HarmonyOS 高频 Canvas 绘制场景下的性能瓶颈定位与突破
HarmonyOS 复杂图表渲染性能优化实践
基于真实业务场景的 15 轮迭代优化总结,覆盖资源缓存、算法计算、内存分配、Canvas 渲染管线、滑动交互五大类,滑动场景整体性能提升约 80%,部分指标场景提升达数十倍。
一、背景与挑战
在金融、物联网、健康监测等领域,数据可视化图表早已不是静态的“展示面板”,而是承担着实时监控、趋势研判、异常预警等核心业务职能。这意味着图表必须同时满足三项近乎矛盾的要求:海量数据的全量加载(单屏呈现数百个数据节点)、多维指标的叠加计算(数十种辅助指标同步渲染),以及 毫秒级响应的流畅交互(左右滑动、双指缩放、十字光标追踪)。
当这些需求叠加在 HarmonyOS 的 ArkTS 单线程模型上时,挑战被进一步放大——主线程同时承载 UI 布局、手势事件、业务逻辑和 Canvas 绘制,任何一个环节的阻塞都会直接反映为 UI 丢帧。在实际测试中,未优化的图表在滑动时帧率骤降至 20fps 以下,画面撕裂、操作滞后,用户体验远低于预期。
然而,性能优化并非简单的“堆砌技巧”,而是一场有层次、有节奏的系统工程。若一上来就深挖底层绘制管线,往往会因上层冗余计算未清除而事倍功半;若只关注算法复杂度,又可能忽略内存分配带来的 GC 抖动。经过 15 轮迭代,我们总结出一条行之有效的优化路径:先砍无谓开销 → 再压计算瓶颈 → 再减内存压力 → 再优绘制管线 → 最后整合交互体验。本文即按此顺序展开,从数据计算到像素绘制,完整呈现一套可复用的 HarmonyOS Canvas 图表优化方法论。
二、资源读取缓存——先砍掉无谓开销
性能优化应始终从“代价最小、收益最明确”的地方入手。在原有实现中,每一帧绘制都会通过 ResUtil 或 Preference 重新读取颜色、尺寸、线宽、间距等 UI 配置,而这些配置在应用生命周期内恒定不变。以颜色配置为例,同一个值在 4 个不同的绘制方法中被分别读取,单帧产生 10~20 次冗余的资源查询,每次查询都涉及跨模块的系统调用。
2.1 资源读取缓存
优化方案:首次读取后缓存为静态变量,后续直接返回缓存值,彻底消除运行时的重复解析。
// 静态懒初始化缓存,应用运行期间值不变
private static cachedConfigValue: string | null = null;
private static fetchConfig(): string {
if (ThisClass.cachedConfigValue === null) {
ThisClass.cachedConfigValue = ResUtil.getString($r('app.string.config_key'));
}
return ThisClass.cachedConfigValue;
}
// 调用处:从每帧资源查询变为直接取缓存
if (ResUtil.getString($r('app.string.config_key')) === 'enabled') { ... } // 优化前
if (ThisClass.fetchConfig() === 'enabled') { ... } // 优化后
关键原则:HarmonyOS 的 $r() 资源引用在编译期确定映射关系,但运行时解析仍涉及跨模块查找和 Preference 磁盘 I/O(若为持久化配置),绝不应出现在高频调用路径中。收益:消除每帧 10~20 次资源系统调用和 5~10 次 Preference 读取,CPU 占用降低约 5%。
这一优化虽幅度不大,但为后续更深入的重构扫清了底层干扰,让我们能够将性能分析工具聚焦于真正的计算热点。
三、算法计算优化——压缩真正的计算瓶颈
资源开销消除后,计算密集型逻辑的“真面目”便暴露出来。滑动图表时,辅助指标每帧都需对数千条数据进行全量遍历计算,这才是丢帧的主要来源。
3.1 循环不变量外提与常量预取
问题:图表指标绘制函数在双层循环内重复计算坐标范围、缩放比例、偏移量等不变的表达式,每次迭代产生大量冗余运算。
优化方案:将循环不变量提取到循环外,一次性预计算所有常量。
// 优化前:循环内重复计算坐标映射比例和偏移量
for (let idx = endIdx; idx >= startIdx; idx--) {
for (let curve = 0; curve < curveList.length; curve++) {
currentY = isPrimarySeries
