("Log entry \(i)")
}
}
// 消费者线程:处理日志
spawn {
while true {
let log = logQueue.dequeue() // 阻塞等待新日志
processLog(log)
}
}
三、关键对比表:传统模型 vs. 仓颉
| 特性 | 传统模型 | 仓颉 | 优势 |
|---|---|---|---|
| 线程创建开销 | 百微秒级(内核线程) | 700 纳秒(用户态线程) | 可创建十万级线程 |
| 并发编程复杂度 | 需要 async/await 标记 |
直接用 spawn,无需语法约束 |
代码更简洁,避免 “函数染色” |
| 共享内存安全 | 手动加锁,易出错 | 内置并发对象,自动保证原子性 | 减少 90% 并发 Bug |
| 细粒度并发控制 | 需手动实现 | 内置支持(如 ConcurrentHashMap) |
性能提升数倍 |
四、初学者实践建议
-
优先使用轻量化线程:
for url in urls { spawn { fetchAndProcess(url) } // 每个请求一个线程,简单高效 }- 用
spawn创建线程,处理 I/O 密集型任务(如网络请求、文件操作)。
- 用
-
避免共享内存:
- 优先使用值类型(
struct)传递数据,减少线程间共享状态。
struct Task {
let data: String
}
let task = Task(data: "work")
spawn { process(task) } // 传递副本,无共享问题
-
必要时使用并发对象:
- 必须共享数据时,用
AtomicInt、ConcurrentHashMap等内置类型。
// 多线程统计单词频率
let map = ConcurrentHashMap<String, Int>()
spawn {
map.put("apple", map.get("apple") ?? 0 + 1) // 线程安全的插入
}
-
避免过度并发:
- 线程数并非越多越好,根据硬件核心数调整(如 CPU 有 8 核,建议线程数不超过 100)。
五、常见错误与解决
| 错误信息 | 原因 | 解决方法 |
|---|---|---|
Thread creation failed |
线程数超过系统限制 | 减少线程数或增大内存 |
Data race detected |
未使用并发对象,直接共享可变数据 | 用 AtomicReference 或 ConcurrentHashMap |
BlockingQueue full |
生产者速度超过消费者 | 调整生产 / 消费逻辑,或增大队列容量 |
ConcurrentHashMap key not found |
多线程操作顺序问题 | 确保操作原子性,或使用 putIfAbsent |
总结
- 轻量化线程模型:通过用户态线程实现高并发,创建快、开销小,代码简单易写。
- 无锁并发对象:内置原子类型和线程安全数据结构,自动解决数据竞争,性能优于传统锁机制。

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐


 15
15 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)