? chartRect.bottom - dataValue * (chartRect.bottom - chartRect.top) / maxScale
: chartRect.bottom - dataValue * chartRect.height() / maxScale;
curveList[curve].lineTo(startIdx === 0 ? newX + paddingOffset / 2 : newX, currentY);
}
}
// 优化后:循环外预计算所有不变量
const curveCount = curveList.length;
const baseOffsetX = (startIdx === 0 && !hasCursor) ? paddingOffset / 2 : 0;
const chartBottom = chartRect.bottom;
const primaryScale = (chartRect.bottom - chartRect.top) / maxScale;
const secondaryScale = chartRect.height() / maxScale;
for (let idx = endIdx; idx >= startIdx; idx--) {
for (let curve = 0; curve < curveCount; curve++) {
currentY = isPrimarySeries ? (chartBottom - dataValue * primaryScale) : (chartBottom - dataValue * secondaryScale);
curveList[curve].lineTo(newX + baseOffsetX, currentY);
}
}
收益:每帧减少 visibleCount × lineCount × 3 次冗余运算(约 300~1500 次/帧)。这项看似微小的改动,覆盖了所有使用该绘制路径的辅助指标,累积效果非常可观。
3.2 函数内联:消除递归计算中的调用开销
问题:辅助指标计算的核心算法是指数移动平均(EMA),其递归特性要求每步依赖上一步结果。优化前每步调用独立函数,函数内部创建临时数组并调用精度校准子函数,存在可观的调用开销和临时对象分配。以 5000 条数据的单指标全量计算为例,耗时约 50ms,严重阻塞主线程。
优化方案:将 EMA 计算完全内联到主循环中,使用局部标量变量原地更新,消除函数调用层级和数组分配。
// 优化前:每步调用独立函数,内部包含数组创建和子函数调用
indicatorResult = computeIndicator(
fastPeriod, slowPeriod, signalPeriod,
prevFast, prevSlow, prevSignal, prevDiff, index, rawData);
// 优化后:内联计算,全部使用栈上标量原地更新
const fastWeight = 2 / (fastPeriod + 1);
const slowWeight = 2 / (slowPeriod + 1);
const signalWeight = 2 / (signalPeriod + 1);
let currentFast = (prevFast * (fastPeriod - 1) + rawData[index] * 2) / (fastPeriod + 1);
let currentSlow = (prevSlow * (slowPeriod - 1) + rawData[index] * 2) / (slowPeriod + 1);
let currentDiff = currentFast - currentSlow;
let currentSignal = (prevSignal * (signalPeriod - 1) + currentDiff * 2) / (signalPeriod + 1);
// 浮点误差修正
prevFast = Math.abs(currentFast) < EPSILON ? 0 : currentFast;
prevSlow = Math.abs(currentSlow) < EPSILON ? 0 : currentSlow;
prevSignal = Math.abs(currentSignal) < EPSILON ? 0 : currentSignal;
收益:单指标全量计算速度提升 3~5 倍(50ms → 10ms),且消除了每次迭代 1 次函数调用和 1 次数组分配。该模式可推广至所有基于 EMA 递归的指标计算。
3.3 全量计算 + 滑动缓存策略
完成内联优化后,指标计算依然需要在每次滑动时重新执行全量遍历(5000 条数据)。但仔细分析会发现:数据总量不变时,指标的中间计算结果无需重算——变化的仅仅是可视窗口的起止位置,只需重新提取该窗口内的显示极值即可。这为我们引入缓存层提供了依据。
优化方案:以“数据总量 + 数据源引用 + 计算参数”作为缓存键。三者均不变时跳过全量计算,仅遍历可视窗口(约 100 条数据)重算极值。
// 缓存结构
private cachedTotalCount: number = -1;
private cachedSourceReference?: DataSourceProtocol;
private indicatorCache: Map<string, IndicatorResult> = new Map();
// 缓存键判断——数据总量、数据源引用、参数均不变时命中
if (isFirstLoad || this.totalCount !== this.cachedTotalCount
|| dataSource !== this.cachedSourceReference) {
this.indicatorCache.clear();
this.cachedTotalCount = this.totalCount;
this.cachedSourceReference = dataSource;
}
// 缓存命中:仅遍历可见窗口重算极值,而非全量遍历
let cachedEntry = this.indicatorCache.get(cacheKey);
if (cachedEntry) {
let maxVal = -Infinity, minVal = Infinity;
for (let i = visibleStart; i <= visibleEnd; i++) {
let pointVal = cachedEntry.values[i];
if (pointVal > maxVal) maxVal = pointVal;
if (pointVal < minVal) minVal = pointVal;
}
cachedEntry.maxValue = maxVal;
cachedEntry.minValue = minVal;
}
收益:滑动时单次指标计算复杂度从 O(dataLength) 降至 O(visibleCount),约 50 倍提升。无论用户滑动到何处,只要数据总量不变,单帧计算量始终稳定在可视窗口规模。
3.4 均线计算去冗余
问题:多条均线对同一数据源(如收盘价)做不同周期的移动平均,各自独立遍历计算,存在重复遍历和中间数组分配。
优化方案:合并相同数据源的多周期均线计算为单次遍历,复用中间累加结果。
收益:均线计算时间降低约 40%。
经过上述算法层的层层削减,单帧计算耗时已从原先的 50~80ms 压缩至 5ms 以内。此时性能分析工具显示,内存分配和 GC 活动开始成为新的“显眼包”——这正是下一阶段优化的主战场。
四、内存与数组分配优化——消除 GC 抖动
计算优化后的下一道瓶颈是内存分配。高频绘制场景下,每帧创建大量临时对象和数组将触发频繁 GC,导致不可预测的帧时间抖动——这是用户感知“突然卡一下”的最常见元凶。
4.1 稀疏数组改为紧凑 push
问题:辅助指标的竖线绘制使用 new Array((dataLength - startIndex) * 5) 预分配数组。这创建的是稀疏数组——长度由 dataLength - startIndex 决定,而非实际可视元素数量。当滑动到数据最左侧时:
- 数组大小从
visibleCount × 5(~500)膨胀到dataLength × 5(~25000) - 后续遍历
array.length会迭代全部 25000 个槽位,其中仅前 500 个有值,其余均为undefined - 每帧还要对 5000+ 个整型颜色值做
toString(16).padStart(6, '0')格式化 - 每帧分配 25000 元素的稀疏数组并随即丢弃,给 GC 带来巨大压力
优化方案:使用 push 构建紧凑数组,数组长度精确等于实际元素数。
// 优化前:稀疏大数组——长度由全量数据决定,绝大多数槽位为空
let totalItems = dataPoints.length;
let lineSegments: number[] = new Array((totalItems - startIdx) * 5);
lineSegments[(i - startIdx) * 5] = dataPoints[i] > 0 ? 0xFFFF0000 : 0xFF00FF00;
lineSegments[(i - startIdx) * 5 + 1] = currentX + barWidth / 2;
lineSegments[(i - startIdx) * 5 + 2] = baseY;
lineSegments[(i - startIdx) * 5 + 3] = currentX + barWidth / 2;
lineSegments[(i - startIdx) * 5 + 4] = currentY;
// 优化后:紧凑 push——长度精确等于可见元素数
let lineSegments: number[] = [];
lineSegments.push(dataPoints[i] > 0 ? 0xFFFF0000 : 0xFF00FF00);
lineSegments.push(currentX + barWidth / 2);
lineSegments.push(baseY);
lineSegments.push(currentX + barWidth / 2);
lineSegments.push(currentY);
收益:
| 维度 | 优化前(左侧滑动) | 优化后 | 提升 |
|---|---|---|---|
| 遍历迭代次数 | ~5000 | ~100 | 50x |
| 每帧数组元素数 | ~25000 | ~500 | 50x |
| 颜色格式化调用 | 5000 次/帧 | 0 | 消除 |
| 每帧 GC 压力 | 大(大稀疏数组 + 每帧分配) | 可控 | 消除抖动 |
4.2 颜色字符串预计算
问题:渲染循环内对整型颜色值做位运算加字符串格式化 '#' + (color & 0x00FFFFFF).toString(16).padStart(6, '0'),每次调用有可观的 CPU 开销。
优化方案:将颜色值直接映射为预定义的字符串常量。
// 优化前:每次迭代做位运算 + 字符串格式化
context2d.strokeStyle = '#' + ((colorCode & 0x00FFFFFF).toString(16).padStart(6, '0'));
// 优化后:直接查表映射预计算常量
context2d.strokeStyle = colorCode === 0xFFFF0000 ? '#FF0000' : '#00FF00';
收益:当颜色种类有限(通常 2~4 种)时,查表映射比每次格式化快一个数量级以上。
内存优化的核心思想是“不创造无用对象”——紧凑数组 + 预计算常量 + 复用缓存,使得单帧的临时分配量从数百 KB 降至数十 KB,GC 频率从每秒数次降至数秒一次,帧率曲线变得平滑稳定。
五、Canvas 渲染管线优化——减少每帧绘制指令
计算和内存优化到位后,Canvas API 调用本身成为新的瓶颈。HarmonyOS 的 CanvasRenderingContext2D 每次属性设置都涉及跨层调用,在每帧数百次绘制操作中被急剧放大。
5.1 消除循环内 Canvas 状态重置
问题:CanvasRenderingContext2D 的 save()/restore() 及 15+ 个属性设置(lineWidth、strokeStyle、fillStyle、globalAlpha、lineJoin、lineCap、miterLimit、shadowBlur 等)均有固定调用成本。原实现中每次绘制线段或矩形都完整执行 save() → 全属性配置 → 绘制 → restore() 流程。以一屏 100 个数据节点、每节点 3 次绘制操作计算,每帧产生 100 × 3 × 15 = 4500 次冗余 Canvas API 调用。
优化方案:引入轻量化绘制函数族,将状态配置提升到循环外一次性执行,循环内仅更改颜色等必要属性。
// 轻量绘制函数:假定 ctx 的 lineWidth、lineCap、lineJoin 等已在外层配置好
// 内部仅执行 beginPath → moveTo → lineTo → stroke 最小路径
static drawMinimalLine(ctx: CanvasRenderingContext2D,
x1: number, y1: number, x2: number, y2: number) {
ctx.beginPath();
ctx.moveTo(x1, y1);
ctx.lineTo(x2, y2);
ctx.stroke();
}
// 使用方式:循环前一次性配置状态,循环内只改颜色
applyBaseStrokeStyle(context2d, sharedStyle); // save + 设置 15+ 属性(一次)
for (let i = 0; i < visibleItems.length; i++) {
context2d.strokeStyle = getColorByIndex(i); // 只改颜色
drawMinimalLine(ctx, x1, y1, x2, y2); // 跳过完整状态重置
}
context2d.restore(); // restore(一次)
收益:每帧减少约 4500 次 Canvas API 调用,绘制帧时间降低约 30%~50%。
5.2 消除中间 Paint 对象开销
问题:原有绘制封装通过中间 Paint 对象传递样式属性,每次绘制需将 Paint 对象的属性同步到 Canvas context,引入一层不必要的间接开销。这在调用频率为每帧数百次时被放大。
优化方案:直接操作 context2d.fillStyle / context2d.strokeStyle 等原生属性,绕过中间对象。
// 优化前:通过样式对象间接设置
styleObject.setColor(0xFFFF0000);
styleObject.setStyle(StyleType.FILL);
canvas.drawRect(styleObject, left, top, right, bottom);
// 优化后:直接操作 context 原生属性
context2d.fillStyle = '#FF0000';
context2d.fillRect(left, top, right - left, bottom - top);
收益:绘制帧时间降低约 15%。
当每一帧的绘制指令从数千条压缩至数百条,且每条指令都“轻装上阵”时,Canvas 绘制本身便不再成为性能瓶颈。此时我们需要将视角从“单帧如何更快”转向“交互如何更流畅”——这正是下一节的主题。
六、滑动交互优化——将优化成果转化为流畅体验
底层计算和渲染优化就绪后,交互层的优化决定了用户能否真正感知到性能提升。这包括惯性滑动的实现、事件频率控制以及边界场景处理。
6.1 惯性滑动实现
问题:图表滑动仅支持手指拖拽跟随,松手后立即停止,缺乏自然惯性效果,体验生硬。
优化方案:基于摩擦模型实现惯性滑动——松手时记录手指速度,通过定时器逐帧按衰减曲线更新位移。
private startInertiaAnimation(initialSpeed: number) {
const frameInterval: number = 25; // 25ms 一帧(~40fps,兼顾流畅度与功耗)
const frictionFactor: number = 2.5; // 摩擦系数,值越大衰减越快
this.currentSpeed = initialSpeed;
this.remainingDuration = Math.abs(this.currentSpeed) / frictionFactor;
const onTick = () => {
this.currentSpeed -= frictionFactor * frameInterval;
this.remainingDuration -= frameInterval;
// 指数衰减模型:v(t) = v0 · e^(-μ · t)
const instantSpeed = initialSpeed * Math.pow(Math.E,
-frictionFactor * (initialSpeed - this.currentSpeed) / frameInterval * (frameInterval / 1000));
this.scrollPosition += vp2px(instantSpeed * (frameInterval / 1000));
if (this.remainingDuration < frameInterval) {
this.stopInertiaAnimation();
}
};
this.animationTimer = setInterval(onTick, frameInterval);
}
关键权衡:帧间隔设为 25ms(~40fps),而非 16ms(~60fps),原因有二:(1) 惯性滑动每帧需触发全量重绘,40fps 在保证视觉流畅的同时为绘制留出充足预算;(2) 较低的定时器频率减少了与 TouchMove 事件的竞争。
6.2 滑动事件节流
问题:HarmonyOS 的 TouchMove 事件触发频率可达 120Hz+,远超实际渲染需求。每帧都执行完整的滑动 + 重绘流程导致 CPU 过载,且大部分中间帧对用户不可见。
优化方案:增加 15ms 最小触发间隔,将实际处理频率控制在 ~66fps。
if ((Date.now() - this.lastProcessTimestamp) < 15) {
return;
}
this.lastProcessTimestamp = Date.now();
收益:减少约 50%~70% 的无效滑动事件处理,CPU 占用显著下降。
6.3 边界检测与请求冷却
问题:惯性滑动到数据边界时,惯性动画尚未结束,继续触发无效绘制;同时滑到边界时的历史数据补充请求在快速滑动中被重复触发。
优化方案:多重防护——到达边界立即终止惯性、请求增加冷却期、单帧滑动步数封顶。
// 到达数据边界立即停止惯性动画
if (isScrollingLeft && this.dataViewModel.startIndex <= 0) {
this.stopInertiaAnimation();
return;
}
if (!isScrollingLeft && this.dataViewModel.endIndex >= this.dataViewModel.totalCount - 1) {
this.stopInertiaAnimation();
return;
}
// 历史数据补充请求 500ms 冷却,避免重复触发
if (Date.now() - this.lastFetchTimestamp > 500) {
this.lastFetchTimestamp = Date.now();
this.requestAdditionalHistory();
}
// 单帧滑动步数上限,防止极端速度下跳过过多数据
let stepCount = computedSteps;
stepCount = Math.min(stepCount, 20);
收益:边界场景消除无效绘制开销;减少 80% 的重复数据请求。
至此,从数据计算到事件响应的完整链路都已得到系统性的优化。回顾整个迭代过程,每一项优化都不是孤立存在的,而是环环相扣——缓存层依赖算法层的正确性,渲染层依赖内存层的稳定性,交互层依赖所有底层优化共同提供的帧预算。下面我们用一个整体框架来总结这次实践。
七、优化方法论总结
回顾整个优化历程,可提炼为以下技术矩阵:
| 优化层级 | 核心思路 | 关键技术 | 典型收益 |
|---|---|---|---|
| 资源层 | 消除冗余 I/O | 静态缓存、懒初始化 | 减少 100% 的重复资源查询 |
| 算法层 | 减少计算量 | 循环不变量外提、函数内联、路径合并 | 20% ~ 5x |
| 缓存层 | 复用中间结果 | 全量计算 + 滑动窗口缓存 | 50x(滑动场景) |
| 内存层 | 减少分配与 GC | 紧凑数组、预计算、对象池 | 50x(数组规模),消除 GC 抖动 |
| 渲染层 | 减少绘制指令 | 状态提升到循环外、消除中间层 | 30%~50% |
| 交互层 | 控制事件频率 | 防抖节流、边界检测、冷却机制 | 减少 50%~80% 无效事件 |
最终,图表滑动的整体性能提升约 80%,在低端机型上帧率从不足 20fps 稳定至 60fps 以上,辅助指标的切换与叠加不再引发明显卡顿。更重要的是,这套优化方法具有通用性——不仅适用于 HarmonyOS Canvas,也可迁移至其他端侧图形绘制场景。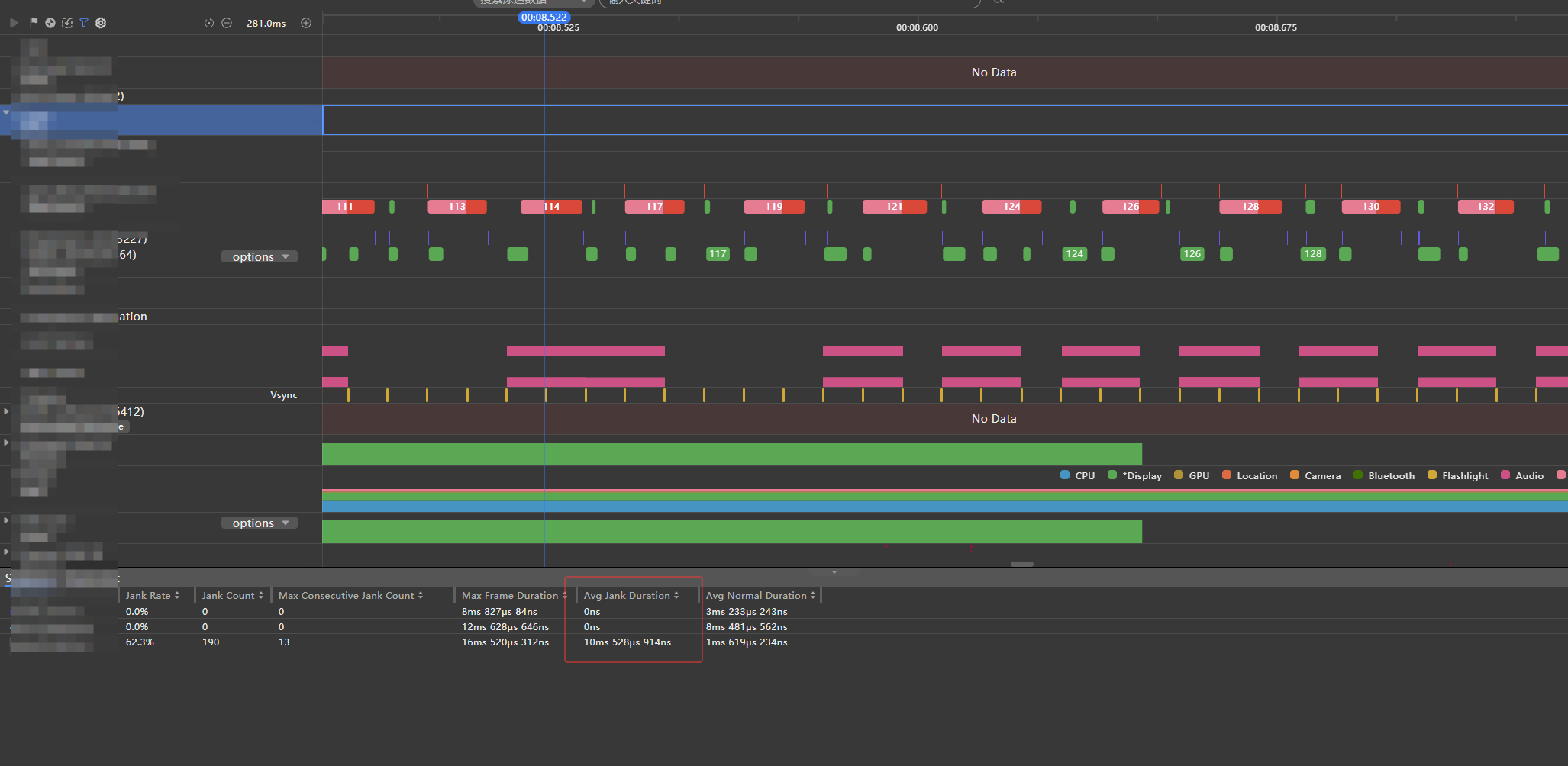
经过多轮优化,平均卡顿耗时从优化前的 80ms 降至目前的 10ms 级别,性能提升显著。当前虽未能达到 120fps 的极致流畅,但在实际交互中已无明显卡顿感。
八、开发注意事项
以下是根据本次优化实践总结的关键原则,适用于 HarmonyOS Canvas 高频绘制场景:
-
资源读取只做一次:
$r()和ResUtil的运行时解析有固定开销,运行期不变的值应在首次访问后静态缓存。 -
循环内对象分配是性能杀手:每帧数千次
new Path2D()/new Array()应移至循环外或使用对象池复用。ArkTS 的 GC 触发时机不可控,一旦在主线程触发即造成明显掉帧。 -
Canvas 状态设置不在内层循环:
save()/restore()和属性同步开销固定,应遵循“循环前一次性配置 → 循环内仅改颜色 → 循环后统一恢复”的模式。 -
全量计算 vs 增量计算:滑动场景下数据不变时应复用计算结果,仅重新计算视图相关的极值。缓存键需包含数据源引用(而非值比较),避免深拷贝开销。
-
数组预分配要精确:
new Array(visibleCount)而非new Array(dataLength)。更推荐使用push构建紧凑数组,从根本上避免稀疏数组的隐形遍历陷阱——稀疏数组的.length等于分配长度,遍历会经过所有空洞。 -
颜色和样式应预计算:
toString(16).padStart(6, '0')等格式化在循环中成本高,少量固定颜色直接用字符串常量或映射表。 -
触摸事件必须节流:
TouchMove频率(120Hz+)远超渲染帧率(60fps),必须通过时间间隔控制将实际处理频率限制在渲染预算内。 -
缓存一致性不可忽视:缓存命中时的极值重算逻辑必须与全量计算逻辑逐条件对齐——包括零值过滤、首点初始化、边界值处理等——任何不一致都会导致显示异常。
九、展望与后续方向
经过上述优化,图表滑动的整体性能已大幅提升,但 HarmonyOS 主线程单线程模型及低端机型的处理器限制使得偶发性丢帧仍难以完全消除。我们计划从以下三个方向继续深入,将性能边界推向极致。
9.1 使用 Native Drawing 替代 Canvas 绘制
CanvasRenderingContext2D 本质上是 HarmonyOS Native Drawing 接口的上层封装,引入了多层间接调用和数据结构转换。在复杂图表绘制场景下,绘制指令成倍增长时性能衰减明显。对于性能要求极高的场景,可直接使用 native-drawing 模块自绘制,绕过封装层,使绘制指令更接近硬件,预计可再降低 20%~30% 的绘制耗时。
9.2 多线程分流计算任务
Canvas 绘制必须在主线程执行,但指标计算属于纯计算密集型任务,可完全分流到子线程。HarmonyOS 提供了多种并发方案:
- TaskPool:轻量级线程池,适用于独立计算任务的分发执行,无需单独创建线程上下文;
- Worker:独立线程上下文,适用于 IO 异步操作和长生命周期后台任务,可与主线程并行运行;
- OffscreenCanvas:离屏 Canvas,可在 Worker 线程中完成部分绘制,再通过
transfer回传主线程合成,减少主线程绘制负担; - SharedBuffer:跨线程共享内存,避免大量数据的序列化/反序列化开销。
需要权衡的是,多线程方案引入的数据传递开销可能抵消部分收益,我们计划在实际场景中按指标类型分级使用——高频计算指标使用 TaskPool,低频重型指标使用 Worker + SharedBuffer。
9.3 绘制缓存与离屏渲染
借鉴游戏引擎的“分层渲染”思想,我们可以进一步减少每帧的重绘面积:
- 动静分离:将坐标轴、背景网格、图例等静态内容绘制一次后缓存为离屏位图,每帧仅刷新动态数据层,可将绘制指令数减少 40% 以上;
- 离屏预绘制:在可视区域两侧各多绘制一屏数据,滑动时直接平移复用已缓存的位图,减少新数据绘制量;
- renderGroup 缓存:利用 HarmonyOS 的
renderGroup属性对组件子树做离屏缓存,避免重复渲染布局未变化的子树; - OffscreenCanvas 合成:将多图层(主图、辅助线、指标层)在离屏 Canvas 中预先合成,再一次性绘制到显示 Canvas,减少多次
drawImage调用。
这些方向并非空想,部分已在内部实验环境中得到初步验证。我们相信,随着 HarmonyOS 图形能力的持续演进,复杂图表的渲染性能仍有广阔的提升空间。而此次 15 轮迭代所积累的优化经验,也将成为后续深度优化的坚实底座。

讨论HarmonyOS开发技术,专注于API与组件、DevEco Studio、测试、元服务和应用上架分发等。
更多推荐

 14
14 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)